共计 1502 个字符,预计需要花费 4 分钟才能阅读完成。
2025 年 4 月 29 日,qwen- 3 正式发布。
这款模型在实际应用中的表现如何呢?它能否在某些特定场景中与国外顶级闭源模型如 gemini 2.5 pro 和 o3 相匹敌?
https://qwenlm.github.io/blog/qwen3/
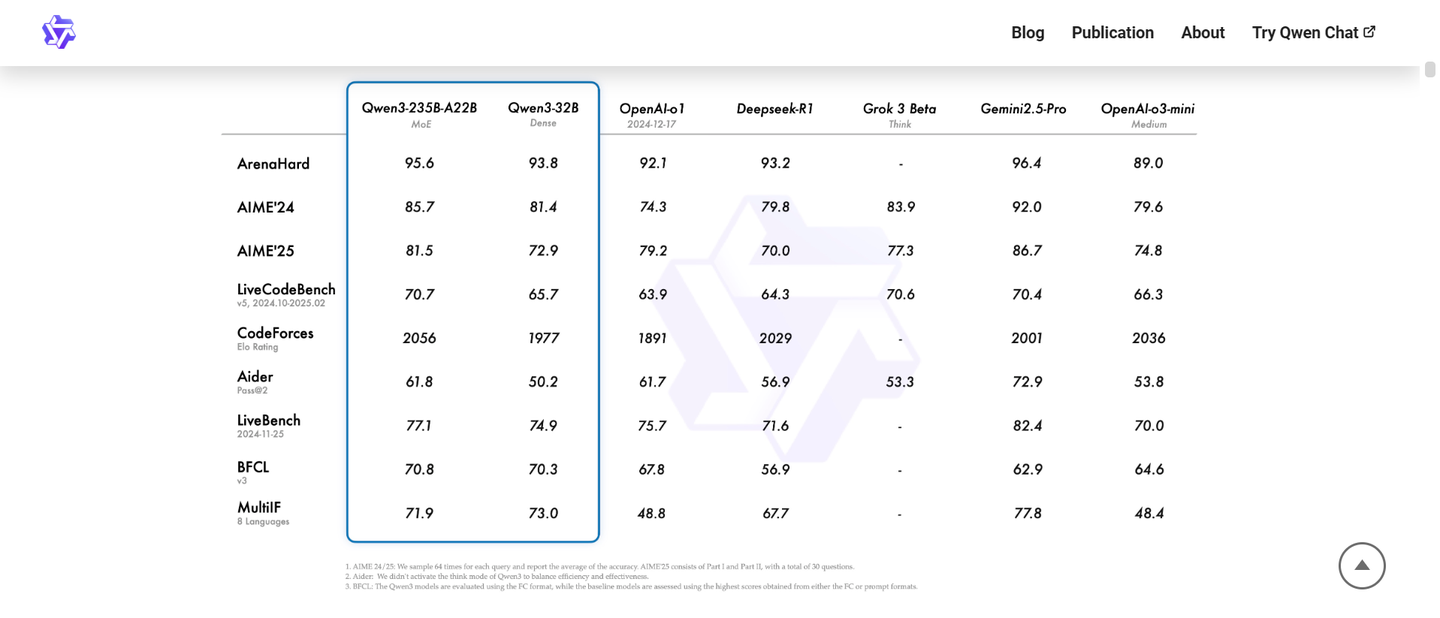
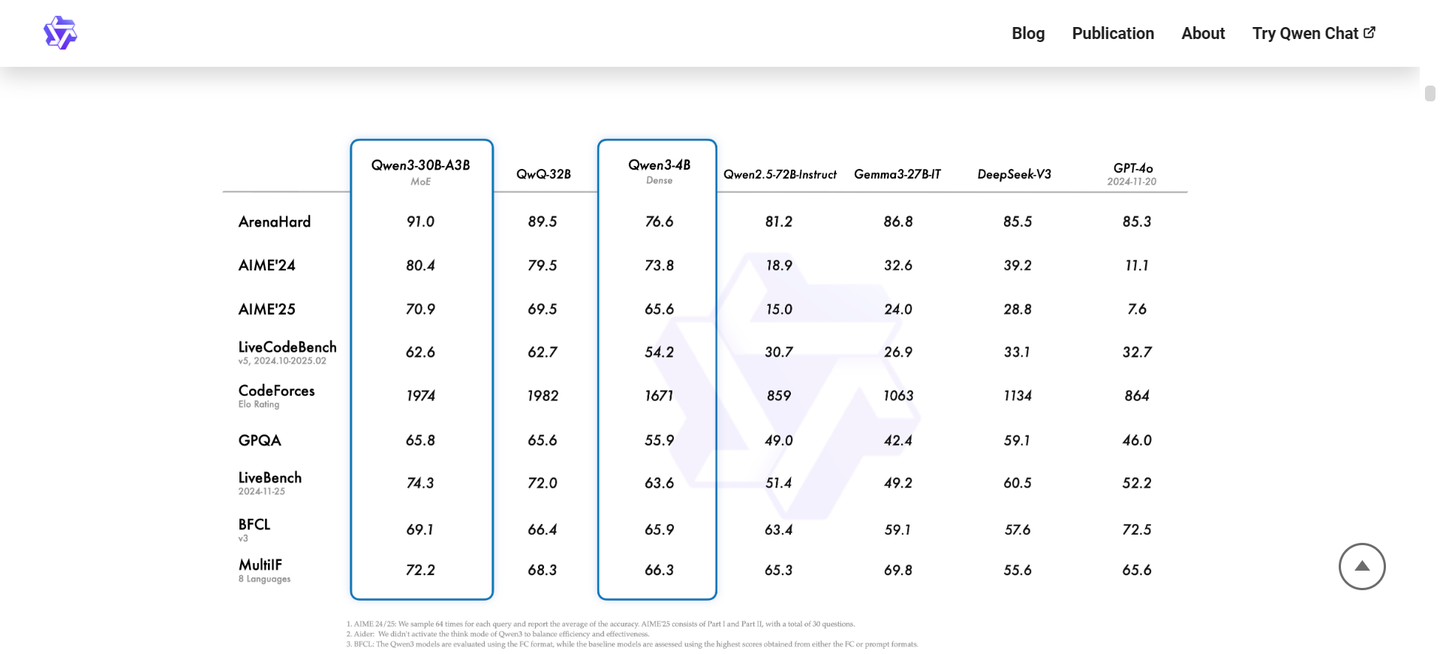
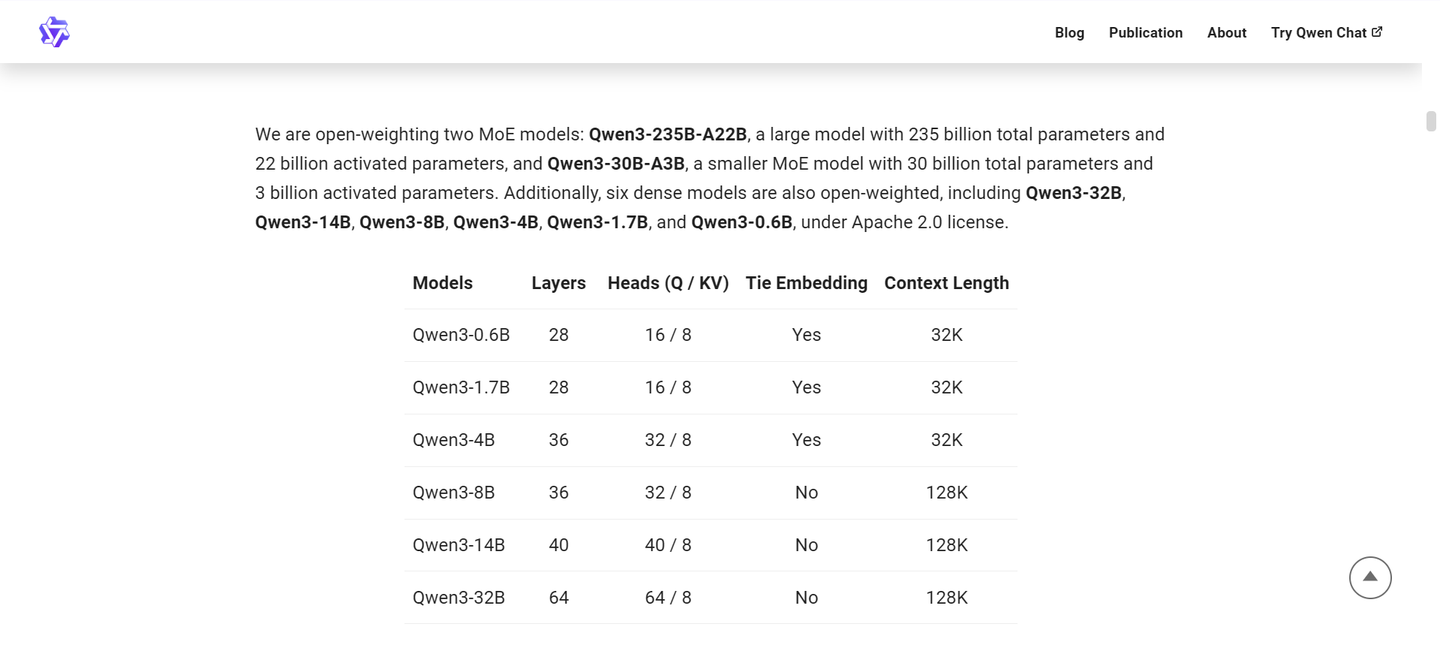
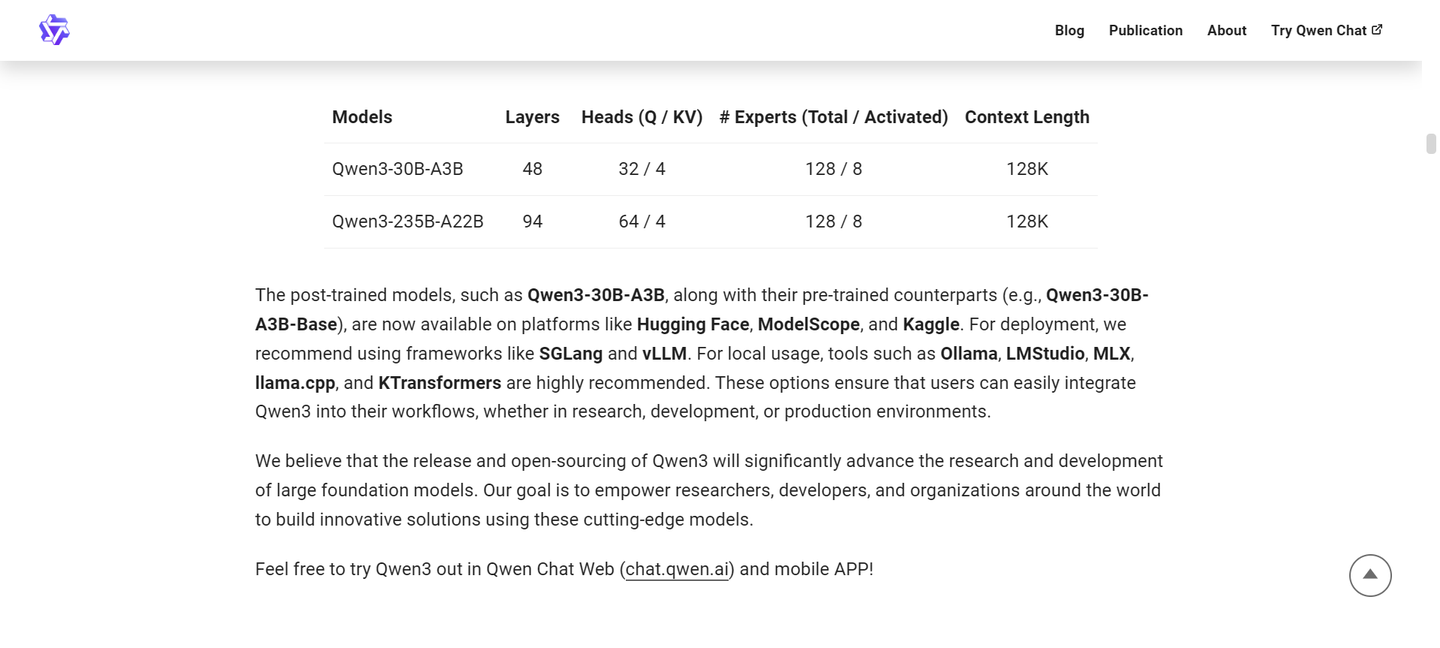

在假期期间,我处理了一些本地数据,想要使用本地模型进行推理,因此考虑尝试刚刚开源的千问 3。
我仅有一块 3090 显卡,配备 24GB 显存,且无法使用 FP8 精度,因此很多模型都无法运行。
手头可用的选项有 qwen3-8B 标准版和 qwen3-14B 量化版(okwinds/Qwen3-14B-Int4-W4A16);这两个单一模型的显存占用大约在十几个 GB。借助 vllm 或 sglang,可以实现十几个并发,总吞吐量达到六百多个 tokens/s。
接下来是选择推理引擎的过程。起初我考虑使用最近颇受关注的 sglang,但由于我本地的 cuda 版本过于陈旧,即使升级后似乎仍然有问题,使用 docker 也无法解决,所以我最终放弃了该选项。
最终选择了 vllm, 一次性成功部署 ,效果非常理想。我参考了这个链接的教程 https://docs.vllm.ai/en/v0.8.5.post1/getting_started/installation/gpu.html
接下来是提示词的调试。
千问 3 小版本的提示词测试:
我的任务是校对小说文本。起初,我编写了非常多细致的任务指令,但结果并不理想,尝试了各种调整也无济于事,一度对 qwen3 和 llama4 表示失望。
后来我意识到,删除一条任务要求后效果有所改善。
于是,我决定去除所有具体的提示词,仅保留最基本的任务要求,结果竟然变得更好。
最终调整后的版本逻辑如下:
- 上下文长度限制在 1K 以内,每个文本块控制在 256 以内;
- 仅需原则性提示,过多的精确指令会导致混乱;
- 温度系数需调低至 0,topk 设置为 1(此设定适用于文本校对任务,对开放性任务可能不同);
- 即使不开启推理,文本校对的能力仍然可以接受;
- 开启推理后,有时会出现推理成功但正文未能正确修改的情况;
- 同时,推理输出格式不正确的现象也会出现,例如“think>”可能被丢弃,这可能与量化有关;
- qwen3 的小模型几乎没有安全限制,适合本地文件处理,具体细节就不多说了。
- 小模型仍需在后续添加更多工程性保障才能有效使用。
其他:
如果大家想使用官方的 API,可以参考以下的教程:Qwen3 官方百炼 API 调用保姆级教程 – 强化学徒的文章 – 知乎 https://zhuanlan.zhihu.com/p/1900626403285767970
不过,他们的安全限制非常严格,且无法调整,因此我还是推荐进行本地部署。
最后,分享一下我的日常口号:
在赛博都市修炼,与 AI 共同进化!