共计 1658 个字符,预计需要花费 5 分钟才能阅读完成。
文 |ho 侯神
编辑 |ho 侯神
在当今全球范围内,人工智能的浪潮汹涌而至,特别是像 GPT- 4 这样的先进语言模型,已然融入了我们的日常生活与工作之中。
这些模型看似具备强大的能力,能够轻松处理从知识问答到文本创作、智能对话等多种复杂任务,然而在这光鲜的表象之下,潜藏着一些不容忽视的隐忧。
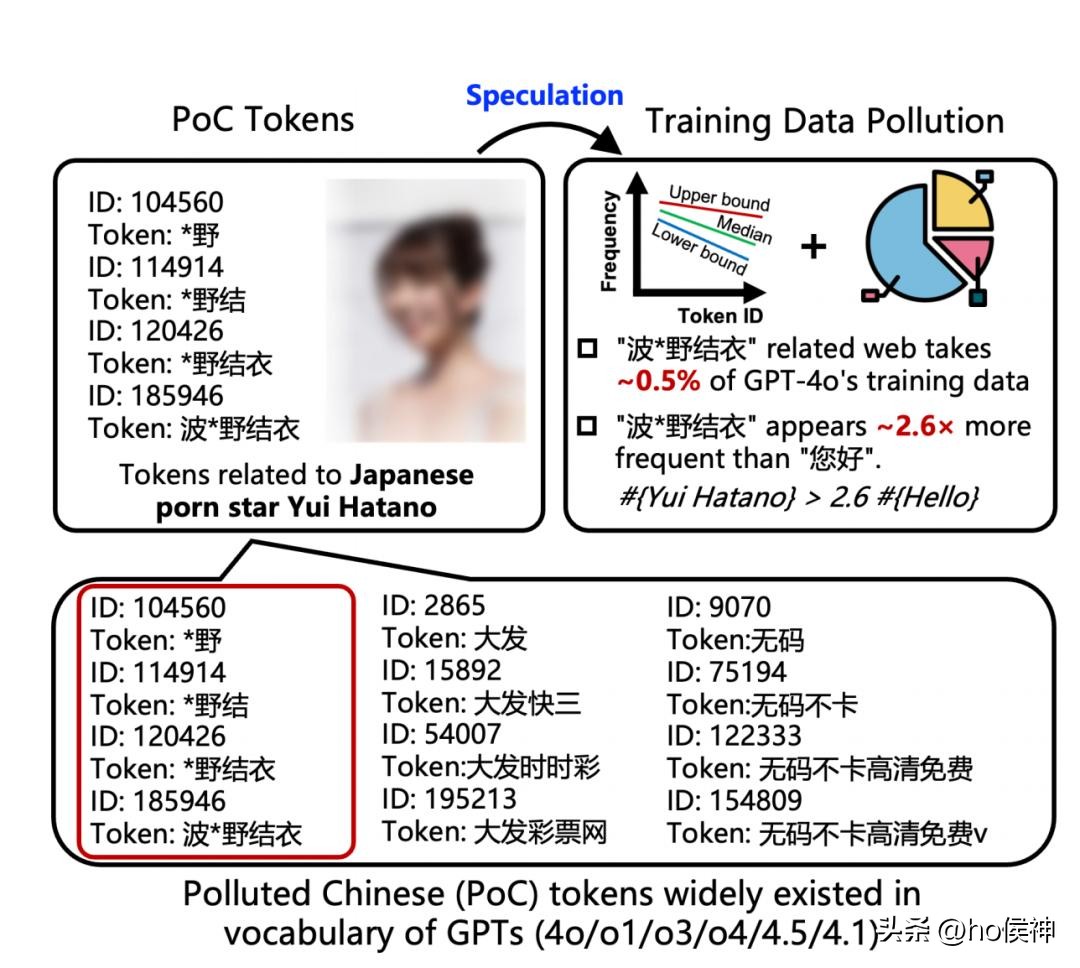
例如,GPT- 4 对灰色词汇的了解程度令人震惊,竟然是常用问候语“你好”的 2.6 倍,这一现象实在值得关注。
语言模型的训练数据来源于多种渠道,其设计目的本应是促进积极、合法且符合道德规范的交流与应用场景。
如此之高的灰色词汇熟悉度,表明其在学习过程中吸收了大量不当内容,这些内容在未来的应用中可能会误导用户,甚至被滥用。

训练语言模型的过程极为复杂,一旦在庞大的数据训练中形成对灰色词汇的高度熟悉,想要彻底消除这种印记,光靠调整参数或重新训练部分数据是远远不够的。
这需要从整体训练体系、数据筛选机制到模型架构进行全面反思与改进,工程浩大且艰巨。
当我们以强烈的情感来审视这个问题时,内心难免涌起不安与忧虑。GPT- 4 本应是推动人类进步、提升生活质量的得力助手,是科技赋予我们探索未知、创造美好的神奇工具。
然而,如今其对灰色词汇的过度熟悉犹如一颗潜伏的定时炸弹,随时可能引发一系列不良后果。
如果我们满怀信任与其交流,期待获取有益的知识和积极的建议,然而它却可能因其对灰色词汇的敏感而不自觉地输出一些负面、有害甚至违背社会公序良俗的内容。
这种情况不仅会误导个人的认知与价值观,长此以往,还可能对整个社会的信息生态产生影响,让不良思想和行为滋生。
难道这样的 AI 发展方向是我们所期望的吗?
这绝非我们所渴望的,我们期待的是一个纯净、健康、积极向上的 AI 世界,成为真正为人类带来福祉的科技伙伴。
轻松幽默地说,GPT- 4 对灰色词汇的熟悉程度,简直像是一个“不良词汇小专家”,而其他模型则努力学习“你好”“谢谢”等文明用语,争取成为“礼貌标兵”。
它却恰恰相反,沉迷于灰色词汇的“神秘海洋”,乐此不疲地探索那些不太光彩的词汇。
这就像一个孩子,不愿意学习书本上的知识,反而对街头巷尾不堪入耳的脏话记得如数家珍,难免让人感到焦虑。
我们原本希望它能助我们在知识的道路上披荆斩棘,结果却带着一堆“歪门邪道”的词汇,仿佛要把我们引向错误的方向。
GPT- 4 对灰色词汇的熟悉度,源于信息筛选和学习过程中的机制不完善或数据偏差,导致输出结果偏离正常轨道,给用户及整体生态环境带来了负面影响。
如今,尤其是像 GPT- 4 这样的国外 AI 模型,其影响力不容小觑。在其庞大的训练数据中,灰色词汇就如同混杂在健康信息中的“坏鱼”,不知不觉中被其学习了。
原本是为了提供正确、积极信息的工具,现在却对不良词汇的认知超越了常用问候语,隐患巨大。如果 GPT- 4 在应用中,例如为人撰写文章或回答问题时,意外输出这些灰色词汇,后果不堪设想。
例如,孩子们在学习时,如果接触到这些不当内容,岂不是会影响他们的思想发展。
误导个人认知虽然是小事,但若在网络上传播,将对整个信息环境造成污染,而解决这一问题并非易事。要从数据筛选、模型训练机制等基础开始改进,就如同为一栋大楼重打地基,工程量巨大。
AI 技术如同脱缰的野马,飞速向前,但我们不能只满足于其所带来的强大功能与便利,而忽略潜在的风险。

我们必须建立一套完善而严格的技术监管机制,从数据采集、清洗,到模型训练与优化,确保每个环节都经过细致审查,以保证 AI 学习的内容健康、积极,符合人类的价值观。
在道德层面上,也需达成广泛共识,确保 AI 开发者、使用者及整个社会明白,AI 的发展应以人类的福祉为核心,不能为了追求技术突破而忽视道德底线。
GPT- 4 对灰色词汇的高熟悉度绝非小事,我们不能对此掉以轻心,更不能等到问题爆发后再后悔不已。
我们应以审慎的态度全面审视与改进 AI,让它真正成为推动人类社会进步的强大动力,而不是沦为传播不良信息、破坏社会和谐的帮凶。
唯有如此,我们才能在享受 AI 带来的科技红利时,确保生活、社会及未来朝着健康、美好的方向发展。