共计 1089 个字符,预计需要花费 3 分钟才能阅读完成。
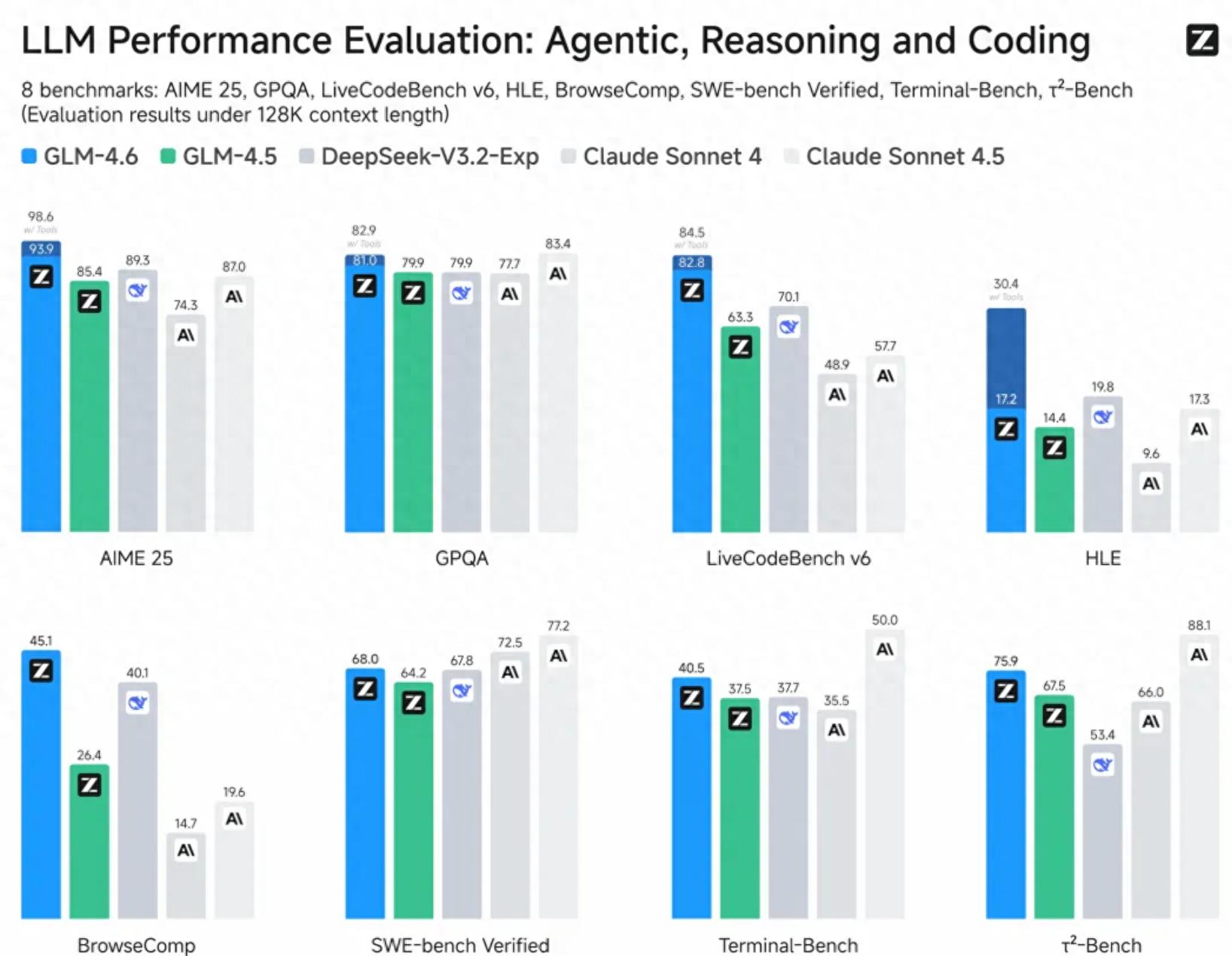
在9月30日,智谱这家国产大模型初创企业正式推出了其最新的GLM-4.6模型。作为GLM系列的最新版本,GLM-4.6在多个重要领域如真实编程、长上下文处理、推理能力、信息搜索、写作能力和智能体应用等方面都有了显著的提升。
根据官方发布的信息,GLM-4.6在公开基准和实际编程任务中展现出与Claude Sonnet 4相当的代码能力;此外,其上下文窗口也从128K扩展至200K,以便处理更复杂的代码和智能体任务。该模型在推理方面的能力得到了增强,且允许在推理时调用工具;在搜索功能上,模型的工具调用和搜索智能体也得到了进一步提升。
值得注意的是,此次模型发布的一个重要亮点是“模芯联动”。GLM-4.6已经在寒武纪的国产芯片上实现了FP8与Int4的混合量化部署,这在行业中是首次将FP8与Int4模型结合在国产芯片上进行生产,提供了一种一体化解决方案,在保证精度的前提下有效降低推理成本,为国产芯片在大模型本地化的应用探索了新的可能性。
FP8代表8位浮点数,具有较大的动态范围和较小的精度损失;而Int4则指4位整数,具有极高的压缩比和最低的内存占用,虽然在适配低算力硬件时精度损失相对明显。此次的“FP8与Int4混合”模式,并非简单的叠加,而是依据大模型的不同模块功能进行针对性量化格式的分配,实现内存的极致压缩和精度的合理控制。
在模型适配的过程中,通过Int4量化,大模型核心参数能够压缩为FP16的四分之一,从而显著减轻了芯片显存的压力;而在推理过程中,积累的临时对话数据也可以通过Int4进行压缩,同时将精度损失控制在“轻微”的范围内。FP8则主要应用于模型中那些对数值敏感、影响推理准确性的模块,以便保留细致的语义信息并降低精度损失。
除了寒武纪,摩尔线程也已基于vLLM推理框架完成了对GLM-4.6的适配,使得新一代GPU能够在原生FP8精度的环境下稳定运行该模型,验证了MUSA架构以及全功能GPU在生态兼容性和快速适配能力上的优势。
寒武纪和摩尔线程此次对GLM-4.6的成功适配,标志着国产GPU已经具备了与前沿大模型协同迭代的实力,加速了自主可控的人工智能技术生态的构建。未来,GLM-4.6与国产芯片的组合将通过智谱MaaS平台优先向企业和公众提供服务。
(本文来自第一财经)