共计 2908 个字符,预计需要花费 8 分钟才能阅读完成。
机器之心发布
机器之心编辑部
自 2023 年推出的 Sora,到如今的可灵、Vidu 和通义万相,AIGC 生成技术如同魔法一般,席卷全球,开启了人工智能应用的广阔前景。
与此同时,AIGC 生成技术在具身智能机器人的表现也令人惊叹不已。
例如,“请给我盛一碗热腾腾的鸡汤”,以前这句话可能让你看到一个感人至深、栩栩如生的视频,而如今,如果身边有一个机器人,竟然能真的为你盛汤!

这一切的技术支持来自清华大学叉院的 ISRLab 及星动纪元——他们的 AIGC 生成式机器人大模型 VPP(视频预测策略)在 ICML Spotlight 中获得了高分!通过预训练的视频生成大模型,AIGC 的神奇从数字空间延伸至具身智能的物理领域,犹如“机器人界的 Sora”!
VPP 通过大量互联网视频数据进行训练,直接模拟人类的动作,这样大大减少了对高质量真实机器人数据的需求,也能在不同的人形机器人之间灵活切换,这无疑将加速人形机器人的商业化进程。

据说,在今年的 ICML2025 会议上,Spotlight 论文的评审难度极高,在超过 12000 篇投稿中,仅有不到 2.6% 的论文获此殊荣,VPP 便是其中之一。
VPP 将视频扩散模型的泛化能力引入通用机器人操作策略中 ,巧妙地解决了扩散推理速度的问题,创新性地使得机器人能够实时进行未来预测和动作执行,这极大提升了机器人的策略泛化能力,同时该项目现已 全部开源!

- 论文标题:视频预测策略:具有预测视觉表示的通用机器人策略,ICML 2025 Spotlight
- 论文地址:https://arxiv.org/pdf/2412.14803
- 项目地址:https://video-prediction-policy.github.io
- 开源代码:https://github.com/roboterax/video-prediction-policy
VPP 被誉为机器人领域的“Sora”
目前,AI 大模型的研究主要有两大主流方向,分别是基于自回归的理解模型与基于扩散的生成模型,代表性的作品包括自回归的 GPT 和生成式的 Sora。
- GPT 进入具身智能领域的思维转变,体现在以 PI(物理智能)为代表的 VLA 技术上,这一技术来源于视觉语言理解模型(VLM)的微调,尤其在抽象推理和语义理解方面表现优异。
- 当生成技术与机器人结合时,便诞生了如 VPP 这样的生成式机器人大模型。
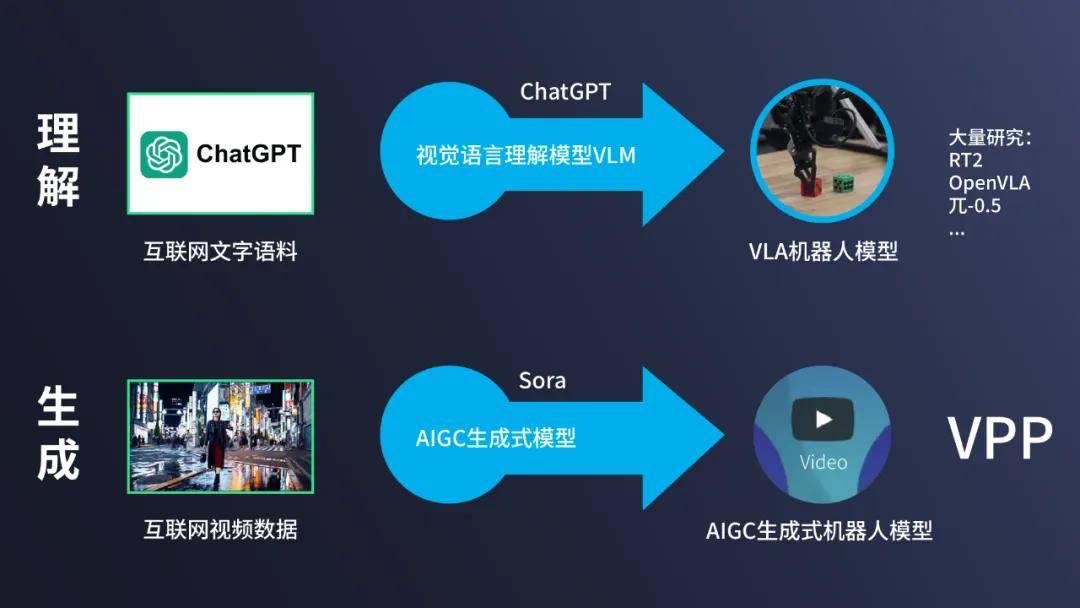
在人工智能的领域中,著名的莫拉维克悖论(Moravec’s paradox)指出:尽管高级推理功能(如围棋、数学)表现容易,但感知和执行的挑战却更为艰巨(例如家务活)。VLM 在高级推理方面表现突出,而 AIGC 生成式模型则在细节处理上更为擅长。VPP 的优势在于其基于 AIGC 视频扩散模型,在底层感知和控制上展现出独特能力。
如图所示,VPP 学习框架分为两个阶段,最终实现基于文本指令生成视频动作。第一阶段利用视频扩散模型进行预测性视觉表征的学习;第二阶段则通过 Video Former 和 DiT 扩散策略进行动作的学习。
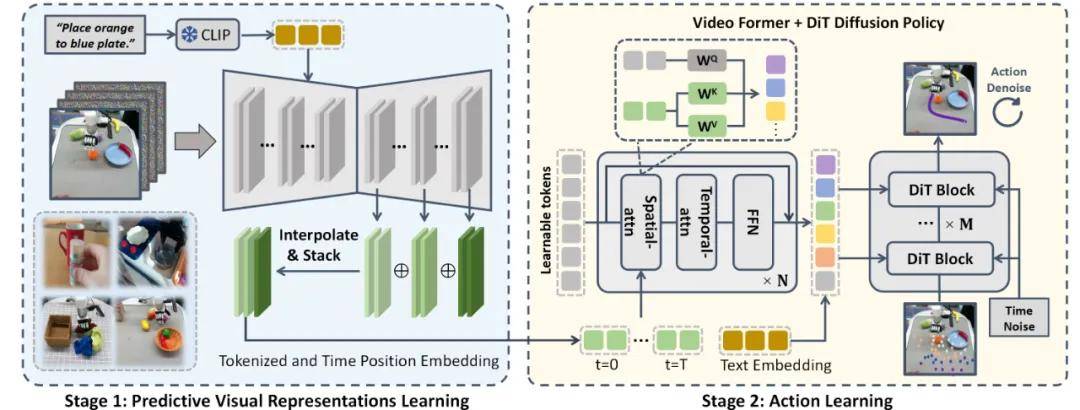
1. 预见未来:使机器人在行动前“心中有数”
过去的机器人策略(例如 VLA 模型)通常只能基于即时观察进行动作学习,机器人在执行前需要理解指令和环境。而 VPP 可提前预测未来场景,使机器人能够“预见答案”进行行动,显著提升了其泛化能力。

VPP 视频的预测结果与机器人实际执行的结果几乎完全一致。被视频生成的内容,机器人都能顺利执行!
2. 高频预测与执行:提升机器人执行速度“更进一步”
尽管 AIGC 视频扩散模型能够生成逼真的视频,但常常需要较长的推理时间。星动纪元研究团队发现,预测未来的每个像素并非必要,通过有效解析视频模型的中间层表征,单步去噪的预测就能够蕴含丰富的未来信息。这使得模型的预测时间缩短至 150 毫秒,预测频率达到 6 -10 赫兹,结合 action chunk size = 10,模型的控制频率可超过 50 赫兹。
如图所示,单步视频扩散模型的预测已包含了大量未来信息,足以支持高频的预测与执行。

3. 跨本体学习:确保机器人先验知识流通“无阻碍”
机器人数据的利用在不同本体之间是一项复杂的挑战。VLA 模型的局限在于只能处理维度低的动作信息,而 VPP 则可以直接学习来自各种形态机器人的视频数据,从而避免了维度不一致的问题。如果我们将人类视为一种机器本体,VPP 还能够直接学习人类的操作数据,这样大幅降低了数据获取的成本。同时,视频数据能够提供比低维动作更为丰富的信息,从而显著提升模型的泛化能力。

VPP 能够从跨本体的丰富视频数据中学习,而 VLA 仅限于处理维度不一致的低维动作信号。
4. 基准测试的领先:让机器人性能独占鳌头
在 Calvin ABC-D 基准测试中,VPP 达到了 4.33 的任务完成平均长度,已接近满分 5.0。相比于之前的技术,VPP 的表现提升了 41.5%。
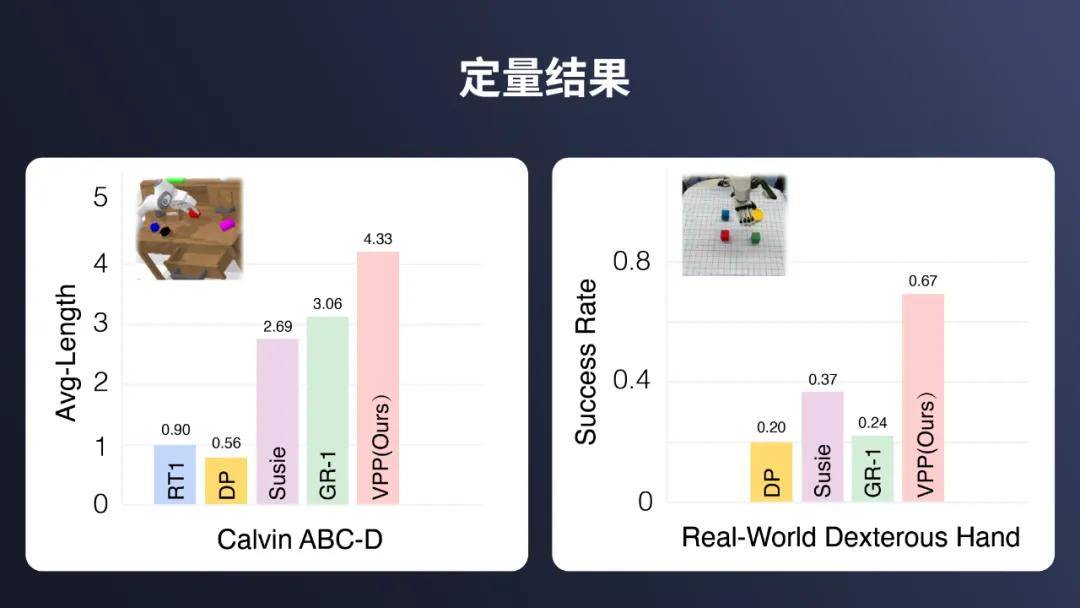
左侧图展示了 Calvin ABC-D 任务的平均长度对比,右侧图则是 Real-World Dexterous Hand 任务的成功率对比。可以明显看出,VPP 在这两项指标上均表现优异,仿真环境中的任务完成平均长度为 4.33,真实设备测试的成功率达到了 67%,远超其他方法。
5. 真实环境中的灵巧操作:让机器人灵活应对各种任务
在真实环境的测试中,VPP 模型展示了卓越的多任务学习和泛化能力。在星动纪元的单臂 + 仿人五指灵巧手 XHAND 平台上,VPP 能够通过一个网络完成超过 100 种复杂的灵巧操作任务,例如抓取、放置、堆叠、倒水以及工具使用等,而在双臂人形机器人平台上,能够完成 50 种以上的复杂灵巧操作任务。

6. 可解释性与优化调试:使机器人操作透明可控
VPP 的预测视觉表示在某种程度上是可理解的,开发者可以通过预测的视频提前识别可能失败的场景和任务,从而进行有针对性的调试和优化,而无需依赖真实世界的测试。
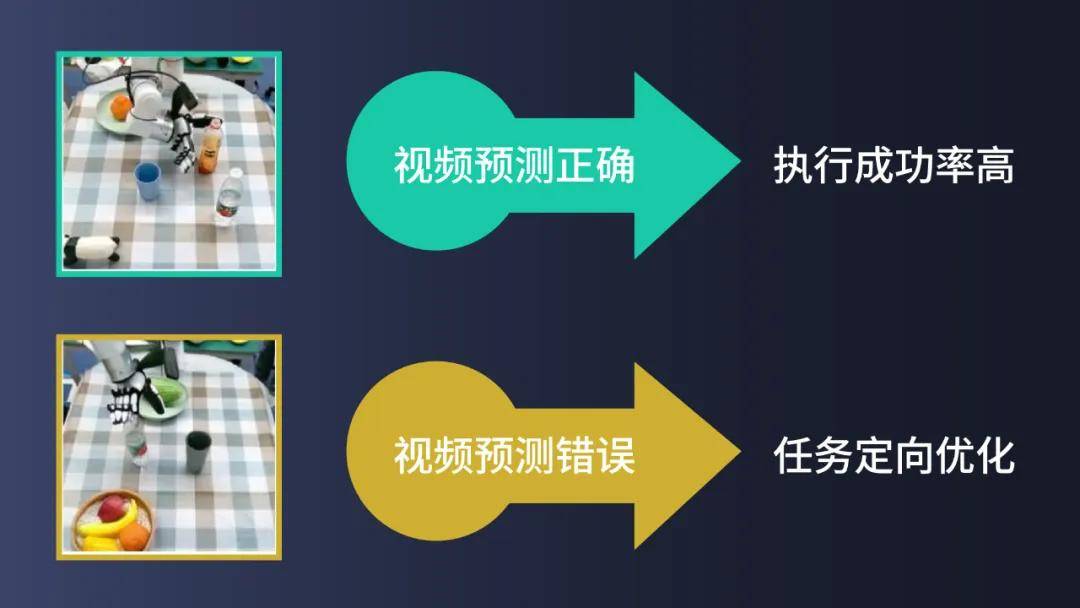
相较于 VLA 模型,后者是一个完全端到端的系统,开发者在调试和优化时需要大量真实世界的测试,才能找到模型中的漏洞,这无疑会耗费大量的时间。
总结
探索 VPP 项目的潜力与开发者指南
与此同时,正如在大型模型领域中,LLM 与生成模型的共存与相互融合,作为首个 AIGC 生成式机器人大模型的 VPP 也将与 PI 等 VLA 大模型彼此促进和借鉴。
在行业持续推动开源优质模型和技术的背景下,我们有理由相信,机器人技术将迎来崭新的发展阶段,而具身 AGI 也会在这条创新路径上不断前行,逐渐拉近与我们的距离,未来的智能世界正向我们走来,蕴含着无限的可能性。
以下是 VPP 项目开源部署的实用提示,供开发者们参考:
- 所有实验均在单个节点(8 卡 A800/H100)上完成;
- 详细的操作指南可以在开源的 GitHub 页面上找到;
- 实验仿真平台采用标准的 Calvin abc-d Benchmark;
- 实验的真实平台包括星动纪元的仿人五指灵巧手星动 XHAND1 以及全尺寸的人形机器人星动 STAR1。