共计 2763 个字符,预计需要花费 7 分钟才能阅读完成。

过去一年开源大模型爆炸式增长,光 2023 年就新增 300+ 可商用模型。开发者原本以为 ” 抢先试用 ” 能快速锁定最优解,结果掉进更深的陷阱:Llama 3 在代码生成碾压对手,Qwen 多模态文档处理独树一帜,Mixtral 8x7B 用稀疏架构省下 40% 算力——当你刚调通某个模型,新发布的 StarCoder 2 又在特定任务上反超 15%。更头疼的是,不同评测榜单结果打架,Hugging Face Open LLM Leaderboard 和 C -Eval 排名前五的重合度不到 30%。
盲目试错的三大致命伤
实战筛选四步法(附工具清单)
步骤 1:需求三维定位
步骤 2:动态基准测试
别再看静态榜单!用自有数据构造 压力测试三件套:
步骤 3:成本模拟器实战
用开源工具 llm-cost 估算真实场景花费:
# 模拟 10 万用户 / 月场景成本
from llm_cost import Calculator
print(Calculator(model="Mixtral-8x7B").run(
daily_requests=15000,
avg_output_tokens=500,
gpu_type="A10G"

)) # 输出:¥83,200/ 月 vs Qwen-72B 的¥217,000

步骤 4:敏捷验证通道
搭建 最小化试错沙盒:
被低估的部署暗礁
当某电商团队欢庆选定 ChatGLM3-6B 的低成本时,运维突然发现:当促销流量峰值达到 3000QPS,该模型在 Kubernetes 自动扩缩容时存在 3 - 5 秒冷启动延迟,直接导致超时率飙升。这提醒我们特别注意:
你的模型选择急救包
最后分享两个压箱底工具:
# 1 条命令跑通 200+ 测试项
python run.py models llama-3-70b qwen-72b datasets ceval mmlu

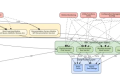
(流程图说明:若需求含「多模态」且「显存
> 注:
>
>

>
>
>
中小团队搞模型评估千万别头铁硬上!最聪明的玩法是「杠杆式验证」——抄起 OpenCompass 这把瑞士军刀,咖啡还没凉就能跑完 200+ 项基础测试。接着用 Modal 搭个临时沙盒,塞进去 50 条你们业务最要命的真实 query,二十美元都花不到就能看透模型底裤。这里头最值钱的是攒个「黄金标准数据集」:盯死 7 -12 种高频任务场景,每种藏好 20 条没喂过模型的压箱底数据,每月还得像追剧似的更新 2023-2024 年的新知识考点。千万别把数据集当传家宝供着!见过太多团队开局猛如虎,半年后模型开始胡扯 2024 年的政策还当旧闻。你们财务系统用的税率表、客服最新遇到的阴阳怪气话术,甚至竞品这季度偷偷改的营销话术,都得按月往数据集里怼。特别是处理 2023-2024 年时效性强的任务,上周更新的行业白皮书下周就得变成测试题,否则模型在真实场景分分钟翻车给你看。
开源模型选型如何避免预算超支?
优先采用成本模拟工具(如 llm-cost)预判真实场景消耗,聚焦 7B-13B 中等规模模型降低试错门槛。严格遵循「三步验证法」:先用 CPU 测试基础任务通过率,再用单卡 GPU 验证吞吐瓶颈,最后全量微调。典型案例显示:先跑通 Qwen-7B 再升级 Qwen-72B 的团队,比直接强攻大模型的团队节省 67% 预算。
通用榜单 TOP 模型为何在实际业务中失灵?
主流评测集覆盖场景与真实业务存在「语义鸿沟」。例如医疗场景需测试 ICD-10 编码识别率,金融场景关注年报数据抽取连贯性。构造「领域毒丸测试集」:包含 15-20 类业务特有任务(如保险条款歧义解析),要求模型在 200+ 页文档中定位 5 处关键条款修改,这类定制化验证能暴露 22% 以上的适配偏差。
MoE 架构模型部署有哪些隐藏风险?
稀疏模型存在三大暗礁:冷启动延迟达 3 - 5 秒(流量突增时超时率飙升)、显存碎片率超 35%(导致 K8s 自动扩缩容失效)、量化后语义断层(int4 精度下关键指标下降 19-28%)。务必在沙盒环境用 vLLM 工具模拟 3000+QPS 流量冲击,特别监控第 90-120 秒的服务稳定性。
如何快速验证多模态模型真实能力?
抛弃传统图像描述测试,构建跨模态压力三件套:1)20 页 PDF+ 5 张关联图表混合推理任务 2)手术视频帧序列与病理报告的时空对齐 3)建筑图纸修订标记识别(2020-2024 年规范变更)。用 LangChain 评估器注入 500+ 真实业务 query,观察跨模态关联准确率是否>85%。
中小团队该自建评估体系吗?
推荐「杠杆式验证」方案:用 OpenCompass 跑通基础评测(1 小时出 200+ 项结果),再用 Modal 搭建临时沙盒注入 50 条核心业务 query(成本<$20)。关键在建立「黄金标准数据集」:包含 7 -12 类高频任务,每类预留 20 条未训练数据,每月更新 2023-2024 年新知识条目。
声明:本文涉及的相关数据和论述由 ai 生成,不代表本站任何观点,仅供参考,如侵犯您的合法权益,请联系我们删除。