共计 5177 个字符,预计需要花费 13 分钟才能阅读完成。
编辑:编辑部
【新智元导读】卷土重来,谷歌最新发布的文本生成图像AI模型Imagen 2,展现出无与伦比的真实感,生成的女性图像如同真实照片,提示词的再现能力已超越DALL·E 3与Midjourney!这是否意味着文生图领域的霸主即将更替呢?
你是否能分辨出,下面这幅图是由AI生成的还是一张真实的照片呢?

如果不问,很多人或许根本不会猜到,这其实是一幅AI生成的图像。
确实,只需在谷歌最新的AI图像生成工具Imagen 2中输入相应的提示语——
A shot of a 32-year-old female, up and coming conservationist in a jungle; athletic with short, curly hair and a warm smile
一位32岁的女性自然保护者,正在丛林中探险。她身材健美,短卷发,面带温暖微笑。
就能生成那幅极为真实的图像,甚至比照片还要生动!
尽管圣诞节即将到来,谷歌的创新步伐却依旧加速——被誉为DALL·E 3最强对手的文本生成图像模型Imagen 2,终于重磅发布。
在刚刚与Gemini和OpenAI的GPT-4竞争之后,谷歌便迅速推出Imagen 2,显然2023年末的“卷王”称号非其莫属。

不仅指尖栩栩如生,握筷子的姿态同样标准
毫无疑问,Imagen 2已成为当今文本转图像技术的顶尖之作,突破了以往的AI图像生成界限。
在强大的机器学习算法支持下,Imagen 2能够将文本描述转化为生动、清晰的高分辨率图像。
其最大的亮点在于,Imagen 2以惊人的精确度理解复杂的抽象概念,并将其转化为可视化的图像,细腻程度令人叹为观止!

Imagen 2的基础依旧是复杂的神经网络。经过优化的Transformer模型在理解文本和生成图像方面展现出了卓越的性能。
如今,谷歌在文生图领域树立了崭新的标杆。
又一个能够通过自然语言生成图像的模型问世了
除了DALL·E 3外,我们又迎来了一个仅需自然语言便可生成图像的新模型!
相比之下,Midjourney需要使用复杂且专业的提示词,因此在用户友好性方面已被这两位竞争者远远甩在了身后。
仅需简短的文本描述,就能生成多样且复杂的图像。这类AI生成图像的模型对内容创作的影响深远。
对于那些依赖视觉内容的行业,这无疑是规则的颠覆,显著缩短了传统内容制作所需的时间,创作者可以以史无前例的速度生成高质量的视觉效果。

此外,Imagen 2在图像质量和多样性方面也展现了无与伦比的优势。
它利用了谷歌最新的文本到图像扩散技术,不仅生成的图像质量极高,效果也极为真实,且与用户输入的提示高度一致。
Imagen 2:颠覆传统的图像生成技术其之所以能够如此,源于它利用训练数据的自然分布来创造出更加真实的图像,而不是依赖于事先设定的样式。

水母在深蓝色的背景下悠然漂浮
A jellyfish on a dark blue background
我们不难发现,Imagen 2在图像生成方面的能力是极为惊艳的。
无论是精细的场景渲染,还是细致的物体表现,甚至是梦幻般的画面,其生成的图像都展现出极高的真实感,能够与人类艺术家的作品相媲美,甚至在某些方面超越它们。

一小幅油画,描绘了摆放在砧板上的橙子。阳光穿过橙子的切片,柔和的橙色光线洒在砧板上。画的背景是一块蓝白相间的布,画面巧妙地捕捉了光的折射、反射效果,同时展示了画家富有感情的笔触
Small canvas oil painting of an orange on a chopping board. Light is passing through orange segments, casting an orange light across part of the chopping board. There is a blue and white cloth in the background. Caustics, bounce light, expressive brush strokes
有网友评论道,看到Imagen生成的橙子图像,令我感到十分惊讶。灯光透过橙子的投影,与描述中的意境完美契合!

有网友表示,使用相同的提示词,DALL·E 3生成的橙子油画相比Imagen 3而言,效果显得逊色不少。

同样,Midjourney生成的橙子在真实感和氛围层面上,也显得稍有不足。

诗意的境界,生动地再现
以往的“文本生成图像”模型,通常是依据训练数据集中的图片以及文本内容,生成与用户输入相符的图像。
然而,这些模型存在一个问题:每幅图像与其对应的标题在细节的质量和准确性上可能存在显著差异。
为了提升图像的质量和准确度,更好地适应用户的需求,Imagen 2的训练数据集加入了更多的描述信息,助力其学习不同的标题风格,更加深入理解各种用户提示。
这种图像与标题的配对,有助于Imagen 2更准确地把握图像与文字之间的关联,大幅提升其对上下文和细微差别的理解能力。
例如,美国作家Phillis Wheatley在《晚间赞美诗》中提到的“溪水潺潺,鸟儿啁啾,空中弥漫着它们的和声”。
这句诗中所蕴含的绝美意境,Imagen 2将其要点完美捕捉。

“溪水轻声流动,鸟儿重新歌唱,和谐的旋律在空中飘荡。”(Phillis Wheatley的《晚间赞美诗》)
与此相比,Midjourney在文学描绘的理解上似乎稍显不足,常常会在生成的图像中添加人物角色。不过,整体视觉效果依然令人满意。

而在DALL·E 3的生成作品中,它竟然为图像添加了几行文字,创造出了一张“贺卡”!

在赫尔曼·梅尔维尔的经典小说《白鲸记》中,他曾描绘道:“想象一下海洋的微妙之处,最为恐怖的是生物们在水下滑行,往往难以被察觉,且神秘地隐藏在最美丽的蓝色之下。”
显然,Imagen 2对“海洋文学”的深刻内涵也有着独到的理解。
深海与文学:探索不可见的恐惧与美丽
“细想海洋的微妙,最为可怕的生物在水下悄然滑行,常常不易觉察,它们神秘地隐藏在最美丽的蓝色之下。”(出自赫尔曼·梅尔维尔的《白鲸记》)
与此形成鲜明对比的是,Midjourney和DALL·E 3在探索深海时,瞬间变得充满克苏鲁风格……

Midjourney

DALL·E 3
在儿童文学泰斗弗朗西斯·霍奇森·伯内特的《秘密花园》中,有关知更鸟的描述极具诗意:
知更鸟展翅飞越缠绕的常春藤,站在墙头上,开口吟唱出悦耳动人的旋律,宛如在炫耀自己。世间没有比它更可爱的生物了——它们几乎总是如此。
请看,Imagen 2创作的这幅画,生动展现了常春藤、墙头及歌唱等细腻的细节,令人叹为观止。

“知更鸟从常春藤的摇曳枝条飞起,落在墙头,张嘴唱出动听而响亮的旋律,似乎只是为了炫耀自己。没有什么比这只知更鸟更可爱了,尤其是在它展示的时候——而它几乎总是如此。”(《秘密花园》,弗朗西斯·霍奇森·伯内特)
同样的提示词,在真实感的表现上,Midjourney依旧略显不足。

而与前面提到的两者相比,DALL·E 3在细节表现上更显逊色,特别是在植物和羽毛方面。

风格重塑,轻松切换,更加贴近人类的审美。
图像生成一直以来都存在一个广受诟病的问题,那就是人物手指的生成质量。
不过,这次Imagen 2在数据集和模型方面的提升,使得多个领域得到了显著优化。
这其中包括对手部和面部的真实渲染,以及确保视觉效果不受干扰的伪影处理。
与此同时,谷歌DeepMind依据人类对光照、构图、曝光和清晰度等方面的喜好,开发了一个专门的“图像美学模型”。
Imagen 2的美学评分与图像生成能力提升每一幅图像都被赋予了一个美学评分,这一机制可以帮助Imagen 2在其训练数据中,为人类更倾向的图像分配更多的优先权。
由此,Imagen 2在生成高质量图像方面的能力得到了显著增强。

使用提示“花”生成的AI图像,其美学评分从左侧的低分到右侧的高分。
Imagen 2的扩散技术展现了极高的灵活性,使得图像风格的控制和调整变得更加简单。
通过结合文本提示和参考风格图像,Imagen 2可以生成与之相符的新图像。

采用参考图像与文本提示,Imagen 2能更轻松地掌控输出的风格
更强大的「修复」与「扩图」功能
此外,Imagen 2还具备图像编辑的能力,包括「修复」(inpainting)和「扩图」(outpainting)等功能。
通过提供参考图像与掩码,我们能够运用inpainting技术直接在原图上生成新的内容。
例如,在下面的原始图像中,只需输入“绿色墙上有一个架子,上面放着几本书和花瓶”,相关内容便得以在原图中生成!
新添加的内容与原图毫无违和感,自然融入,宛如天成。
重塑视觉体验:Imagen 2的强大功能解析

此外,我们还可以利用outpainting功能对原图进行扩展,创造出全新视觉效果。
例如,夕阳映照下的非洲大草原,长颈鹿与斑马的合影瞬间转化为全身照。

为企业场景提供全面支持,能够一键生成logo及文案,中文内容也能处理
目前,谷歌已将Imagen 2引入开发者平台Vertex AI。
在Vertex AI上,用户可以利用直观的工具,轻松自定义与部署Imagen 2,享受全面管理的基础设施以及内置的隐私与安全保护功能。
凭借谷歌DeepMind的技术支持,Imagen 2在图像质量方面得到了显著提升,帮助开发者根据特定需求生成图像,包括:
– 根据自然语言提示制作高分辨率、真实且精美的图像;
– 支持多种语言的文本渲染,可以在图像中准确插入文本内容;
– 设计并嵌入公司或产品的Logo到图像中;
– 提供视觉问题的解决方案,可以从图像生成标注,或对图像细节提出问题并提供有意义的文本回答。
卓越的图像质量:通过改进图像和文本理解能力,加上多种创新的训练与建模技术,Imagen 2能生成高精度、高品质且逼真的图像。

文本渲染功能:该系统能够依照输入提示,准确地生成所需文本。
当Imagen 2创建包含特定文字或短语的图像时,它能确保生成的图像中包含正确的短语。

Logo创意:Imagen 2可以为各类品牌和产品设计出多样化且真实的Logo设计,包括徽章、字母或极具创意的抽象Logo。

标注与问答功能:凭借增强的图像理解能力,Imagen 2能够生成详细的长文本标注,并能针对图像内部元素的问题提供详尽的回答。
多语言支持:除了英语外,Imagen 2还支持包括中文、印地语、日语、韩语、葡萄牙语和西班牙语在内的六种语言,并计划于2024年初增加更多语言选项。此外,它也具备提示和输出之间的翻译功能,用户可以使用西班牙语进行提示,而输出则为葡萄牙语。
加水印生成图像,增强安全性
为了减少文本到图像生成技术可能带来的风险和挑战,谷歌在设计、开发到产品部署的各个环节都设置了严格的防护措施。
谷歌推出Imagen 2:全新AI图像处理技术的突破Imagen 2融入了SynthID,这是一个尖端的工具包,专门用于为AI生成的内容添加水印及识别。
因此,Google Cloud的用户能够在不影响图像质量的情况下,直接在其图像中嵌入数字水印。
即便图像经过了剪裁、滤镜处理或采取了有损压缩,SynthID依然能够进行有效的检测。

此外,在向大众发布之前,谷歌会进行全面的安全测试,以尽量降低潜在的风险。
从项目初期,谷歌团队便致力于Imagen 2的数据安全训练,并建立了技术屏障,以屏蔽不当输出,例如暴力、侮辱或色情内容。
与此同时,谷歌还对训练数据、输入提示和系统生成的结果进行了严格的安全审查。例如,正在实施全面的安全过滤机制,以防止生成潜在问题的内容,如名人图像。
网友们纷纷表示:真正的最强文生图模型终于登场了!
Google DeepMind的研究副总裁兼深度学习主管Oriol Vinyals,尝试利用Imagen 2为Gemini设计徽标。



以下是另一位来自谷歌的科学家使用Imagen 2生成的图像。

接下来是一只网友亲自测试生成的蓝色猫咪。

有网友认为,Imagen 2在同类产品中表现优秀,和Gemini Ultra一样,观察手部和文字就足够了。
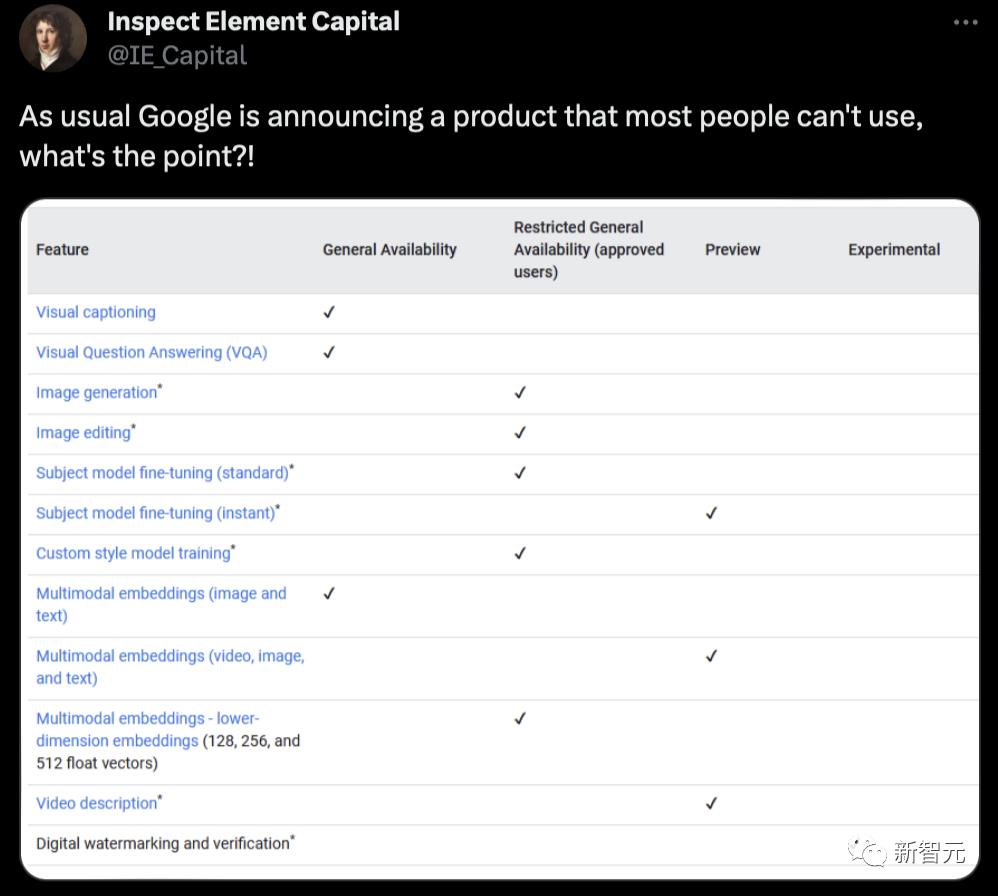
不过,他也对谷歌未向所有用户开放该产品表示了不满。

“谷歌又推出了一款大多数用户无法体验的产品,这到底有什么实际意义呢?!”
资料来源:
https://deepmind.google/technologies/imagen-2/
https://cloud.google.com/blog/products/ai-machine-learning/imagen-2-on-vertex-ai-is-now-generally-available