共计 2065 个字符,预计需要花费 6 分钟才能阅读完成。
许多朋友可能已经接触过文生图这一类的技术,如 MidJourney、Stable Diffusion 和 OpenAI 的 DALL·E 等。只需输入简单的文字,就能生成高质量的图像,这无疑给很多平面设计师带来了不小的压力。接下来,我们将深入分析这些模型的运作机制。虽然初看似乎很复杂,但其实其基本原理是相当简单易懂的。
大多数主流的文生图模型采用了被称为“扩散”(Diffusion)的技术。这一概念起源于物理学,可以用以下方式来理解:想象一下,一杯清水,若有一滴墨水落入其中,墨水会逐渐与水混合,最终使整杯水的颜色发生变化。在这个过程中,墨水分子与水分子均匀交融,这正是扩散现象的体现。文生图模型的核心理念正是基于这一扩散过程。

以一张小猫的图片为例。我们可以通过向这张图片中添加随机像素(噪声),使其变得模糊。当噪声增多时,图像的细节将逐步消失,最终呈现出一种类似于电视信号不良时的雪花状效果。这样的完全随机的像素分布被称为“白噪声”。
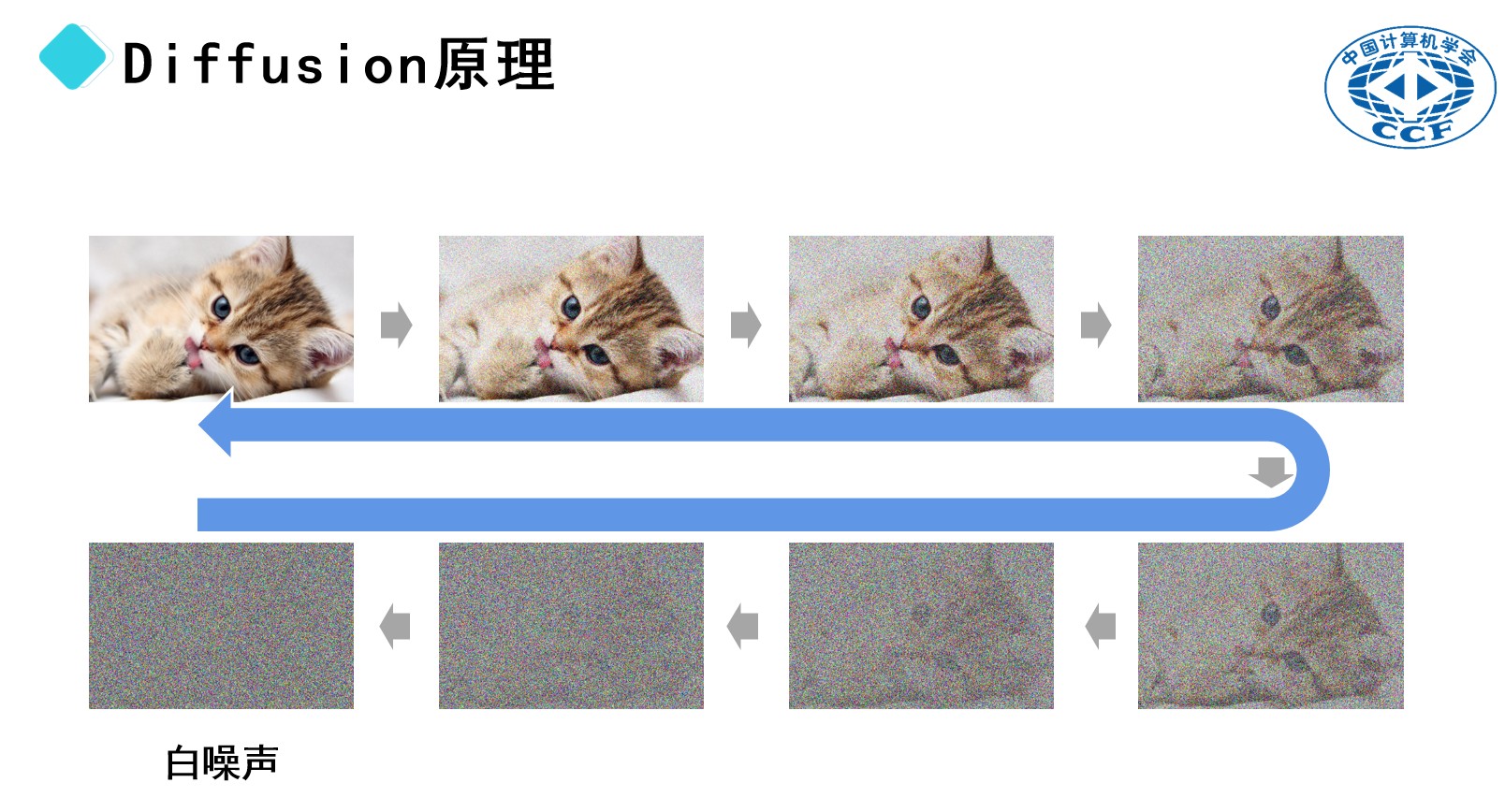
假设这个过程是可逆的,我们可以从白噪声开始,逐步去除噪声,使模糊的画面逐渐恢复清晰。在这一过程中,隐藏在白噪声中的图像会逐步显现,仿佛小猫的轮廓慢慢浮现。因此,文生图模型的扩散过程本质上是一种逆向操作,称为“去噪”。
然而,我们还需思考一个问题:如何将文本信息融入到这个过程中呢?接下来的内容将为您揭晓答案。
回到刚才提到的去噪过程。假设我们要训练一个大型模型,可以称之为“图像生成器”。这个模型的作用是从噪声图像中去除噪声,从而生成清晰明了的图像。具体而言,模型中的蓝色部分负责实现从含噪图像到清晰图像的转变。

探索文本生成图像的奥秘与潜力
这一切仅仅是一个起点。为了让模型能够根据文字描述创造出相应的图像,我们必须赋予它解析文本的能力。因此,另一个专门的模型将应运而生。该模型将通过海量带有标注的图像进行训练,每个图像都有一段对应的描述文字。
举个例子,当我们拥有一张描绘“小狗在草地上奔跑”的图片时,它会配上相关的文字描述。通过这样的训练,模型能够掌握文本与图像之间的深层联系。
换句话说,当模型接收到像“一只躺着的猫”这样的文本指令时,它会在内部生成与之对应的图像,而不会生成与之无关的画面,比如“在草地上奔跑的小狗”。
最终,构建而成的“文本转图像”模型由多个子模型组成。首先,模型需要具备理解文本的能力,然后,它会接收一幅初步的含噪图像作为创作的“画布”。随后,模型内的“去噪”部分也就是图像生成器,将依据文本内容逐步消除噪声。最后,图像解码器会将生成的图像数据转化为可视化的图像。
通过这种机制,模型能够依据所提供的文字描述生成相应的图像,无论是宁静的山水画还是可爱的小猫。这一过程就像在一幅充满随机噪声的画布上,根据特定的文字描述逐步去除噪声,最终展现出清晰的画面。
同样,这一原理也可以扩展到视频生成领域。视频本质上是由一系列连续的静态图像构成,快速播放时会产生动态的效果。因此,生成视频的过程可以比作连续生成多个静态图像并将它们组合成一个流畅的画面。在这一过程中,同样会运用到扩散技术。
几个月前,SORA大模型的问世引发了讨论,有人认为SORA已经具备了对物理世界的理解,通用人工智能(AGI)将在短短一两年内实现。这一观点常常由一些知名人士或舆论领袖提出。然而,面对这样的说法,我们应当保持理性,谨慎运用批判性思维进行深入分析。
婴儿如何迅速掌握物理知识的奥秘
让我们探讨一下婴儿是如何在短短几个月内逐渐理解物理法则的。出生之时,婴儿犹如一张空白的画布,但当他们成长到八九个月大的时候,便能掌握基本的物理规则。例如,当他们观察到某个物体凭空悬浮而不受重力影响时,常常会流露出惊讶的表情,这表明他们已经领悟到物体不应无故悬浮的基本概念。
人类之所以能够在这么短的时间内迅速掌握这些知识,主要归功于我们丰富的感官系统,包括视觉、听觉、嗅觉、触觉和味觉。通过这些感官的共同作用,我们能够全面感知周围的环境。例如,当婴儿触碰到一个装满热水的杯子时,他们不仅能够看到杯子本身,还能感受到水的温度,并在感到烫手时迅速缩回手。当杯子掉落并摔碎时,他们听到的声音和看到的碎片飞散的情景,都会给他们带来深刻的感官体验。这些体验助力大脑的发展,使他们更好地理解物理世界。
与此形成鲜明对比的是,现有的SORA大模型主要依赖大量的视频数据进行训练。这些模型仅能够接收视觉信息,而缺少嗅觉、触觉和味觉等其他感官的输入。如果我们把这些模型与婴儿进行比较,可以想象,如果一个婴儿被限制在一个透明的箱子里,只能借助视觉去观察世界,而无法利用其他感官,那么他将很难全面发展自己的理解能力。因此,基于目前的技术水平,期待这些模型能够像人类一样全面理解物理世界显然是不现实的。