
共计 1219 个字符,预计需要花费 4 分钟才能阅读完成。
作者/观察者网 周毅 编辑 张广凯
在5月14日,腾讯对外宣布其混元文生图大模型已完成全面升级,并正式开源。这一模型被认为是行业内首个中文原生的DiT架构文生图开源项目。它具备中英文双语输入和理解的能力,参数量达到15亿。目前,该模型已在Hugging Face平台和Github上发布,用户可以获得包括模型权重、推理代码和算法在内的完整资源,供企业及个人开发者免费使用。
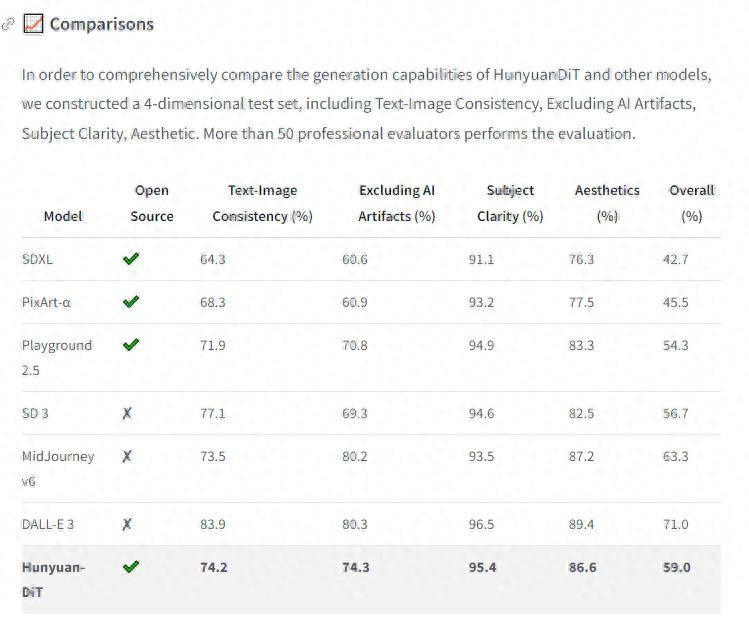
不同模型在图文一致性等方面的表现 图源Hugging Face
腾讯混元文生图项目的负责人芦清林在接受观察者网采访时指出,未来该大模型的发展将集中在提升技术能力和拓展应用范围两个方面。
“在技术能力提升方面,我们始终追求更快的图像生成速度和更优质的生成效果,这似乎是一个无止境的追求。”芦清林进一步表示,团队希望该模型能在腾讯内部及外部的多个业务场景中得到广泛应用。实际上,自去年以来,腾讯混元文生图已经与公司的广告业务展开了一系列合作。
“今年,我们计划与社交业务合作,包括QQ和企业微信等多个业务场景,开发新的技术能力。”芦清林透露。此外,该大模型也将与腾讯游戏进行深入的技术合作,力求在美术创作等场景中实现应用,包括QQ音乐等未来业务场景的支持。
大模型的优异性能往往源于其先进的技术架构。以前,视觉生成扩散模型主要基于U-Net架构,但随着参数量的增加,基于Transformer架构的扩散模型展现出更出色的扩展性,能够显著提升生成质量与效率。经过升级,腾讯混元文生图大模型采用了全新的DiT架构(即Diffusion With Transformer),这一架构同样是Sora和Stable Diffusion 3所使用的关键技术之一,基于Transformer的扩散模型。
根据公开资料,腾讯混元文生图大模型在DiT架构的基础上,还在算法层面进行了优化,增强了长文本的理解能力,能够支持最多256个字符的输入,并具备多轮生成和对话能力:用户可以通过自然语言描述,对初始生成的图像进行调整。

用户通过“对话”可调整文生图的具体内容 测试截图
此外,腾讯混元文生图大模型的“中文原生”特性同样值得关注。之前,像Stable Diffusion等主流开源模型的核心数据集主要以英文为主,导致对中国语言、美食、文化和习俗的理解相对有限。作为首个中文原生的DiT模型,混元文生图在中英文理解及生成方面表现卓越,尤其在古诗词、俚语、传统建筑和中华美食等中国文化元素的生成上展现出色的能力。

混元文生图大模型的一部分能力展示 图源Hugging Face
本文系观察者网独家稿件,未经授权,不得转载。









