共计 6992 个字符,预计需要花费 18 分钟才能阅读完成。
这个问题常常引发讨论,然而在尝试过三个不同的 AI 之后,最终都想要这三者的结合。
昨日,在与公司首席技术官的交流中,提出了一个深刻的疑问:“我们究竟应该选择哪个 AI 呢?Claude 的价格高得离谱,ChatGPT 时常出现错误,而 Gemini 似乎没有太大存在感?”
经过一番思考,我意识到很多人在选择 AI 时,仿佛是在玩盲盒,完全依赖运气来决定。
作为一名在 AI 领域摸爬滚打多年的从业者,我想说:不必再纠结于哪个“最好”,因为 2025 年已经是多模型协同的时代了。
上周,我们团队进行了一次实验,针对同一个 Python 重构任务,Claude 花了 8 分钟给出了一个企业级解决方案,ChatGPT 在 5 分钟内完成,但结果中有三个 bug,而 Gemini 则在 2 分钟内提供了结果,属于能运行就行的类型。
三大巨头的独特性
先给大家分享一个有趣的现象,最新的 Stack Overflow 调查显示,84% 的开发者在使用 AI,但只有 3% 的人表示“高度信任”。
这个数据看似奇怪,但是想想自己每天调试 AI 生成的代码到崩溃,也确实是如此。
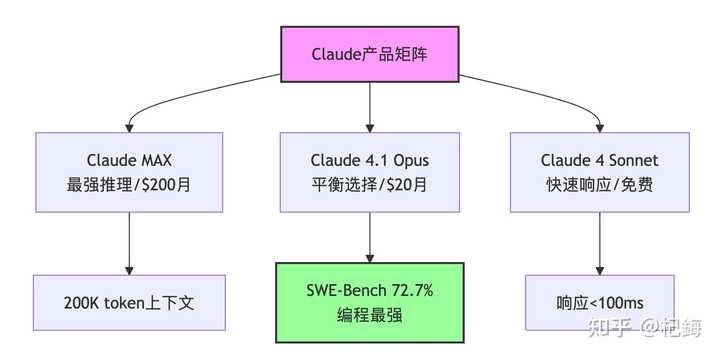
Claude:代码世界的“完美主义者”
提到 Claude,我首先想到的是“昂贵”,其次是“真不错”。
Anthropic 公司非常有趣,其创始人均为 OpenAI 的前成员,传言是由于理念不合而离开——他们想要打造更“安全”的 AI。
从事技术工作的人都知道,所谓的 Constitutional AI 并不是一个虚幻的营销概念,而是背后有实质内容的。
简单来说,它的训练过程可以用以下公式来表示:
其中 表示监督学习损失,
则是基于“宪法约束”的强化学习损失。通俗来说,它不仅学习如何回答问题,还学习哪些问题是不能回答的。这个 $lambda$ 权重系数相当有趣,听说 Anthropic 调试了几个月才找到最佳值(大约在 0.3-0.5 之间)。
个人认为 Claude 最出色的地方在于它的 Constitutional AI,换句话说,它具备“自我审查”的能力。
上个月我让它帮我编写一个爬虫,它竟然会提醒我注意 robots.txt 及法律风险——虽然有时让人觉得烦恼,但至少不会像某些 AI 那样什么都敢写。
顺便提一下,Reddit 上的 Python 社区已经炸开了锅,大家纷纷表示“Claude 写 Python 完胜 GPT”。
经过我自己的测试,确实在 Django 和 FastAPI 框架下,Claude 的代码质量令人惊叹。
这与位置编码的问题密切相关。Claude 采用了旋转位置编码(RoPE):
这种编码方式在处理长代码文件时的优势显著,相对位置信息得以更好地保持。而 GPT 系列仍在使用传统的正弦位置编码:
当代码超过 8K tokens 时,性能差异便显而易见。我处理一个 15K 行的项目时,Claude 能够准确识别函数调用关系,而 GPT- 4 却常常混淆。
ChatGPT:通用选手
相比之下,OpenAI 这边则热闹得多。
从 GPT-3.5 到如今的 GPT-5(今天大家已经在讨论,这是否是降智之举,甚至不如开放源代码的方案),其更新速度快得令人心痛。
你们知道 GPT 系列的核心是什么吗?其实它的本质就是自回归语言建模,数学原理相对简单:
OpenAI 的多头注意力机制才是真正的技术创新:
这个  的缩放因子至关重要。如果没有它,梯度会出现爆炸。有一次我自己实现 Transformer 时,忘了加这个,loss 直接飙升到 nan,调试了整整一个下午才找出问题。
的缩放因子至关重要。如果没有它,梯度会出现爆炸。有一次我自己实现 Transformer 时,忘了加这个,loss 直接飙升到 nan,调试了整整一个下午才找出问题。
最新数据显示,ChatGPT 拥有超过 7 亿的周活跃用户,市场份额达到 60.5%,稳坐行业老大。不过,开发者社区已经开始“叛变”,像 Cursor IDE(不允许国内使用 Claude)和 Aider 等主流工具纷纷将默认模型切换为 Claude。
不同实现风格下的相同需求
ChatGPT 的优势在于其生态系统,GitHub Copilot 的用户数量达到 2000 万,其中 130 万为付费用户。
然而,诚实地说,GPT5 的幻觉率相对较高,有人甚至认为其表现不如 20B 的开源 OSS,而另一些人则认为其使用了“降智版”,这真是令人费解。
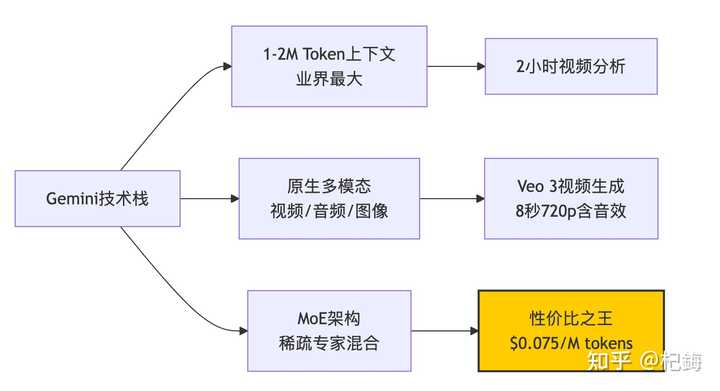
Gemini:低调而强大的竞争者
Google 的 Gemini 表现得相当低调,但其价格优势不容忽视!
Gemini Flash 的成本仅为每百万 token $0.10,价格比 Claude 低 150 倍!
从技术角度来看,Gemini 最引人注目的特点是其 MoE(专家混合)架构。在推理过程中,并非所有的参数都被激活,而是通过门控机制选择活跃的专家:
门控函数 $G(x) = text{softmax}(W_{gate} cdot x + b)$ 决定了激活哪些专家。这也是 Gemini 能够在保持庞大模型(1.8T 参数)的同时,每次只激活大约 200B 参数的原因。
不过,这里有一个挑战,负载平衡至关重要。Google 引入了一个辅助损失函数:
表示专家 $i$ 的使用频率,
则是其容量。设置不当的
系数可能导致某些专家过载,直接影响性能。我在我的项目中尝试过类似的架构,这个参数调试花了我整整两周 …
实话说,上周我使用 Gemini 分析了一场持续两小时的技术讲座视频,它能准确指出某个概念在讲座中的具体时间。这种能力是其他两个竞争者目前无法比拟的。
然而,Gemini 也存在一些不足之处:
编程能力对比:我的实测数据
作为一名程序员,我最关心的无疑是编写代码的能力。我进行了一个“创建俄罗斯方块游戏”的测试,结果非常有趣。
在查看结果之前,首先需要理解这些模型是如何“理解”代码的。其本质是将代码进行 token 化,然后计算上下文的相关性:
这个前馈网络(FFN)的隐藏维度通常是模型维度的四倍。Claude 使用的是 8192 维,因此 FFN 的维度为 32768——这就是它在理解复杂代码结构方面表现出色的原因。
基准测试成绩单(2025 年 1 月数据)
Claude 生成的代码不仅包含完整的错误处理,还包括单元测试,甚至提供了性能优化的建议。
ChatGPT 的代码更为简洁易懂,非常适合用于教学。
至于 Gemini,它的生成速度非常快,仅需 2 分钟,虽然界面稍显简陋。
不同编程语言的表现差异
Python 生态:Claude > ChatGPT > Gemini
- Claude:在 Django 和 FastAPI 方面表现出色
- ChatGPT:在数据科学库(如 pandas 和 numpy)方面更为强劲
- Gemini:适合编写简单脚本
JavaScript/TypeScript:ChatGPT ≈ Claude > Gemini
这点让我颇感意外,可能是由于 GitHub 上 JavaScript 项目数量最多,ChatGPT 的训练数据相对丰富。上次我编写 React 组件时,ChatGPT 提供的 hooks 用法确实更加地道。
系统编程(C++/Rust/Go):Claude >> ChatGPT > Gemini 在内存管理方面,Claude 的表现简直是降维打击。有一次我调试一个 use-after-free 的 bug,只有 Claude 准确指出了问题所在。
多媒体能力:各有千秋
在这一领域,Gemini 的表现突然令人眼前一亮。
图像生成对比
- ChatGPT + DALL-E 3:艺术感最强,特别适合创意设计
- Gemini + Imagen 3:生成的图像更为真实,并采用了 SynthID 水印技术
在上个月制作 PPT 时,我发现 ChatGPT 所生成的配图确实更具 ” 艺术感 ”,而 Gemini 生成的图像则更适合于正式场合的需求。
视频处理(Gemini 的独特优势)
Gemini 的 Veo 3 表现十分出色,能够在 2 分钟内生成 8 秒的 720p 视频,并且附带音效,现已整合进 YouTube Shorts,真是内容创作者的一大助力。尽管 OpenAI 的 Sora 在质量上更为出色,但所需的等待时间让我觉得 … 足够我做一个简单的版本了。
成本分析:钱包的哭泣
让我们来算一笔账,假设一个 10 人团队每月处理 10M tokens。
先普及一下 token 的计算方法,通常来说:
对于中文而言,每个汉字平均占用 1.5 到 2 个 tokens。因此,撰写中文文档的成本相对较高,我通常是先用英文指令,然后再进行翻译。
成本优化有一个经典的公式:
其中的 Retry Rate 至关重要,若模型频繁产生无用输出需要重试,实际成本将可能翻倍。
根据我的统计,Gemini 的重试率约为 15%,而 Claude 则约为 5%。从长远来看,Claude 的使用反而能节省开支。
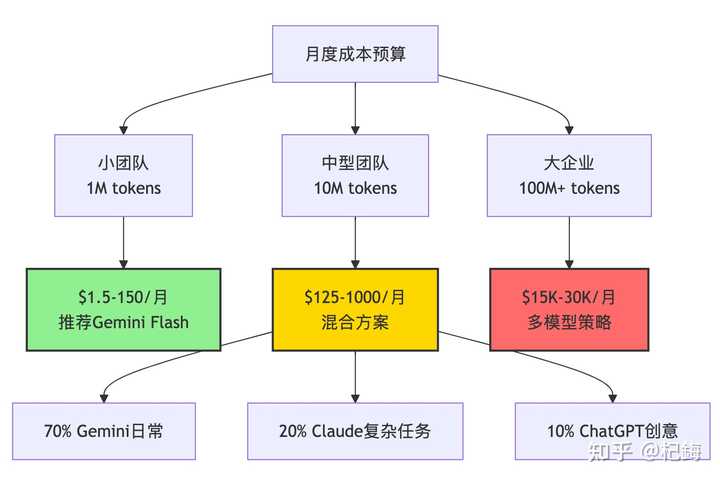
个人开发者:
- 预算充足:选择 Claude Pro($20/ 月)并偶尔使用 ChatGPT
- 预算有限:Gemini 的免费版(每月提供 18 万次补全!)
- 折中方案:ChatGPT Plus($20/ 月),通用性最佳
企业选择:必须提到的是,43% 的企业员工使用两个以上的 AI 工具。我们团队的策略是:
- 核心代码:使用 Claude(虽然价格高,但物有所值)
- 日常查询:选择 Gemini(成本低且量大)
- 创意文案:依赖 ChatGPT(无可替代)
安全性考量:被忽视的重要因素
自从 o3 模型的幻觉率达到 48% 的消息曝光后,大家开始重视这个问题(GPT5 发布后还未得到充分使用,不太清楚其情况)。
根据 Vectara 的测试结果:
- Gemini 2.0 Flash:幻觉率为 0.7%(最低)
- Claude 4 系列:约为 2 -3%(受益于 Constitutional AI 的支持)
- ChatGPT GPT-4.1:5-8%(算是可以接受的范围)
- OpenAI o3/o4:达到了 33-48%(翻车现场)
幻觉率的计算方法其实是衡量模型输出的条件概率分布与真实分布之间的差距:
Claude 低幻觉率的原因在于其 RLHF 优化目标的不同:
其中的 Constitutional Score 至关重要,它会对不安全或不准确的输出进行惩罚。
我曾测试过同样的医疗问题,Claude 会表示 ” 我不是医生,建议咨询专业人士 ”,而某些模型则会随意编造治疗方案。
在医疗、法律等领域,还是应该老老实实选择 Claude,为什么呢?
因为 Claude 所依据的是实际数据,而大多数 GPT 模型则是闭门造车。
我见过用 ChatGPT 撰写合同条款的结果,结果被法务团队痛批。
Gemini 在这一点上也表现出色,广泛使用网络数据。
2025 年最新动态与趋势
技术更新节奏(持续关注中)
- 2025 年 8 月:发布 Claude 4.1 Opus,采用混合推理模式
- 2025 年 3 月:Gemini 2.5 Pro 新增 ” 思考 ” 功能
- 2025 年 8 月:OpenAI 发布 GPT5 推理模型(使用需谨慎)
谈到响应速度,这里面的学问可不少。推理速度主要受以下公式的影响:
Gemini Flash 每秒可以达到 200+ tokens,秘诀在于其稀疏激活——实际的 FLOPS 需求仅为密集模型的 1 / 8 左右。而 Claude 的深度思考模式则会增加额外的 ” 思考 token”:
这个 Thinking 部分可能是 Output 的 3 到 5 倍,因此看起来比较慢,但准确性却显著提升。
我测试过一个算法题,启用思考模式后,错误率从 12% 降到了 2%。
开发者生态的变化
有一个很有趣的趋势:主流开发工具正在逐渐 ” 去 OpenAI 化 ”。Cursor 默认使用 Claude,Continue 支持多种模型,甚至微软自家的 VS Code 也开始支持 Gemini 了。
从信息论的角度来看,多模型策略实际上是在优化信息熵:
单一模型的输出熵是固定的,但组合多个模型可以降低整体的不确定性。
这就是为什么 43% 的企业采用多模型策略——这并非盲目跟风,而是确实有效。
我认为这反映出一个事实:没有一种万能的 AI,只有适合特定场景的 AI。
我的使用策略(持续优化中)
经过无数次的尝试,我现在的工作流程如下:
开发阶段的分工
探索 AI 工具的最佳配置与应用场景
具体应用场景的选择
紧急修复 bug:使用 Gemini 来快速定位,然后通过 Claude 进行验证。
重构旧代码 :Claude 擅长此类任务,尤其是针对遗留代码的处理。
撰写技术方案 :可先由 ChatGPT 进行初步起草,再交给 Claude 进行审核。
处理大文件 :Gemini 能够处理大约 2M 的 token 上下文。
面试算法题:选择 Claude,因为它能够提供清晰的思路。
一些初步的建议
经过一段时间的探索,我总结了以下几点心得:
- 不要过于依赖基准测试:尽管 SWE-Bench 的 72.7% 听起来很不错,但实际应用中可能会遇到问题。
- 综合考虑成本:虽然 Claude 的价格较高,但若能节省调试时间,实际上是划算的。
- 保持怀疑态度:对 AI 生成的代码必须进行审查,尤其是在并发和内存管理方面。
- 多模型的使用是未来趋势:到了 2025 年,仍在纠结使用单一模型,不如学习如何组合使用各个模型。
最后,分享一个趣事:上周一位新加入的同事(也是动漫爱好者)问我“哪个 AI 最好”,我幽默回答:“佐为就在你的棋盘里。”
这句话的意思是,你最优秀的 AI,实际上就在你的代码之中~
推荐的资源与工具
官方文档
- Claude 官方文档
- OpenAI API 文档
- Google AI Studio(非专属地区,无法享受免费额度)
基准测试平台
- Chatbot Arena 排行榜
- SWE-Bench 官方网站
- Vectara 幻觉率测试
社区讨论
- r/LocalLLaMA – 模型对比的讨论平台
- Twitter #AIEngineering – 实时信息更新