共计 1017 个字符,预计需要花费 3 分钟才能阅读完成。
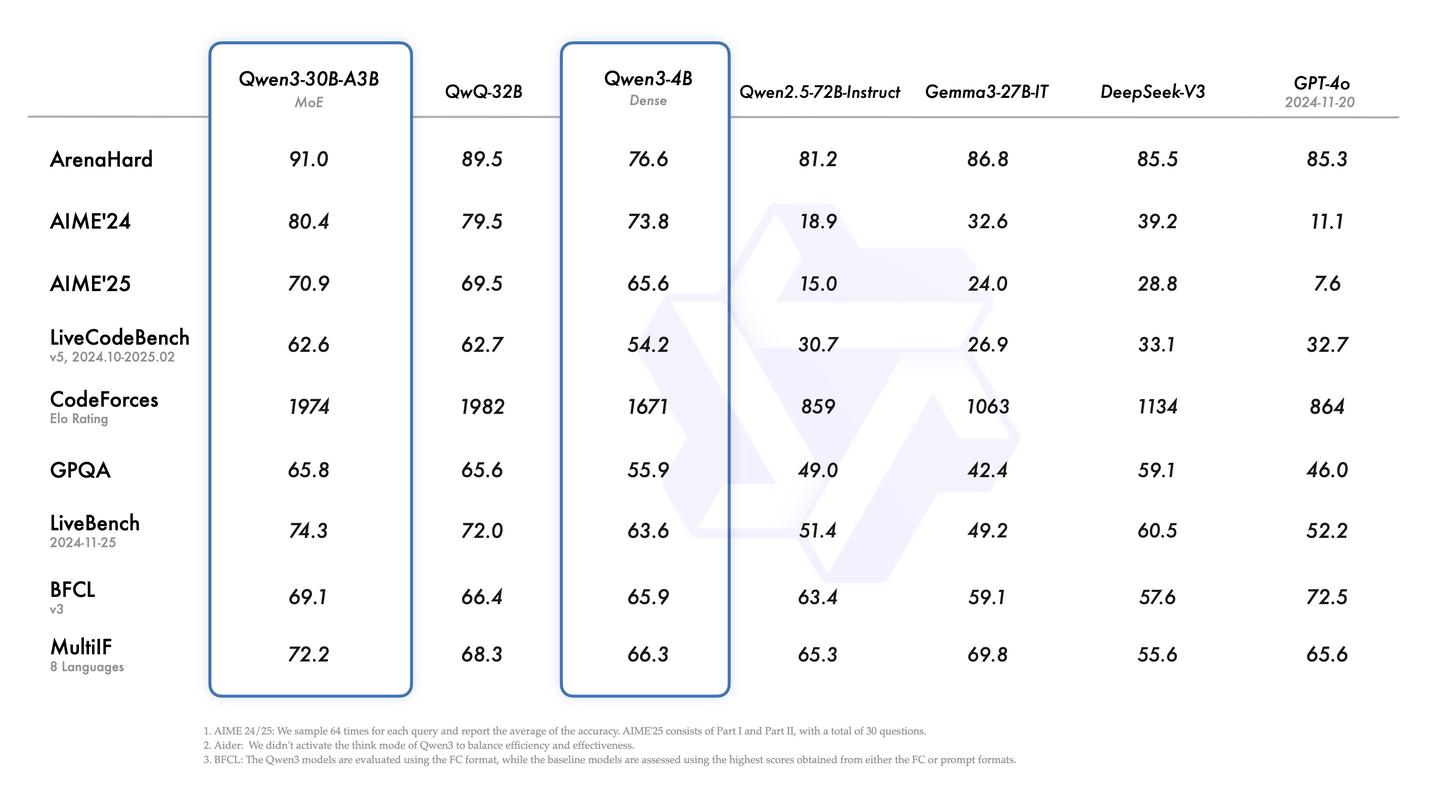
根据介绍,旗舰型号Qwen3-235B-A22B在多项基准测试中展现出色的竞争力,特别是在代码、数学及通用能力方面,表现甚至超过了DeepSeek-R1、o1、o3-mini、Grok-3以及Gemini-2.5-Pro等一流模型。此外,较小的MoE模型Qwen3-30B-A3B的激活参数仅为QwQ-32B的10%,其表现更为突出,甚至连Qwen3-4B这样的较小型号都能与Qwen2.5-72B-Instruct的性能相提并论。
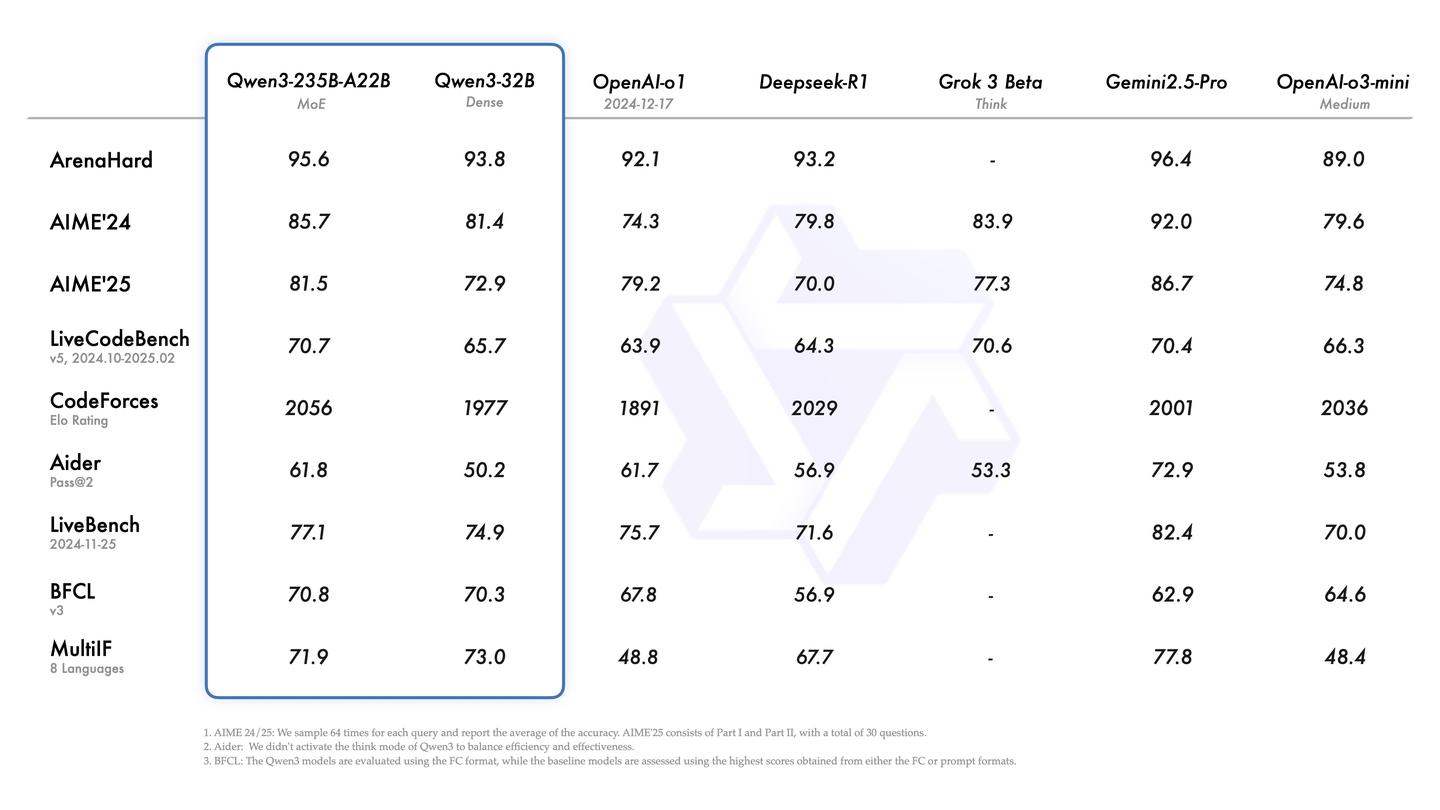
然而,我必须泼点冷水,Qwen 3实质上只是一个解题模型,世界知识的储备相对匮乏,实际使用中的稳定性令人担忧。
以Simple QA测试集为例,Qwen 3的旗舰版本235B A22B仅获得了11%的得分。Simple QA主要涉及一些事实性问题,用以衡量模型对世界知识的掌握程度。右侧那几乎看不见的条形图,正是Simple QA的得分情况。
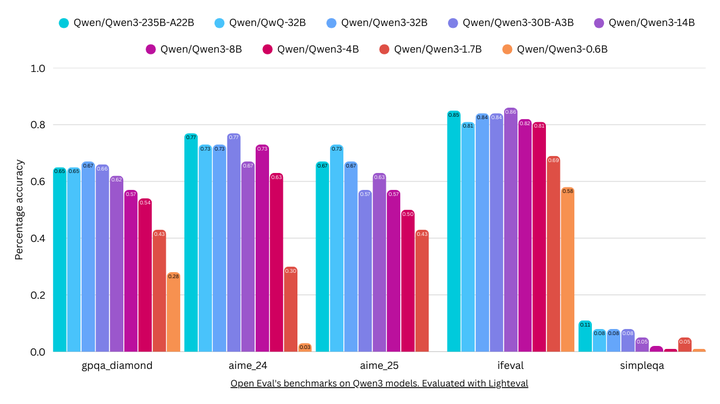
11%的得分意味着什么呢?这个数字实在太低了。比如,GPT 4o的得分接近40%。这样的得分水平,与GPT 4o mini相仿。
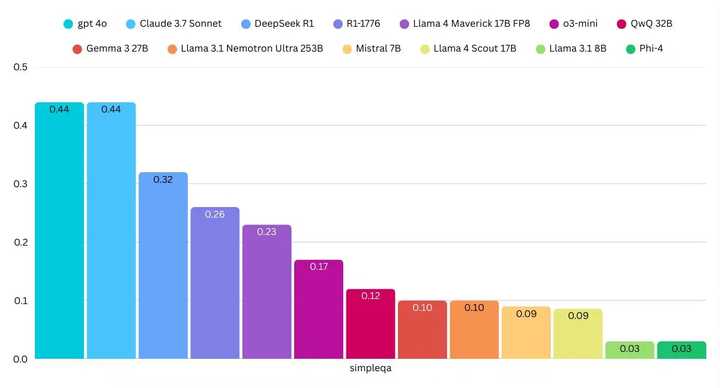
这也解释了之前QwQ模型所遇到的问题,即对于一些基本概念的无知和独立推理的局限。
目前,通过强化学习对小型模型进行过度训练,虽然在数学、物理和编程能力上有所提升,但模型依然缺乏知识的积累,仅仅掌握了解题的技巧。
我也难以理解,解题模型除了用于竞赛培训和高考难题辅导外,还有什么实际意义。就像许多人使用谷歌搜索,很多关键词只为找到官方网站,当前的大型模型问答仍然停留在基础知识层面。
在我的日常对话中,使用频率最高的仍是GPT 4o和Claude 3.7 sonnet。从实际体验来看,Qwen 3的稳定性同样令人担忧,时常出现无限推理的死循环,或者代码变长后开始出现杂乱无章的情况,仿佛这种模型接近崩溃,发布的更像是实验品而非成熟产品。
由于llama 4未推出适合个人设备的小型8B模型,Qwen 3的0.6B、4B和8B系列产品成为了本地用户的唯一选择。
务实地进行模型开发,而不是单纯追求高分,Qwen本有潜力做得更好。