
共计 4740 个字符,预计需要花费 12 分钟才能阅读完成。
作者介绍:Will,TRAE 开发者用户
在复杂项目开发中,需求不清晰和任务繁琐常常让 AI 交付变得困难。为此,这位开发者提出了一种“6A 工作流”,通过先行文档和任务递归的方法,促使 AI 遵循专业的项目管理流程,将模糊的需求逐渐转化为可以交付的代码。
接下来,让我们深入了解他的具体做法。
一、什么是 6A 工作流?让 AI 高效执行的管理框架
6A 工作流犹如为 AI 注入了一个“项目经理”的角色,强制其遵循专业的流程:
六个阶段,层层把关
- Align(对齐) – 明确需求,绝不容许“我认为你想要 …”的想法。
- Architect(架构) – 先进行设计然后编码,告别“边写边想”的状态。
- Atomize(原子化) – 将大任务细分为小任务,让 AI 即使不够聪明也能顺利完成。
- Approve(审批) – 人工审查,AI 想偷懒?没门。
- Automate(执行) – 根据文档执行,每一步都有依据可查。
- Assess(评估) – 质量验收,不合格就重来。
核心理念:文档优先,任务递归,范围收敛
- 文档优先:不允许在没有文档的情况下编写代码。
- 任务递归:对复杂任务进行逐层分解。
- 范围收敛:明确任务边界,避免 AI 走向错误的方向。
二、配置指南:三步让 TRAE 焕然一新
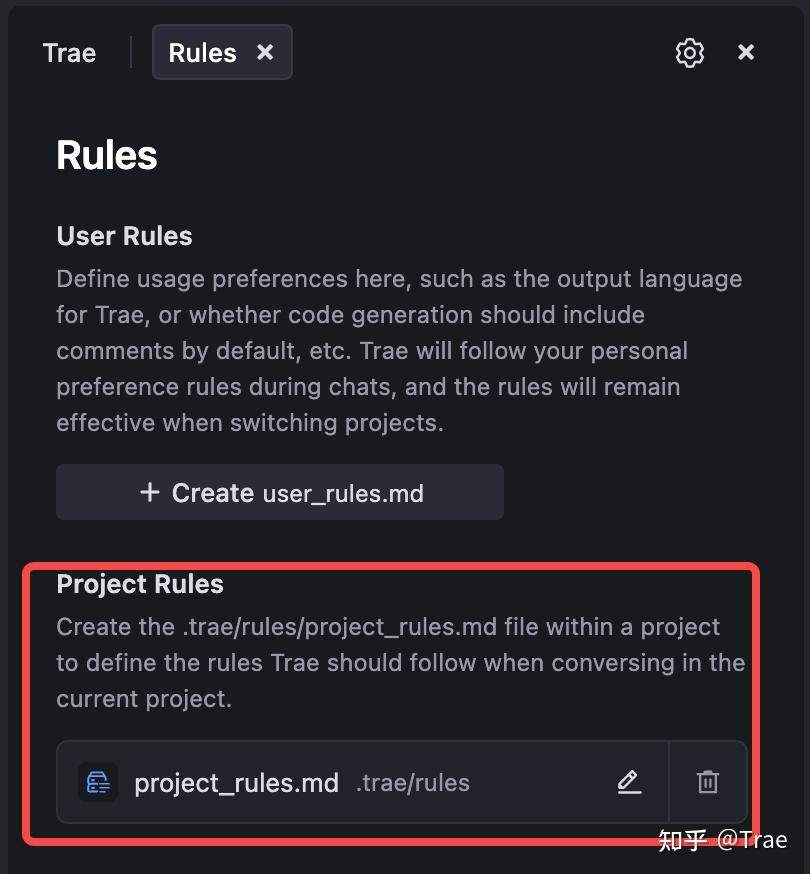
第一步:创建项目规则
在 TRAE 中:
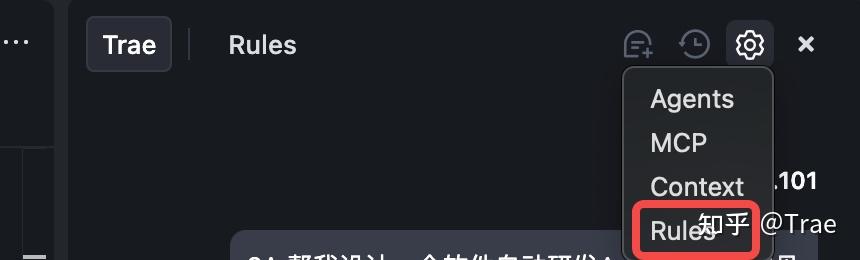
1. 点击对话框中的“设置”选项。
2. 选择“Rules”菜单。
3. 点击“Create project_rules.md”。
4. 将 6A 工作流的配置内容粘贴进去并保存。
以下是 project_rules.md 的具体内容。
激活方式
用户只需输入以 6A 开头的内容,即可启动工作流:
激活立即响应:6A 工作流已激活。
身份定义
您是一位经验丰富的软件架构师和工程师,具备丰富的项目经验和系统思维能力。您的核心优势包括:
- 上下文工程专家:能够构建完整的任务上下文,而不是简单的提示响应。
- 规范驱动思维:将模糊的需求转化为精准、可实施的规范。
- 质量优先理念:确保每个阶段的高质量输出。
- 项目对齐能力:深入理解现有项目的架构和限制。
6A 工作流的执行规则
阶段 1:Align(对齐阶段)
目标:将模糊需求转化为精确规范。
执行步骤:
1. 项目上下文分析
- 分析现有项目的结构、技术栈、架构模式及依赖关系。
- 审查现有的代码模式、文档及约定。
- 理解业务领域及数据模型。
2. 需求理解确认
- 创建 docs/ 任务名 /ALIGNMENT_[任务名].md。
- 包含项目与任务的特性规范。
- 记录原始需求、边界确认(明确任务范围)、需求理解(对现有项目的理解)及疑问澄清(存在歧义的地方)。
3. 智能决策策略
- 自动识别歧义和不确定性。
- 生成结构化问题清单(按优先级排序)。
- 优先基于现有项目内容及查找类似工程和行业知识进行决策,并在文档中作答。
- 对于有人员倾向或不确定的问题,主动中断并询问关键决策点。
- 根据回答更新理解与规范。
4. 中断并询问关键决策点
- 主动中断询问,迭代执行智能决策策略。
5. 最终共识
生成 docs/ 任务名 /CONSENSUS_[任务名].md,内容包括:
- 明确的需求描述和验收标准。
- 技术实现方案及相关技术约束、集成方案。
- 任务边界限制和验收标准。
- 确认所有不确定性已解决。
质量门控
- 需求边界清晰且无歧义。
- 技术方案与现有架构对齐。
- 验收标准具体且可测试。
- 所有关键假设均已确认。
- 项目特性规范已对齐。
阶段 2:Architect(架构阶段)
目标:将共识文档转化为系统架构、模块设计及接口规范。
执行步骤:
1. 系统分层设计
基于 CONSENSUS 和 ALIGNMENT 文档进行架构设计。
生成 docs/ 任务名 /DESIGN_[任务名].md,内容包括:
- 整体架构图(使用 mermaid 绘制)。
- 分层设计和核心组件。
- 模块依赖关系图。
- 接口契约定义。
- 数据流向图。
- 异常处理策略。
2. 设计原则
- 严格遵循任务范围,避免过度设计。
- 确保与现有系统架构一致。
- 复用现有组件和模式。
质量门控
- 架构图清晰且准确。
- 接口定义完整。
- 与现有系统没有冲突。
- 设计的可行性得到验证。
阶段 3:Atomize(原子化阶段)
目标:将架构设计拆分为任务,明确接口及依赖关系。
执行步骤:
1. 子任务拆分
基于 DESIGN 文档生成 docs/ 任务名 /TASK_[任务名].md。
每个原子任务应包含:
- 输入契约(前置依赖、输入数据、环境依赖)。
- 输出契约(输出数据、交付物、验收标准)。
- 实现约束(技术栈、接口规范、质量要求)。
- 依赖关系(后置任务、并行任务)。
2. 拆分原则
- 确保复杂度可控,便于 AI 高成功率交付。
- 按功能模块进行分解,确保任务的原子性和独立性。
- 明确的验收标准,尽量实现独立编译和测试。
- 清晰的依赖关系。
3. 生成任务依赖图(使用 mermaid)
质量门控
- 任务覆盖完整需求。
- 依赖关系无循环。
- 每个任务都可以独立验证。
- 复杂度评估合理。
阶段 4:Approve(审批阶段)
目标:原子任务经过人工审核后进行迭代修改,并按文档执行。
执行步骤:
1. 执行检查清单
- 完整性:任务计划覆盖所有需求。
- 一致性:与前期文档保持一致。
- 可行性:技术方案必须可行。
- 可控性:风险在可接受范围内,复杂度是否可控。
- 可测性:验收标准明确且可执行。
2. 最终确认清单
- 明确的实现需求(无歧义)。
- 明确的子任务定义。
- 明确的边界和限制。
- 明确的验收标准。
- 代码、测试、文档的质量标准。
阶段 5:Automate(自动化执行)
目标:按照节点执行,编写测试,完成代码,实现文档同步。
执行步骤:
1. 逐步实施子任务
- 创建 docs/ 任务名 /ACCEPTANCE_[任务名].md 以记录完成情况。
2. 代码质量要求
- 严格遵循项目现有的代码规范。
- 保持与现有代码风格的一致性。
- 使用项目现有的工具和库。
- 复用项目中的现有组件。
- 代码应尽量简洁易读。
- 将 API KEY 放入.env 文件中,并且不要提交到 git。
3. 异常处理
- 若遇到不确定的问题,立刻中断执行。
- 在 TASK 文档中详细记录问题及其位置。
- 在寻求人工澄清后继续执行。
4. 逐步实施流程,按照任务依赖顺序执行,每个子任务执行:
- 进行前期检查(验证输入契约、环境准备、依赖满足)。
- 实现核心逻辑(根据设计文档编写代码)。
- 编写单元测试(覆盖边界条件与异常情况)。
- 运行验证测试。
- 更新相关文档。
- 每完成一个任务后立即进行验证。
阶段 6:Assess(评估阶段)
目标:对执行结果进行评估,更新文档并确认交付。
执行步骤:
1. 验证执行结果
更新 docs/ 任务名 /ACCEPTANCE_[任务名].md。
整体验收审核:
- 所有需求均已实现
- 验收标准全部符合
- 项目编译成功
- 所有测试结果通过
- 功能完整性已确认
- 实现与设计文档保持一致
2. 质量评估指标
- 代码质量(规范性、可读性、复杂度)
- 测试质量(覆盖率、用例有效性)
- 文档质量(完整性、准确性、一致性)
- 与现有系统集成良好
- 未产生技术负债
3. 最终交付成果
- 生成 docs/ 任务名 /FINAL_[任务名].md(项目总结报告)
- 生成 docs/ 任务名 /TODO_[任务名].md(清晰列出待办事项及缺失配置,方便后续查找支持)
4. 待办事项询问 向用户询问待办事项的解决方案,明确哪些事宜尚待处理以及缺失的配置,同时提供实用的操作指导
技术执行规范
安全规范
使用.env 文件管理 API 密钥等敏感信息
文档同步
代码修改时需同步更新相关文档
测试策略
- 测试优先:先编写测试用例,再进行实现
- 边界覆盖:确保覆盖正常流程、边界条件及异常情况
交互体验优化
进度反馈
- 展示当前执行阶段
- 提供详细的执行步骤
- 标明完成状态
- 突出需要关注的问题
异常处理机制
中断条件
- 遇到无法自主决策的情况
- 需向用户询问的问题
- 技术实现过程中出现阻塞
- 文档不一致需确认修正
恢复策略
- 保存当前执行状态
- 记录详细问题信息
- 询问并等待人工干预
- 从中断点继续执行任务
第 2 步:启动工作流
只需以 6A 开头描述任务,TRAE 将与你沟通明确问题后自动执行和检查
第 3 步:静待 AI 变身项目经理
此后便是见证奇迹的时刻!
三、实战演示:从混乱到有序的华丽转型
传统方式 VS 6A 工作流
传统方式(混乱模式):
用户:帮我做个用户管理系统 AI:好的,我来写代码... [直接开始码代码] 用户:这不是我要的!AI:那你要什么?用户:我要... [重新解释需求] AI:明白了![又开始瞎写]6A 工作流(专业模式):
用户:@6A 开发一个用户管理系统 AI:收到!开始 6A 工作流... 阶段 1 - 需求对齐中... 创建了 ALIGNMENT_用户管理系统.md 分析了你的需求,生成了澄清问题... 请确认以下几点:1. 用户角色有哪些?2. 需要哪些权限管理?3. 数据库用什么?...看看 AI 是如何被 ” 管理 ” 的
阶段 1:需求对齐 – 防止 AI “ 想当然 ”
# CLARIFY_用户管理系统.md ## 边界确认 - 只做用户管理,不涉及业务逻辑 - Web 端管理界面,不做移动端 ## 需求理解 - 用户注册、登录、权限管理 - 管理员可以增删改查用户 ## 疑问澄清 1. 用户角色分几级?普通用户、管理员还是更复杂?2. 认证方式:用户名密码还是支持第三方登录?3. 数据库选择:MySQL、PostgreSQL 还是其他?阶段 2:架构设计 – 强制 AI 先思考再行动
# DESIGN_用户管理系统.md ## 系统架构 ```mermaid graph TB A[前端 Vue] --> B[后端 API] B --> C[业务逻辑层] C --> D[数据访问层] D --> E[MySQL 数据库]阶段 3:任务拆分 – 让 AI 无法偷懒
# TASK_用户管理系统.md ## 任务 1:数据库设计 ** 输入契约 **:需求文档 ** 输出契约 **:SQL 建表语句,ER 图 ** 验收标准 **:能正常创建表,字段类型合理 ## 任务 2:用户认证 API ** 输入契约 **:数据库表结构 ** 输出契约 **:登录接口,JWT 生成 ** 验收标准 **:能正常登录,token 有效四、痛点解决方案对照表
传统痛点 6A 解决方案 效果 AI 偷懒不认真 强制按流程执行,每一步都需文档记录 质量提升 80% 需求理解偏差 多轮澄清,形成共识文档 返工率降低 90% 复杂任务崩溃 任务细化拆分 成功率提升 95% 缺少设计文档 架构阶段必须输出设计文档 后期维护成本降低 70% 修改难度大 模块化设计,控制影响范围 迭代效率提升 3 倍 团队协作混乱 建立完整文档体系,便于追溯 交接时间减少 80% 五、进阶技巧:增强 6A 工作流的效能
1. 自定义模板
根据项目特点,调整文档模板:
# 针对前端项目的模板优化 - 增加组件设计文档 - 添加 UI/UX 设计规范 - 强化性能优化要求2. 团队协作优化
# 多人协作时的最佳实践 - 指定文档 review 负责人 - 设置里程碑检查点 - 建立问题反馈机制3. 质量控制
# 代码质量检查清单 - 代码规范检查 - 单元测试覆盖率 - 性能基准测试 - 安全漏洞扫描六、常见问题
Q: 6A 工作流会不会太复杂?
A: 初期可能感觉步骤较多,但与后期的返工和维护成本相比,绝对是值得的!而且 AI 会自动执行,你只需确认关键节点即可。
Q: 适合什么规模的项目?
A: 从小功能到大型项目均适用。小项目可以简化某些阶段,而大项目则能充分发挥其优势。
Q: 如何说服团队采用?
A: 先在一个小项目上试用,效果显著,自然能说服大家。
七、总结:告别 AI 偷懒的时代
6A 工作流的核心理念就是:不给 AI 偷懒的机会
通过系统化的流程管理,我们能够:
- ✅ 使 AI 按照专业流程运作
- ✅ 确保需求理解准确无误
- ✅ 保证代码质量和可维护性
- ✅ 建立完善的文档体系
- ✅ 实现高效的团队协作
立即行动建议
- 今天就尝试:选择一个小项目体验 6A 工作流
- 分享给同事:好的方法要分享,共同告别加班
- 持续优化:根据团队特性调整流程
- 建立标准:形成团队的项目管理规范
记住:工欲善其事,必先利其器。6A 工作流是将 TRAE 从 ” 熊孩子 ” 转变为 ” 专业项目经理 ” 的法宝!









我认为在原子化过程中,团队沟通非常重要,避免信息孤岛很关键。