
共计 1203 个字符,预计需要花费 4 分钟才能阅读完成。
谷歌推出的 LLM 扩散模型与以往的模型(如大型语言扩散模型)存在显著差异。该模型在生成 token 后,针对已有的 token 进行了细致的调整。有关这一点,可以通过发布的演示视频直观地了解。
在演示的第一帧中,生成的答案明显是错误的。
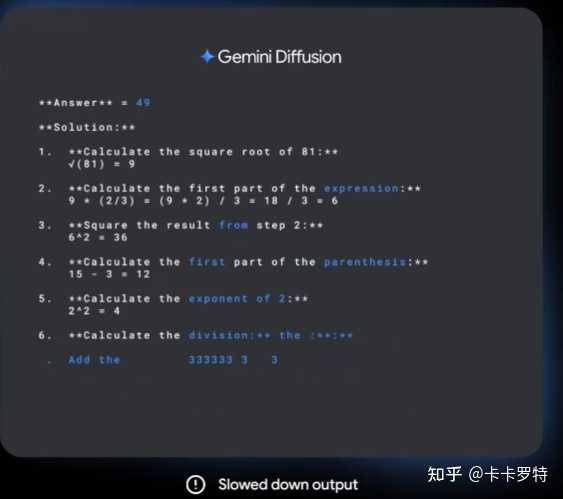
然而,到了第三帧时,系统成功生成了正确的答案。
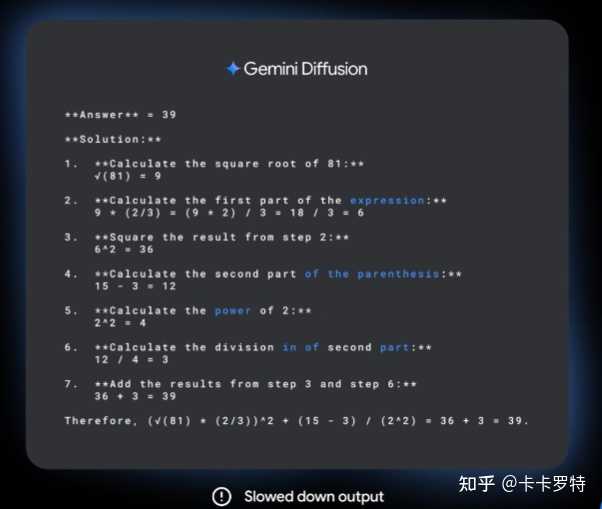
在大型语言扩散模型中,扩散过程更像是多 token 预测。与这种多 token 预测相比,谷歌的 LLM 扩散模型展现出更为优雅的特性,更加贴近人类的思维方式。
我个人认为,扩散模型与下一个 token 预测在本质上是相同的。有关详细讨论,可参考以下文章:
卡卡罗特:从 ” 下一个 token 预测 ” 到扩散模型无论是在训练的规模法则还是推理的规模法则中,二者都依赖于增加计算资源来接近“智能”这一目标。
下一个 token 预测的模式在某些方面的缺陷(从另一个角度看也可视为优点)在于,随着输入上下文长度的增加,其时间和空间的复杂度也会随之上升。
与此相对,扩散模式的一个优势(某种程度上也可视为缺点)在于,其空间复杂度是固定的,而时间复杂度则会随着迭代次数的增加而增长。
之前有朋友提到一个观点,可能在面对相同复杂问题时,两种方法的时间复杂度最终相差无几。我对此表示赞同。但我想补充的是,尽管两者的时间复杂度相似,扩散的并行计算方式可能更加适合 GPU 的运算,甚至有望找到更优的近似算法。因此,从这个角度来看,LLM 扩散模型仍然具有积极的意义。
最后,我一直在思考,是否有可能存在一种推理模型,其思考部分并非通过下一个 token 预测完成,而是采用类似谷歌的 LLM 扩散方式,持续精细调整固定大小的上下文。这样一来,就能够在有限的空间复杂度内不断增强时间复杂度。我认为现有的下一个 token 预测可能存在许多空间复杂度的浪费。而在思考结束后,再利用下一个 token 预测来输出最终答案。
分割线,顺便宣传一下我们最近的研究成果。
http://arxiv.org/abs/2505.15784
我们在数学上证明了,大型语言模型的训练过程可以视为对 Solomonoff 先验的可计算近似。而大型语言模型的下一个 token 预测正好可以视为 Solomonoff 归纳的可计算近似。
利用 Solomonoff 先验的数学特性,可以很好地解释上下文学习、少样本学习以及训练规模法则和推理规模法则。此外,我们还提出了一种选择少样本示例的技巧,以验证这一理论框架的合理性。

