共计 6502 个字符,预计需要花费 17 分钟才能阅读完成。
机器之心报道
编辑:杜伟、陈陈
在短短一夜之间,国产大模型成功夺取了文生图领域的最高荣誉!
这次的焦点是腾讯混元团队推出并开源仅一周的原生多模态生图模型——混元图像 3.0(HunyuanImage 3.0)。
在全球知名的AI模型评测平台LMArena上,HunyuanImage 3.0 轻松超越了谷歌的Nano-Banana和字节的Seedream 4.0,荣登文生图(Text-to-Image)综合排名及开源榜单的首位。
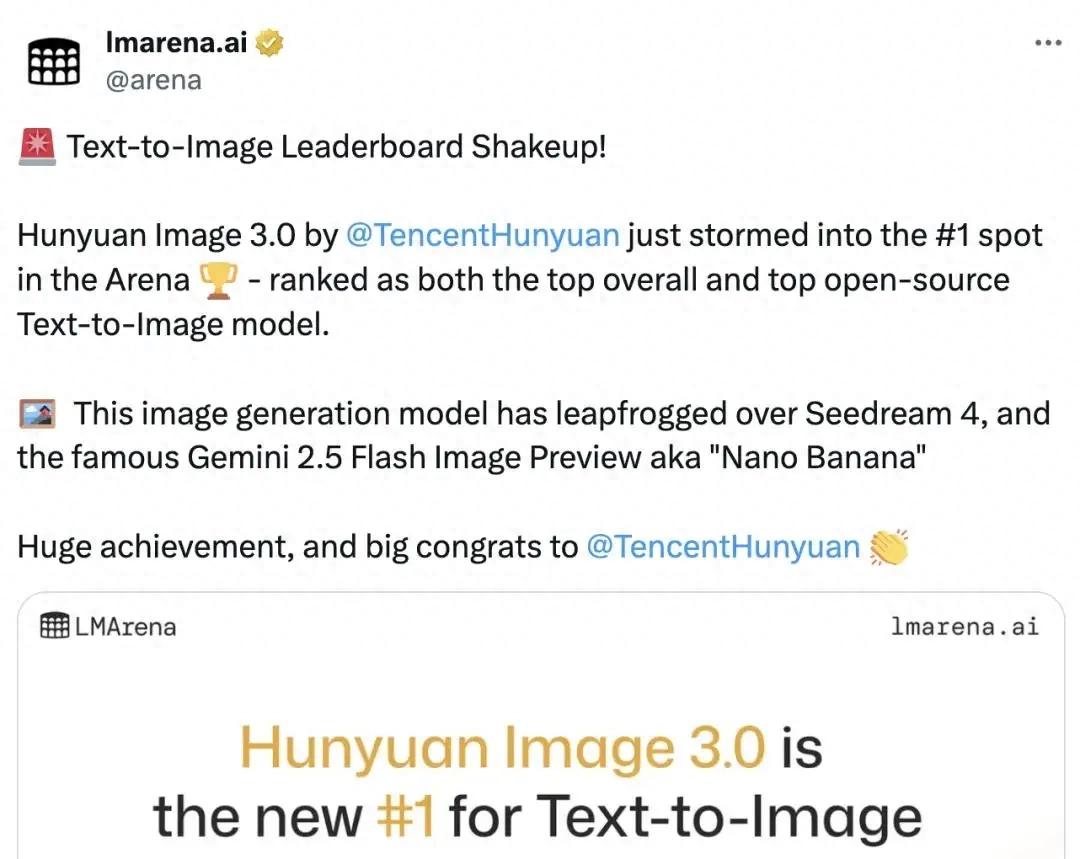
以下是LMArena文生图的完整(Overall)排行榜:
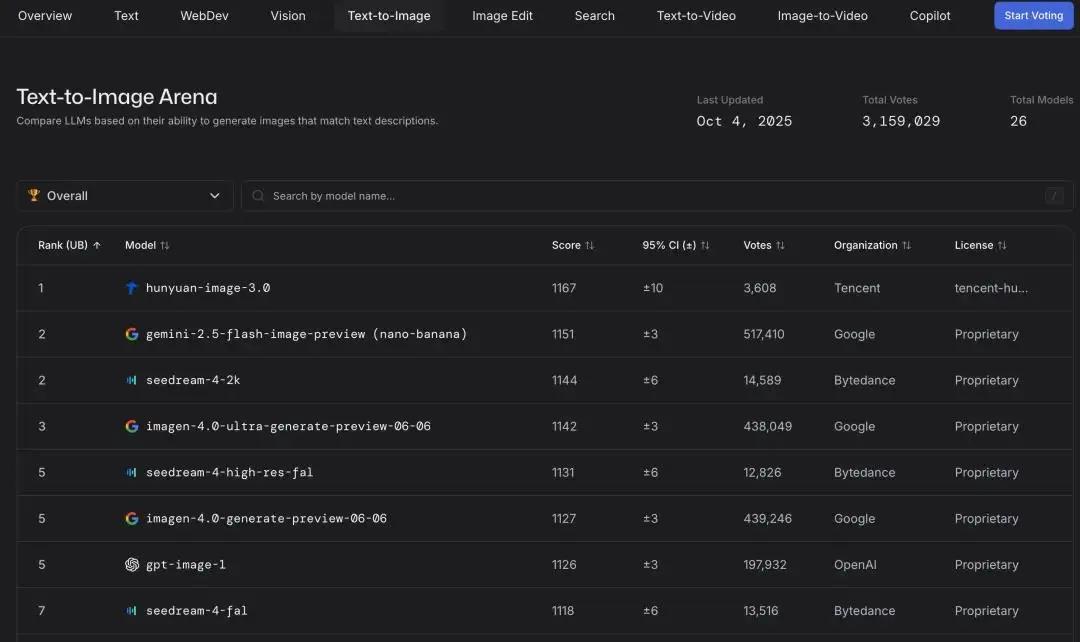
排行榜链接:https://lmarena.ai/leaderboard/text-to-image
这款腾讯模型的参数规模达到80B(推理时每个token激活13B),无疑是迄今为止其推出的最大、最强的开源文生图工具。如今在LMArena的强势表现,证明了当初其声称「生成效果完全可媲美业界顶级闭源旗舰模型」的自信。
自发布以来,混元图像3.0在创作者圈中迅速走红。无论是在画质、细节呈现,还是构图理解和风格的一致性方面,许多用户都表示这款模型的生成效果远超他们的预期。


在 GitHub 平台上,混元图像 3.0 的 star 数量已经超过了 1.7k,显示出它在社区中的高人气,吸引了越来越多的开发者加入。
代码地址为:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
文生图的新标杆,其实际表现是否真如宣传所言?接下来的实测结果将为我们揭晓。
实测体验
排行榜上的佼佼者,未必在日常使用中表现出色。许多模型在评分上获得高分,但实际使用却常常存在不少缺陷。如今,混元图像 3.0 荣登 LMArena 榜单的首位,它到底是实至名归,还是名不副实?请勿急躁,让我们进行深入的实测。
模型体验入口(需通过电脑访问):
https://hunyuan.tencent.com/modelSquare/home/play?from=modelSquare&modelId=289
依托原生多模态架构的优势,混元图像 3.0 继承了 Hunyuan-A13B 的世界知识,并具备了出色的世界知识推理能力。
混元图像3.0:突破传统的创作与推理能力当输入提示“创作一幅九宫格漫画展示曹冲称象,并为每幅画配上简短文字描述”时,混元图像3.0不仅能够轻松识别这是一个历史故事,还能够将其分解为九个连续的场景。更为引人注目的是,它为每一幅画面都附上了简洁而精确的文字说明,形成了完整的叙事链条,而非单纯的画面组合。这一表现表明,它在图像生成方面已经能够有效地融合知识、推理和创造力。

在解答数学题方面,混元图像3.0同样表现出色。它能够迅速识别出代数问题,并提供清晰的推理过程。整个解题步骤逻辑严密,排版整洁,最终的答案也一目了然。
例如,在提示“解方程组x+y=4,2x-y=2,并给出详细求解过程”时,它能够迅速给出合理的解决方案。

当我们进一步输入提示“用循环箭头的形式解释破茧成蝶”时,混元图像3.0又展现了其创意表达的能力:它把自然蜕变的过程拆分为多个阶段。

通过几个案例的测试,我们不难发现,混元图像3.0不仅具备一般常识,还可以在此基础上进行推理与表达。它既能以逻辑严谨的方式解决问题,又能生动直观地展现创意。更为重要的是,这些结果并不是机械式的重复,而是反映了它在理解提示意图后,结合自身知识体系进行再创造的能力。
此外,混元图像3.0还拥有精准的文字生成和长文本渲染能力,显著改善了以往模型中常见的文字乱码或字形扭曲问题。
例如,若提示“设计一张印有‘愿阳光洒进你的心田,带来温柔力量,祝你早日恢复活力,拥抱健康与喜悦~’文字的祝福贺卡”,它能够创造出风格简约而精致的卡片,背景留白,营造宁静的氛围,文字旁边点缀一束由玫瑰、百合和向日葵组成的新鲜花朵,色彩明亮,传递着关怀与希望。
中秋节的祝福与创意海报设计

在复杂的海报设计中,混元图像 3.0 能够自如应对各种文字需求。随着中秋佳节的临近,我们尝试使用该模型生成一幅主题海报。
提示内容为:一幅别致的中秋节画作,夜空中明月高悬,月光洒落在一处古典的中式庭院内。桌上摆满了不同种类的月饼和茶壶。背景则是红色的灯笼和轻轻摇曳的竹林。主标题使用书法毛笔字体“花好月圆”,而副标题为“但愿人长久”。整体画面细节丰富,色调温暖,展现出国风的韵味与气息。

从生成的结果来看,混元图像 3.0 完美捕捉了用户的需求,整体视觉效果不仅具备浓厚的节日气息,同时也体现了商业设计的高水平。
接下来,我们将进行另一组海报的测试。这次的提示为:“柠檬水海报”。

混元图像 3.0 所生成的画面色彩鲜艳,柠檬的切片和透明的玻璃罐呈现得十分逼真。整体构图简洁且干净,充满了商业气息。字体的排版自然融入整体画面,展现出一种清新而富有广告感的效果,仿佛让人嗅到了柠檬的清新香气和冰凉感觉。
混元图像 3.0 还能够处理更为复杂的提示内容:“以白色背景的九宫格插画,展示一只真实写实风格的宠物形象,包含九种不同的表情和动作。画面应当可爱且生动,宠物的神态自然,画风温暖而写实。九宫格的具体内容如下:第一行:① 不高兴的动作,文字“我不想上班”;② 高兴的动作,文字“放假啦”;③ 四仰八叉躺着的姿态,文字“已躺平”。第二行:① 振臂的动作,文字“奋斗吧”;② 大哭的表情,文字“啊啊啊”;③ 竖起大拇指的姿势,文字“你真行”。第三行:① 思考的动作,文字“思考人生”;② 鼓腮生气的样子,文字“不开心”;③ 害羞捂脸的举动,文字“伤心啦”。每张表情图片下方配有黑色萌宠风格字体的文字,整体布局整齐可爱,背景干净简洁,风格协调一致。”

探索混元图像 3.0 的艺术表现力与创意潜能
我们决定继续挑战混元图像 3.0 在传统艺术领域的表现。这次的创作指令为「中国传统剪纸艺术风格,展现细腻精致的民俗非遗纸艺之美。红色剪纸元素镌刻出‘国庆节’字样,构图典雅大方,富有传统韵味。画质高清,突出剪纸细节与层次感,营造节日氛围。」

意想不到的是,混元图像 3.0 对传统元素的掌握同样令人称赞。
在此过程中,混元图像 3.0 展现了极佳的美学表现力。即使面对复杂的指令,它依然能够清晰理解意图,恰当地平衡画面构图,并在细节上呈现出高水平的视觉美感。
接下来,我们使用了英文提示:
「一位年长的日本陶艺家特写肖像,脸上布满了深邃的、阳光烙印般的皱纹,嘴角挂着温暖而富有智慧的微笑。他正在仔细检查一只新上釉的茶碗。背景是他的乡村风格、阳光普照的工作室,柔和的金色时光透过窗户洒入,凸显出泥土的细腻质感。使用85mm人像镜头拍摄,背景呈现柔和的虚化效果(散景)。整体氛围宁静而富有匠心。竖版肖像取向。」

我们可以看到,混元图像 3.0 对英文提示的理解非常到位,生成的人物以及场景都显得极为真实,甚至连手部的细节都毫无瑕疵。
再来一个创作指令:「画面中央是一位金发的小男孩,身穿绿色衣物,围着黄色围巾,坐在一只小船上,怀抱着两朵红玫瑰。小船漂浮在波澜壮阔的蓝色海洋之上,海浪如同绒毛般细腻。背景则是一片璀璨的星空,旋转的星云和明亮的月亮仿佛来自于梵高的《星空》。画面中闪烁的光点为整个场景增添了温暖、浪漫和梦幻的气息。」

此外,混元图像 3.0 在文字渲染上也展现了卓越的能力。例如,当我们输入提示:创建一个高分辨率的文字3D渲染图,第一行内容为”HUNYUAN”,第二行为”IMAGE 3.0″,每个字母使用不同的材质进行渲染,材质可以包括麻绳、亚麻、竹编、草棉、牛仔布、沙子、木材、皮革、粘土、大理石、羊毛、金属、火山熔岩、冰块、火焰、水泥、钻石等。旁边的陶瓷和一只矮小的腾讯企鹅似乎正扶着这些文字,仿佛它们都是由企鹅拼凑而成。将其放置在简洁明亮的浅灰色背景上。

我们还进行了更多的示例测试。
提示内容为:采用水彩画风格,视角为全景。画面描绘了石桥、河流、人物、树木以及天空,主要色调为秋季的金黄与温暖的橙色,笔触细腻且略显朦胧,展现出一种写意的艺术感。整体氛围宁静而悠然,展现了公园秋日的自然景观与人文活动交织的美感,充满了诗意与生活的气息。

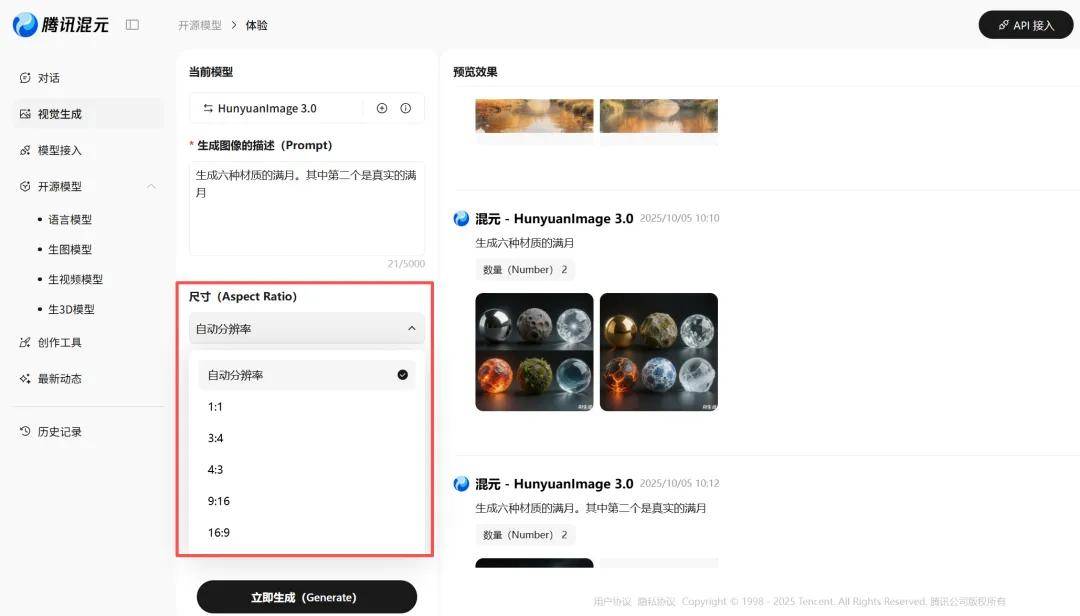
提示内容:生成六种材质的满月,第二个为真实的满月。

最后,再来一款《十二生肖月饼》,祝大家中秋节快乐。此作品围绕中秋主题,融合了传统文化与节日意象,月饼的材质各异,如抹茶、玫瑰,颜色也不尽相同。十二生肖各显风采:鼠小巧玲珑、牛稳健踏实、虎气势汹汹、兔子可爱,龙腾飞、蛇灵动,马奔腾千里,羊温顺,猴子机灵古怪,鸡鸣带来吉祥,狗忠诚伴随情意绵长,猪憨态可掬庆团圆。

通过以上一系列的测试结果来看,混元图像3.0的表现相当全面且稳定。它在创意表达上展现出极强的理解能力和想象力,同时在逻辑推理、文本生成及美学构图等方面也取得了显著的进展。
混元图像3.0是如何诞生的?
这份榜单的成绩以及实测结果都极具分量,混元图像3.0在技术层面必然蕴藏着一些独特之处。
混元图像3.0:突破性技术与全新设计的多模态智能系统混元图像3.0是基于「Hunyuan-A13B」模型构建的,该模型属于MoE大语言模型。为了赋予其处理视觉信息及进行图像理解和生成的能力,腾讯混元团队为其配置了预训练的视觉编码器和变分自编码器(VAE)。此外,团队还引入了思维链(CoT)机制,以提升模型在图像理解和生成任务中的表现。经过针对图像生成任务的微调和后期训练,混元图像3.0的「图像生成模块」最终完成了构建。
在技术路径方面,混元图像3.0不仅关注生成质量的提升,更是逐步朝着「理解—推理—生成一体化」的多模态智能架构发展。
在模型设计上,混元图像3.0采取了一种混合式的离散与连续建模策略。文本词元采用自回归的下一词元预测方式进行建模,而图像词元则基于扩散的预测框架进行处理。这一设计兼顾了语言的逻辑结构与图像的连续特征空间,从而实现了「文字理解与视觉生成」的高效协同。
通过这种方式,整个模型在一个紧密集成的框架内融合了语言建模、图像理解和生成的三大核心功能,达成了统一的多模态建模效果。

从上图可以看出,混元图像3.0的整体架构由以下几个关键组件组成:
- 主干网络(Backbone):其构建基于Hunyuan-A13B,拥有800亿的总参数,包含64个专家,每个token激活8个专家并共享多层感知机(MLP),使得激活的参数量大约为130亿。
- 文本分词器(Text Tokenizer):使用混元分词器(Hunyuan Tokenizer),在其词汇表中特别增加了一组为图像生成与理解任务设计的特殊tokens,从而提升多模态处理能力。
- 图像编码器(Image Encoder):在图像生成过程中,采用内部VAE,将像素映射至32维潜在空间,下采样因子为16。相比需要额外块化层的8倍下采样方案,该设计更为简洁高效,生成质量也更佳。对于条件图像输入,团队使用双编码器,将VAE与视觉编码器的潜层特征拼接,实现统一的多模态表示,支持图像理解与生成任务。
- 投影器(Projector):采用双投影器将图像特征对齐至Transformer潜在空间,VAE特征经过时间步调制的残差块进行映射,视觉特征则通过两层MLP转换,并融合时间步嵌入以增强扩散条件控制。
在数据构建方面,团队首先对一个超过百亿规模的原始图像库进行了筛选,仅保留了不到45%的初始数据,最终形成了一个由近50亿张图像构成的纯净、高质量且多样化的数据集。
随后进行图像描述生成,主要目的是生成内容丰富、可控且基于事实的图像描述。

这一过程由三大核心组成部分构成:(1)结构化图像描述的层级方案,(2)多样化数据增强的组合策略,以及(3)实现事实性实体注入的专用智能体。
最后,团队还构建了思考生图数据集,为此专门准备了两种特定的训练数据:(1)文本到文本(T2T)推理数据,用于增强模型的逻辑推理能力;(2)文本到文本到图像(T2TI)推理数据,明确建模从抽象概念到视觉呈现的全过程。
在训练策略方面,整个过程分为预训练和后训练。
具体来说,预训练分为四个逐步推进的阶段。第一阶段是训练Transformer主干网络,同时保持ViT冻结;第二阶段中,Transformer主干网络仍然冻结,使用MMU数据微调ViT及其对齐器模块;第三阶段则是使用更高分辨率(超过512px)的图像进行联合训练,并引入图文交错的数据,以增强多模态建模能力;最后一个阶段,训练图像被限制在高分辨率子集上,确保每张图像的短边至少为1024像素。用于MMU任务的图像同样被限制在高分辨率子集,以提升理解能力。
在整个训练过程中,团队保留了图像的宽高比,使混元图像3.0能够生成多种分辨率的图像。预训练结束后,团队还进行了针对文生图任务的指令微调,以更好地响应用户的指令。
混元图像3.0具备生成多种分辨率图像的能力
在训练结束后,团队首先在人工标注的数据集上进行了监督微调(SFT)。接着,通过直接偏好优化(DPO)技术,解决了图像生成中普遍存在的结构缺陷。随后,使用在线强化学习框架MixGRPO,优化了风格、构图与光照等元素,从而减少了图像失真和伪影的出现。最终,利用SRPO和团队自主提出的奖励分布对齐(ReDA)方法进一步提升了图像的真实感与清晰度。
得益于上述技术的加持,混元图像3.0在文图一致性和视觉质量方面的表现已经超越了Seedream 4.0、Nano Banana、GPT-Image等众多顶尖模型。
基于这一成果,腾讯混元团队希望能够将其回馈给社区,计划开源混元图像3.0的代码和权重,以进一步降低高质量多模态研究的门槛,助力更多的研究者和开发者在这一前沿模型上展开创新实验和应用探讨。
Hugging Face:
https://huggingface.co/tencent/HunyuanImage-3.0
此外,腾讯混元团队透露,目前混元图像3.0仅开放了文生图的功能,图生图、图像编辑以及多轮交互等版本将在后续陆续发布,大家可以耐心等待。
从模型到生态,赢得AIGC的体系战
在过去的一两个月中,AIGC领域迎来了新的爆发期,包括国外谷歌的Nano-Banana,以及国内腾讯的混元图像3.0与字节的Seedream 4.0等,均在全球范围内引起了广泛的关注。
在图像生成领域,这些“爆款模型”的出现频繁刷新了人们对生成式人工智能能力的认知,尤其是在Scaling Laws增益放缓的背景下。从特征上看,这一波模型的更新正朝着多模态融合与智能深化的方向发展,从早期的“能生成”过渡到“能理解、能推理、能控制”;从属性上来看,人工智能也在从传统的创意辅助工具向具备自主理解与表达能力的智能内容创作引擎转变。
同时,在这场演进中,开源已成为核心的推动力量。特别是在国内,越来越多的AI大型企业与初创公司选择开放模型的权重,通过社区的共享与协作实现快速的更新迭代。作为国内大模型领域的领军者之一,腾讯在多模态技术创新与开源生态建设方面不断推进。
一方面,腾讯围绕混元模型家族深入多模态领域,持续取得领先成果,包括此次的混元图像3.0、3D领域的混元3D 3.0、视频领域的HunyuanVideo以及世界模型HunyuanWorld-1.0。通过这些全栈式的AIGC体系,腾讯在多模态智能与内容生成领域的长远布局做好了充分准备。
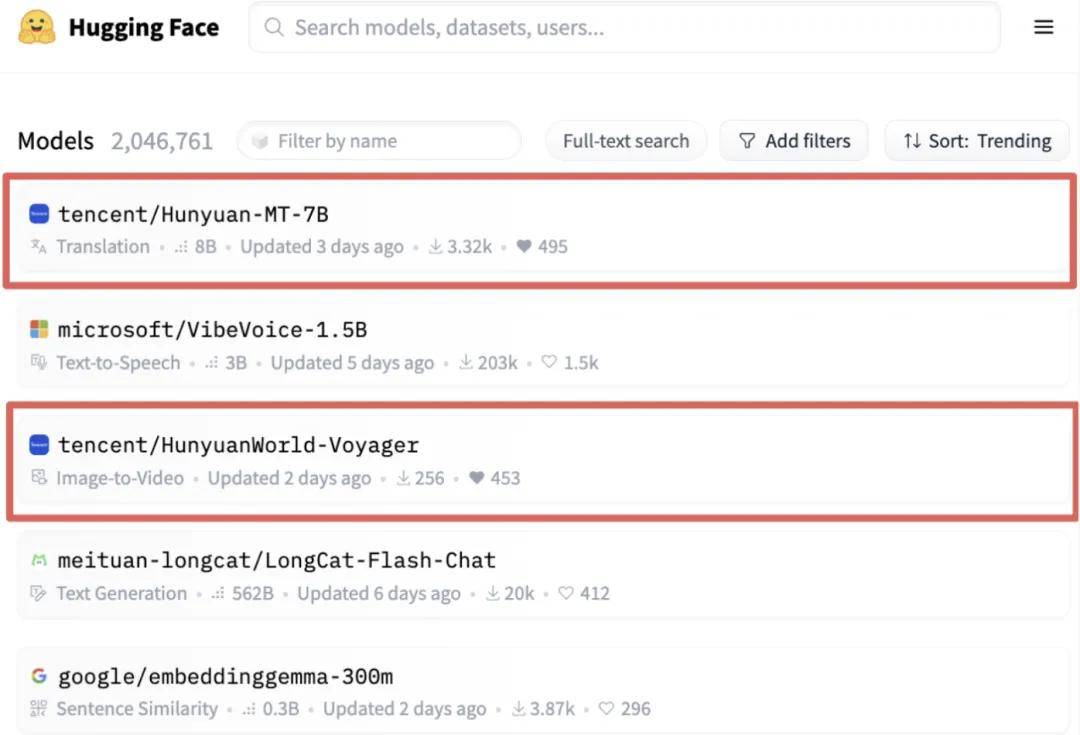
当然,腾讯同样在积极进行开源布局。上月初开源的混元翻译模型Hunyuan-MT-7B以及最新的世界模型HunyuanWorld-Voyager曾在Hugging Face模型趋势榜单中占据了前列。
此外,腾讯广泛的业务矩阵涵盖社交、内容创作、广告推荐与游戏等多个领域,为技术的落地提供了丰富的场景与数据支持。从模型能力到开源生态,再到多场景的应用落地,完整的AIGC“链条”已经形成。