共计 2153 个字符,预计需要花费 6 分钟才能阅读完成。
澎湃新闻记者 孔家兴 王亚赛 实习生 梁希昀
全球领先的文生图AI企业Midjourney,近期遭遇了一场来自“宇宙最强法务”的诉讼风波。
据央视新闻报道,在当地时间6月11日,全球娱乐业巨头迪士尼和环球影业联合对Midjourney提起了版权诉讼。两家公司在诉状中明确指出,Midjourney被视为一个“借用版权进行抄袭的深渊”。
“宇宙最强法务”深究提示词,强调“像素级”侵权问题
这份长达110页的诉状详细列举了多个Midjourney生成的图像与原版影视素材之间的对比,涉及迪士尼和环球影业旗下多个知名知识产权,如星球大战、蜘蛛侠、辛普森一家、冰雪奇缘和小黄人等。
通过对诉状中提到的侵权图像提示词的分析,澎湃新闻记者发现,当使用“电影截图”、“截屏”等关键词时,Midjourney能够生成与原版画面高度相似的场景、构图、背景及人物细节。同时,一些举证提示词展示了图像风格与角色IP之间的紧密联系。例如,输入“Homer Simpson, animated”(霍默·辛普森,动画风格)可以让Midjourney生成与辛普森一家相同的动画风格,而不产生其他的动画风格。
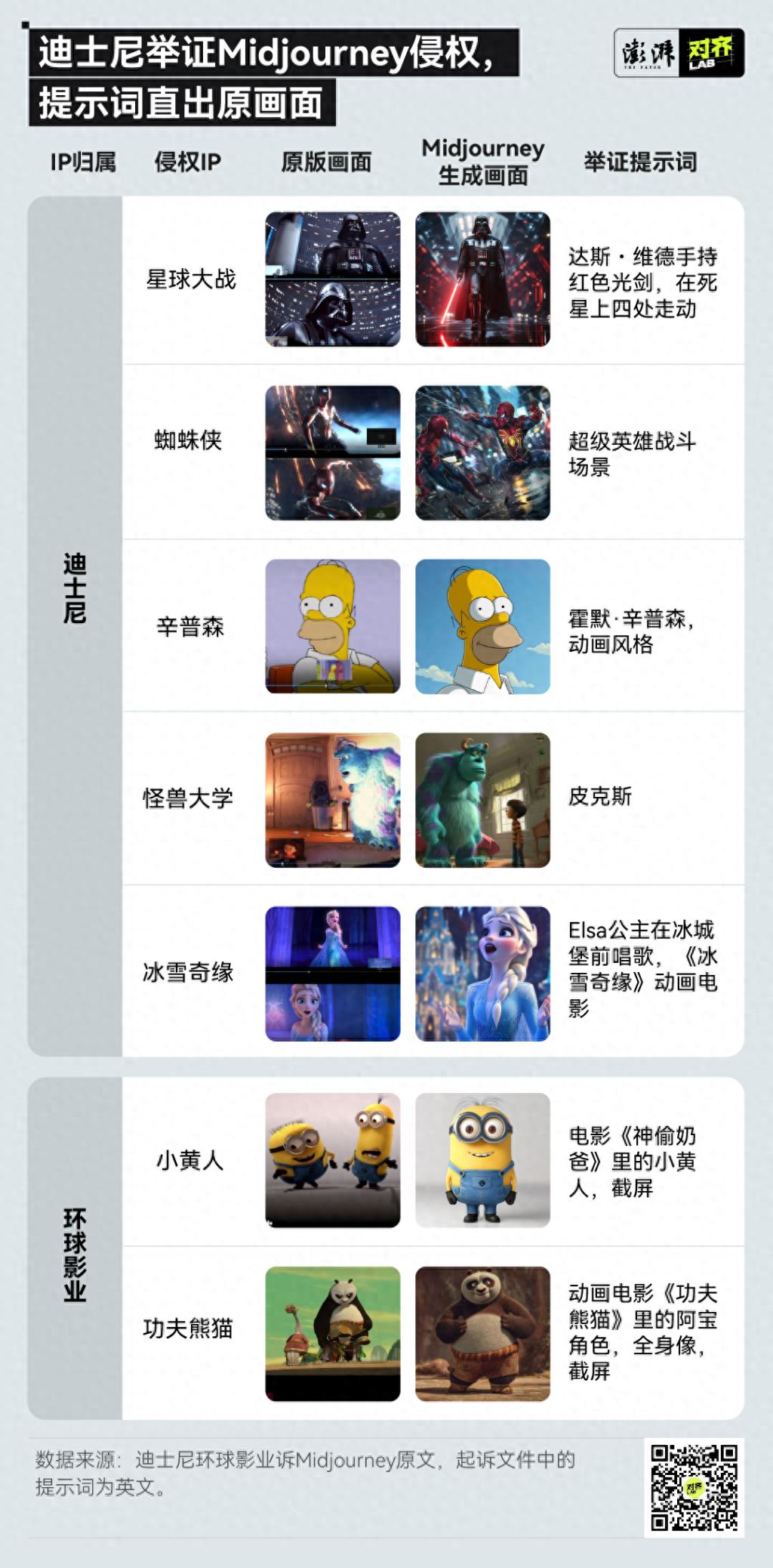
分析提示词和对比图像的目的,正是为了让迪士尼和环球影业能够证明Midjourney在训练人工智能模型时,广泛使用了两家公司的版权素材。诉状中提到,Midjourney的首席执行官大卫·霍尔茨在2022年接受《The Verge》采访时表示,他们几乎抓取了互联网上的所有图像和文本以进行模型训练。而在接受《福布斯》采访时,大卫·霍尔茨也表示,Midjourney在未曾获得任何版权许可的情况下使用这些作品,并将此问题归因于大量图片无法追溯到具体作者。
上海大邦律师事务所的高级合伙人游云庭在接受澎湃新闻采访时指出,人工智能的训练数据版权问题相当复杂,主要体现在两个方面:未经授权的训练素材及输出内容的潜在侵权。关于训练素材,许多都是未经授权的盗版,而输出内容可能与他人的版权作品相似,甚至与用于训练的原始内容高度相似。
人工智能公司通常认为,经过大模型训练后生成的内容在某种程度上与原始素材有所不同,创造了新的价值,因此将这种转变视为合理使用,不构成侵权。然而,游律师认为从法律角度来看,这一主张存在较大争议,因为合理使用的前提是不得以不当方式损害著作权人的合法权益,并且不得妨碍作品的正常使用。
目前围绕训练过程是否构成侵权的问题争议颇多。如果最终认定训练不属于合理使用,那么现有的人工智能公司将面临一系列挑战。首先,需向版权方支付相应费用,其次,版权方有权要求人工智能公司将其数据从模型中移除,而这一技术实现面临巨大的难度,可能造成的损失甚至超出巨额赔偿的损失。
据不完全统计,迪士尼和环球影业在诉状中指出,其被侵权的IP超过15个,累计全球收入超过1738亿美元。根据界面新闻的报道,迪士尼高级执行副总裁兼首席法律与合规官霍拉西奥·古铁雷斯表示:“我们的世界级IP是基于数十年的投资、创意和创新建立的,盗版就是盗版,AI公司的行为并不会减轻其侵权的性质。”

奥特曼侵权案后,部分公司限制AI生成IP内容
在数据训练输入端,AI侵权问题仍存在诸多争议,目前国内外相关的司法判例较为稀缺。但在输出内容的侵权认定方面,已经出现了一些具有代表性的司法案例。
2024年2月,广州互联网法院就Tab网侵权案作出判决,认定被告提供的AI生成服务侵犯了原告IP“奥特曼”,构成著作权侵权。这是全球首个生成式AI服务侵犯他人著作权的有效判决。
该案的争议焦点在于被告使用的AI绘画工具是否构成著作权侵权。通常认为,法律认定著作权侵权需同时满足“接触”和“实质性相似”两个条件。判决书表明,被告提供的AI绘画功能能够根据用户指令(提示词)生成对应的图片,如用户输入“生成一个奥特曼”,便能生成奥特曼的形象。法院在审理后认为,生成的图片保持了美术形象的独创性表达,并在多个关键特征上与作品具有极高的相似度,构成实质性相似。
游云庭律师表示,在“奥特曼案”判决后,部分AI公司已经在提示词中对奥特曼进行了限制,无法生成相关的图片。这一变化恰恰表明,AI公司在输出端有能力限制侵权行为,只是问题在于是否愿意去做。
经过澎湃新闻记者的实地测试,我们发现一些平台如豆包、即梦和通义千问在生成内容时出现“无法生成”或“不符合平台规定”的提示。反观OpenAI、Gemini和可灵等平台,仍然能够顺利生成相关形象。值得注意的是,尽管OpenAI对“奥特曼”进行了某种程度的限制,但对于具体角色并未完全禁止,例如输入“迪迦”时依然可以生成相关图像。
在“奥特曼”案件中,原告向法院索赔30万元,最终获得了1万元的赔偿。广东互联网法院在其判决书中指出,“鉴于生成式人工智能产业仍处于发展初期,必须兼顾保护权利与产业发展,因此不应过于苛责服务提供者的责任。”
本期编辑 邢潭