
共计 4709 个字符,预计需要花费 12 分钟才能阅读完成。
随着可供开发的语言日益复杂,人工智能(AI)的演变速度也在不断加快。早在 1959 年,IBM 的亚瑟·塞缪尔便在 IBM® 701 计算机上创建了一款西洋跳棋自学程序,运用了搜索树和 alpha-beta 剪枝算法,使得该程序相当庞大。如今,程序员们使用多种语言,如 Lisp、Python 和 R,来开发 AI。本文旨在深入探讨人工智能和机器学习领域语言的演变历程。
开发 AI 和机器学习应用的编程语言种类繁多。每个应用程序都有其特定的限制和需求,因此某些语言在特定领域中可能更具优势。为了满足 AI 应用的独特需求,新语言不断被创造和改进。
高级语言出现前的时代
在人工智能的早期,唯一可用的编程语言是机器的原生语言。这种被称为机器语言或汇编语言的表达方式极其复杂,操作仅限于简单的指令(如将值从内存转移到寄存器,或从累加器中减去内存地址的内容)。同样,机器处理的数据类型也相当有限。然而,即使在高级语言诞生之前,开发复杂的 AI 应用程序的尝试已经开始。
1956 年,AI 的奠基人之一约翰·麦卡锡提出了一种名为 alpha-beta 剪枝的树搜索算法。在此期间,许多 AI 问题被视为搜索问题,研究活动相当活跃。尽管当时的内存和计算能力受限,但这一技术使得开发者能够在资源匮乏的早期计算机系统上解决更复杂的问题。alpha-beta 剪枝算法被用于早期的 AI 游戏程序中。
同样在 1956 年,亚瑟·塞缪尔在 IBM 701 计算机上利用麦卡锡的 alpha-beta 算法开发了一款西洋跳棋程序。不同于传统方法,塞缪尔引入了自学习的概念,使程序能够自主进行游戏而不需直接指导。该程序是基于 IBM 701 系统的原生指令集开发的,由于复杂性和低级指令的局限性,这款程序也显得相当庞大。
人工智能语言演化的不同阶段
人工智能的发展历程充满了许多精彩的故事,我将根据语言演化的进程将近代 AI 历史划分为三大阶段:早期(1954-1973)、混沌时期(1974-1993)和现代时期(1994 年至今)。
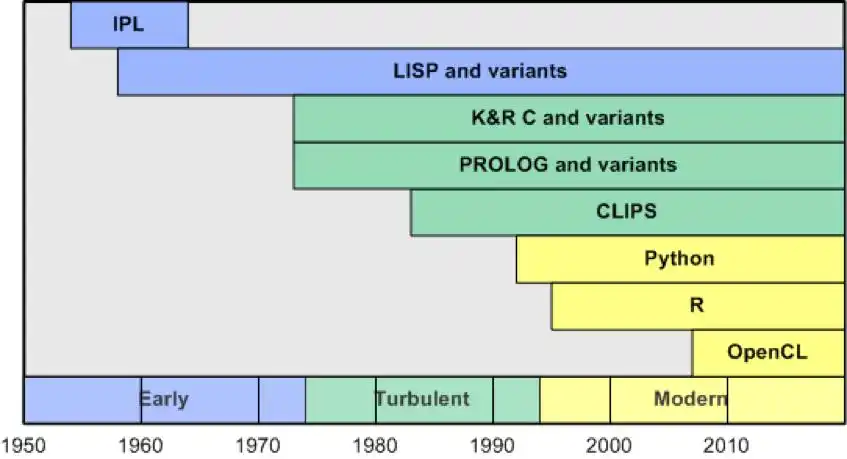
早期(1954-1973)
这一时期是探索的时代——新机器和功能的引入,以及高级语言的开发,使得这些机器可以被广泛应用。
1958 年,针对 IBM 704 计算机开发了国际象棋程序 NSS(由作者纽厄尔、肖和西蒙命名)。该程序从搜索的角度解析国际象棋,且是作者使用信息处理语言(IPL)编写的。IPL 是创建 AI 应用程序的第一种语言,尽管它只比机器语言稍微高级一些,但却使得开发者能够在多种计算机系统上使用。
IPL 引入的许多特性如今依然被广泛应用,例如列表、递归、高阶函数和符号处理,甚至能够将元素列表映射到可以进行迭代和处理的函数生成器。虽然 IPL 的初版未能实现,但后续版本(2-6)已在多个系统上成功应用,如 IBM 704、IBM 650 和 IBM 7090 等。利用 IPL 开发的早期 AI 应用程序还包括逻辑理论家和通用问题求解器。
尽管 IPL 在当时取得了成功并广泛应用,但很快就被一种更高级的语言所取代,这种语言至今依然在使用:LISP。IPL 复杂的语法被更简单、可扩展的 LISP 所替代,然而 IPL 对后续类似语言的影响仍然显而易见,尤其是在强调列表作为核心语言特性方面。
LISP(即列表处理器)是约翰·麦卡锡于 1958 年创建的。在 1956 年达特茅斯夏季 AI 研究项目之后,麦卡锡致力于为 IBM 704 平台开发一款专注于 AI 的语言。1957 年,同一平台上推出了 FORTRAN,而 IBM 则引入了一种名为 FORTRAN 列表处理语言(FLPL)的扩展,用于列表处理。此语言在 IBM 的平面几何学项目中取得了成功,但作为 FORTRAN 的扩展,FLPL 缺乏一些关键特性。
LISP 是一种基础编程语言,涵盖了计算机科学中的许多核心概念,如垃圾收集、树结构、动态类型、递归和高阶函数。LISP 不仅将数据表示为列表,甚至将源代码本身也视为列表。这一特性使得 LISP 能够同时处理数据和自身代码。LISP 的可扩展性也使程序员能够创建新的语法,甚至新语言(即特定领域语言)并嵌入到 LISP 中。
下面的示例展示了一个计算数字阶乘的 LISP 函数。在这段代码中可以观察到递归的使用(在阶乘函数中再次调用阶乘函数)。该函数可通过 (factorial 9) 进行调用。
(defun factorial (n)(if (= n 0) 1 (* n (factorial (- n 1)))))1968 年,特里·温格拉德利用 LISP 开发了一个具有开创性的程序 SHRDLU,能够与用户进行自然语言交互。该程序模拟了一个积木世界,用户可以通过诸如“拿起红色积木”或“一块积木能否支撑住一个角锥体?”的语句与程序进行互动。这一简单的积木世界自然语言理解和规划的展示,让人们对人工智能和 LISP 语言充满了希望。
混沌时期(1974-1993)
混沌时期象征着 AI 应用程序开发和资金支持的不稳定阶段。这一时期始于第一次 AI 寒冬,因未能实现预期成果而导致资金的枯竭。1980 年,专家系统的再度崛起点燃了对 AI 的热情,带来了资金的注入(与连接机制架构的发展相似),但到 1987 年,AI 泡沫再次破灭,导致第二次 AI 寒冬的到来,尽管这段时间也取得了一些进展。
在此期间,LISP 依然被广泛应用于多个项目,并通过各种方言传播开来。LISP 通过 Common LISP、Scheme、Clojure 和 Racket 等语言得以延续,其背后的理念也通过这些语言以及其他语言扩展到函数领域之外。LISP 继续为最早的计算机代数系统 Macsyma(Project MAC 的符号操纵器)提供支持。这个计算机代数环境由麻省理工学院的 AI 团队开发,是许多程序的雏形,如 Mathematica、Maple 等。
在这一阶段,其他语言也逐渐崭露头角,虽然它们不一定专注于 AI,但推动了 AI 的发展。C语言最初是为 UNIX 系统设计的系统语言,但很快便发展为一种流行语言(拥有多种变体,如C++),被广泛应用于从系统到嵌入式设备的开发。
在此期间,名为 Prolog(逻辑编程语言)的关键语言在法国被开发出来。Prolog 实现了一种称为霍恩子句的逻辑子集,允许通过事实和规则表示信息,并支持对这些关系的查询。以下是一个简单的 Prolog 示例,展示了如何定义一个事实(苏格拉底是凡人)和一条规则(凡人必死):
man(socrates). // Fact: Socrates is a man.mortal(X) :- man(X). // Rule: All men are mortal.Prolog 在这一时期被广泛应用于多个领域,并且拥有许多变体,这些变体融合了众多特性,比如面向对象、编译成原生机器码的能力,以及与流行语言(如C)的接口。
在这一阶段,Prolog 的一个重要应用是开发专家系统(也称为生产系统)。这些系统将知识整理成事实,并基于规则进行推理。然而,这些系统存在脆弱性,知识的存储既繁琐又容易出错。
一个示例专家系统是 eXpert CONfigurer (XCON),该系统用于配置计算系统。XCON 在 1978 年使用 OPS5(LISP 编写的生产系统语言)开发,采用正向链接进行推理。到 1980 年,XCON 已包含 2500 条规则,但其维护成本过高。
Prolog 和 LISP 并不是唯一用于开发生产系统的语言。1985 年,C 语言集成生产系统(CLIPS)被开发,成为构建专家系统最常用的工具。CLIPS 在一个由规则和事实组成的知识系统上运行,且是用 C 编写的,提供了一个 C 扩展接口以提高性能。
专家系统的失败是导致第二次 AI 寒冬的一个因素。它们的前景和交付能力的不足使得 AI 研究资金大幅减少。但正是在这个寒冬中,新的方法孕育而生,连接机制再次兴起,为我们进入现代时期铺平了道路。
现代时期(1994 年至今)
现代时期的人工智能开始从实用的角度探索该领域,并成功地将 AI 方法应用于实际问题,甚至解决了一些早期 AI 发展阶段的问题。AI 语言在这一时期表现出了显著的趋势。尽管新语言被应用于解决 AI 问题,但 LISP 和 Prolog 这两种主流语言依然在使用并取得了成功。此时,连接机制和新兴的神经网络方法(如深度学习)也逐渐重新崛起。
编程语言的演变与人工智能的崛起
随着 LISP 方言的增多,最终形成了一个统一的版本,称为 Common LISP。这种新语言融合了当时主流方言的特征。1994 年,Common LISP 被正式认可为美国国家标准协会的标准 X3.226-1994。
在这一阶段,各种编程语言纷纷涌现。有些是基于计算机科学的新理念,而另一些则强调关键特性,如多重泛型和易于学习。Python 正是属于后者的一种重要语言。作为一种通用的解释型语言,Python 融合了多种编程语言的特点,比如面向对象编程和受 LISP 启发的函数特性。Python 在智能应用程序开发中的优势在于,它有丰富的外部模块可供使用。这些模块涵盖了机器学习(如 scikit-learn 和 Numpy)、自然语言处理 (NLTK),以及众多神经网络库,涉及广泛的拓扑结构。
R 语言及其生态系统同样借鉴了 Python 的模型。R 是一种开源环境,专门用于统计编程和数据挖掘,由 C 语言构建。由于现代机器学习的核心本质大多是统计学,R 的实用性显而易见,自 2000 年稳定版本发布以来,它的受欢迎程度与日俱增。R 拥有大量技术库,并且具备扩展新特性的能力。
在此时期,C 语言依然发挥着重要作用。1996 年,IBM 研发了全球最快的国际象棋程序 Deep Blue,运行于一台搭载 IBM AIX® 操作系统的 32 节点 IBM RS/6000 计算机上,且是以 C 编写。Deep Blue 每秒可计算 2 亿个落棋点,并于 1997 年成为首个战胜国际象棋大师的人工智能。
而在这一时期的后半段,IBM 再次回归,但这一次不再局限于国际象棋的框架。IBM Watson® 问答系统(也称 DeepQA)能够理解并回答用自然语言提出的问题。IBM Watson 的知识库充满了 2 亿页的信息,包括整个 Wikipedia 网站。为了将自然语言问题转换为 IBM Watson 能理解的格式,IBM 团队使用 Prolog 进行解析,实现了在 IBM Watson 管道中使用的新事实。2011 年,该系统参加了 Jeopardy! 竞赛,并成功战胜了前冠军。
随着连接机制架构的重新回归,一些新应用开始显现,彻底改变了图像及视频的处理与识别。深度学习通过将神经网络扩展到深层结构,能够识别图像或视频中的物体,并通过自然语言生成描述,甚至为自动驾驶车辆提供实时道路和物体检测。这些深度学习网络规模庞大,传统计算架构往往难以高效处理,但引入图形处理单元(GPU)后,这些网络得以应用。
要将 GPU 作为神经网络的加速器,就必须使用新的编程语言,以实现传统 CPU 和 GPU 的结合。一种名为 Open Computing Language (OpenCL) 的开放标准,允许在 GPU 上执行类似于 C 或 C++ 的程序,这些 GPU 拥有数千个处理单元,远超传统 CPU 的处理能力。OpenCL 使得 CPU 能够有效地管理 GPU 内部的并行操作。
总结
在过去六十年里,计算架构经历了巨大的变革,人工智能技术及其应用也不断进步。这段时间内,各种编程语言不断演化,各具特色,提供了不同的解决方案。而如今,随着包含 CPU 集群和 GPU 阵列的大数据技术与新处理架构的出现,AI 领域涌现出一系列新的创新及支持其发展的编程语言。









听说现在有很多新的编程语言在开发AI,大家觉得哪些语言会成为未来的主流呢?