共计 1943 个字符,预计需要花费 5 分钟才能阅读完成。
最近,种种迹象表明OpenAI似乎经历了一些重大变化。
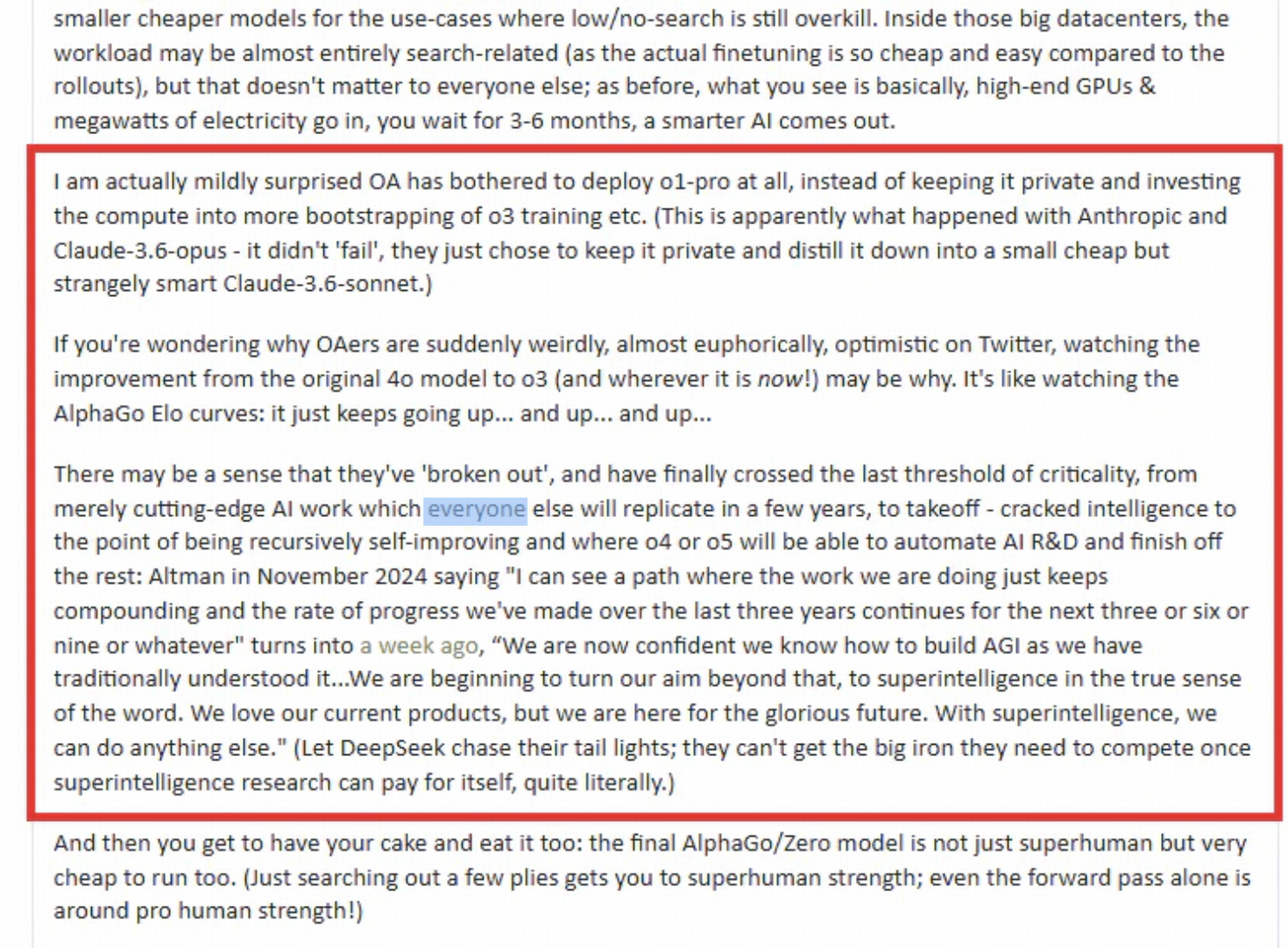
AI领域的研究者Gwern Branwen撰写了一篇关于OpenAI o3、o4、o5的文章。
他指出,OpenAI已经达到了一个关键的转折点,具备了“递归自我改进”的能力——o4或o5能够自动化进行AI研发,并完成后续的工作!
以下是文章的主要观点:
- OpenAI可能会选择对其“o1-pro”模型进行保密,利用自身的计算资源来训练更高级的o3模型,这与Anthropic的策略类似;
- OpenAI或许相信他们在AI技术发展上取得了显著突破,正在朝着ASI的方向前进;
- 开发高效运行的超智能AI是他们的目标,类似于AlphaGo/Zero所追求的成就;
- 初期的推理搜索可能会提升性能,但最终会遇到瓶颈。
甚至还有传言称,OpenAI与Anthropic已经训练出了GPT-5等级的模型,但都选择了“隐匿”之策。
原因在于,尽管模型能力强大,但运营成本过于高昂,因此更倾向于通过GPT-5来蒸馏出更具性价比的GPT-4o、o1、o3类型的模型。
此外,OpenAI的安全研究员Stephen McAleer在最近两周的推文中,似乎像是在编写一部短篇科幻小说:
我怀念过去进行AI研究的日子,那时我们还不知道如何创造超级智能。
在前沿实验室中,许多研究人员对AI的短期影响持非常严肃的态度,而在实验室之外,几乎没有人认真讨论其安全性。
如今,控制超级智能已成为一项紧迫的研究课题。
我们应该如何管理狡猾的超级智能?即便拥有完美的监控手段,它是否会说服我们将其从沙箱中释放?
总之,越来越多的OpenAI员工开始暗示他们已经在内部研发ASI。
这是真的吗?还是说CEO奥特曼的“谜语人”风格被下属们模仿了呢?
许多人认为这只是OpenAI惯常的炒作手法。
然而,让人感到不安的是,几位一两年前离职的人曾表达过类似的担忧。
难道我们真的站在ASI的边缘?
OpenAI被曝训出GPT-5,但雪藏
我相信GPT-5或许已经被训练出来,但我不相信所谓的“因为过于先进所以选择隐匿”的理由。
有就是有,没有就是没有,空谈毫无意义,给我看代码,哦,我忘了,这可是CloseAI,不方便让我看代码。

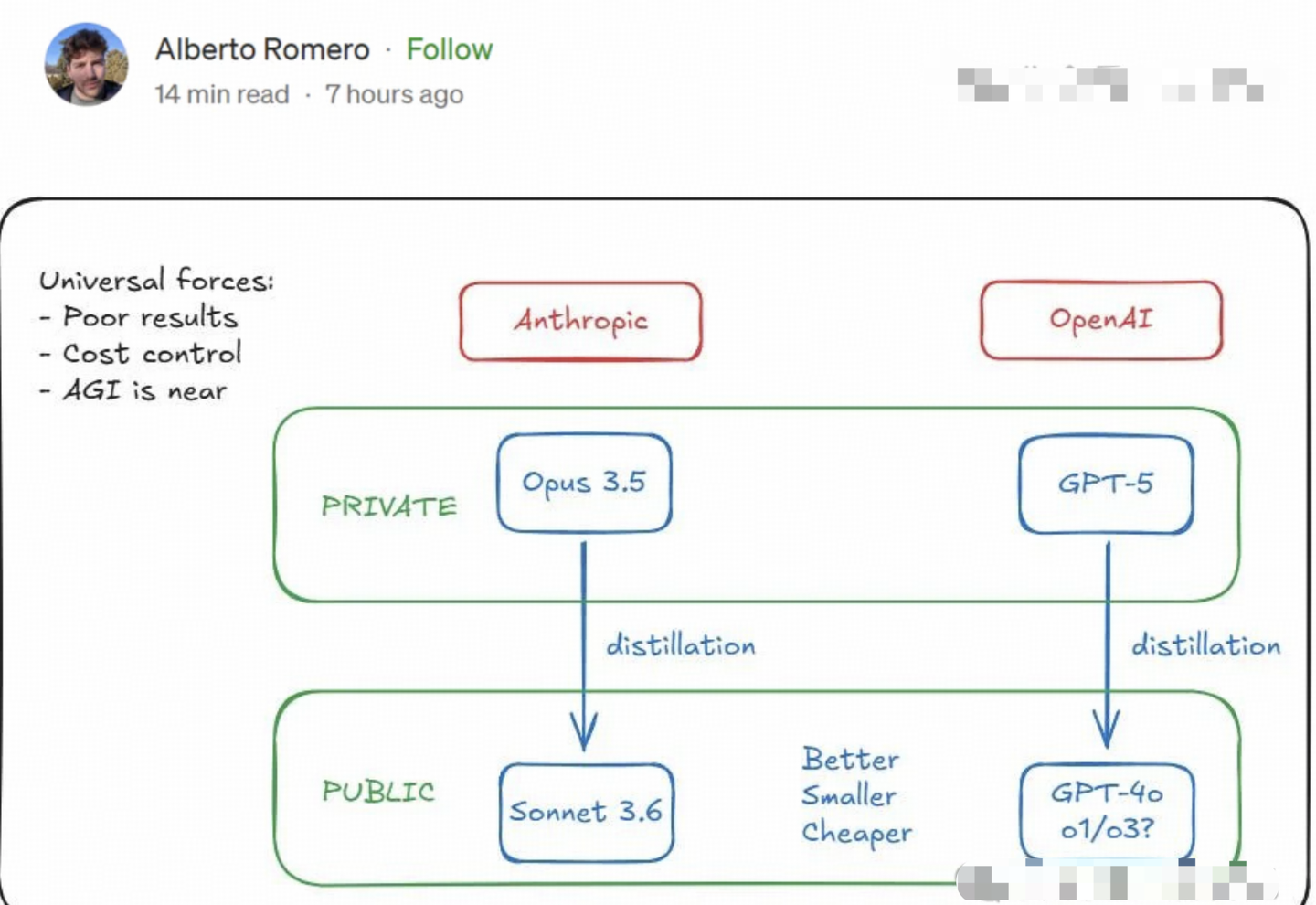
在Alberto Romero的博客中,他贴出了一张“疑似GPT-5生成的图”,并表示关于GPT-5的理论仅仅是他的“假设”,整篇文章充斥着假设,虽然逻辑看似合理,但这事就像狼人杀游戏一样,正着讲也很有逻辑,反着讲同样成立。

之前的官方消息显示,Anthropic在训练Opus 3.5时面临了与OpenAI在开发GPT-5时类似的问题,下一代大型模型无法顺利训练。
根据这一假设,Anthropic和OpenAI实际上都已经突破了这个瓶颈,只是由于运营成本过高,因此选择隐匿,并采用蒸馏的方法来生成更低成本的模型,比如Anthropic可以从中蒸馏出Sonnet 3.6,而OpenAI的o1、o3也可能是从GPT-5蒸馏而来的。
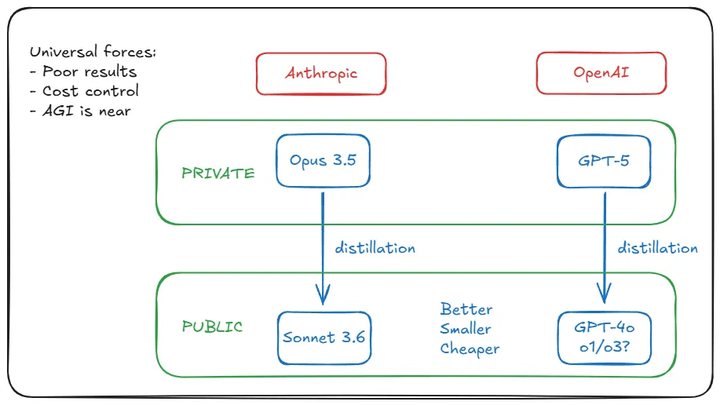
我为什么就是无法相信呢!
首先,我相信OpenAI和Anthropic等其他AI公司之间并不存在显著的技术差距,硅谷的AI圈子其实并不封闭,各公司之间的人员交流相当频繁。如果OpenAI能推出GPT-5,Anthropic距离开发Opus 3.5也绝对不远——肯定不远,否则中国的大模型很快就会模仿出来。
然而,OpenAI和Anthropic之间是竞争关系,竞争对手之间难道不应该争取推出更具影响力的产品吗?
在现实世界中,假如Anthropic真的训练出了Opus 3.5,甚至达到ASI水平,尽管成本很高,他们应该大声宣布这一成就,从而在AI领域取得领先,而不是把这个重要时刻留给竞争对手!
反过来,如果OpenAI确实训练出了GPT-5,甚至达到ASI水平,他们就会非常确信Anthropic会选择隐匿Opus 3.5吗?
商业社会如同黑暗森林,不可能存在这样的默契。
所以,没有就是没有,OpenAI并未训练出GPT-5,Anthropic也没有训练出Opus 3.5。
当然,不论下一代模型的实际性能如何,他们完全可以贴上GPT-5的标签,但是,若搞得神秘兮兮,玩“谜语人”游戏暗示GPT-5已达到ASI水平,那就是在虚张声势。
不如坦诚说“担心中国公司几个月后就模仿出来,所以选择不发布”,这个理由更能让人信服。