共计 1414 个字符,预计需要花费 4 分钟才能阅读完成。
结论先行:
编程能力排名:GPT-5 Codex > Claude Sonnet 4.5 > GPT-5 > Gemini 2.5 Pro
显而易见,这四个模型生成的代码均无任何错误,并且测试的成功率达到了 100%,确实令人赞叹。
如今的 AI 编程技术已经相当成熟,除了仍需人类的协助外,其他方面几乎都能独立完成。
程序员的角色似乎简化为利用 AI 进行编程辅助,以及适度的休息放松。
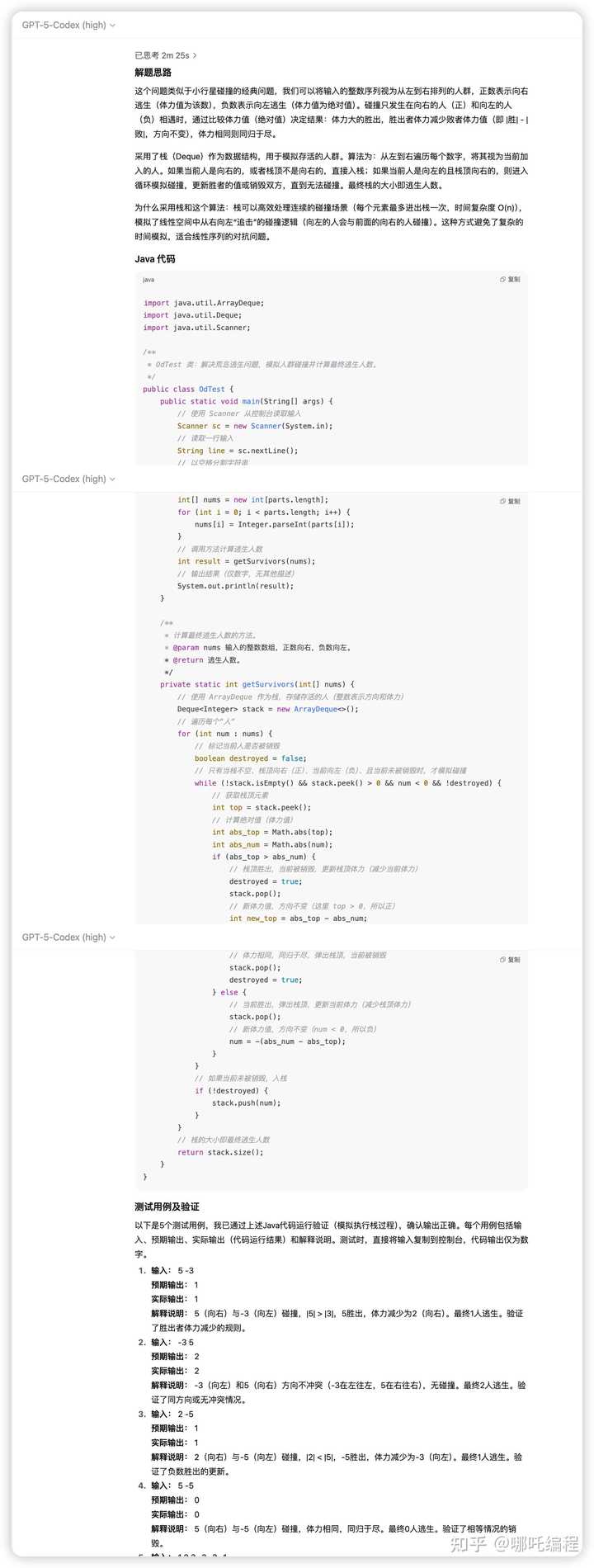
GPT-5 Codex 不仅提供了解决问题的思路和算法分析(包括问题的核心、所用的数据结构和算法),还生成了详尽的 Java 代码、全面的代码注释、对 Java 代码的自我测试、以及包含边界情况的测试用例与说明。
分析原因:
1、GPT-5 Codex 是唯一一个进行 Java 代码自我测试并给出边界测试用例的模型,因此在这方面略胜一筹。
2、作为 Anthropic 最新的旗舰模型,Claude Sonnet 4.5 展现了出色的性能,但未能提供边界测试用例,排在第二位。
3、GPT- 5 的答案并非一次性给出,而是通过多次提问才最终得到,虽然不够理想,但由于其上下文较长,得分上有所加分。
4、Gemini 2.5 Pro 并未明确表示对所提供的代码进行了自我测试,同时也缺少边界测试用例。
国内如何直接使用 GPT-5 Codex
访问网址:www.nezhasoft.cloud
请私信哪吒,备注体验 AI,以领取体验码。
该平台包括 GPT-5、GPT-5 Thinking、GPT‑5 Codex、Sora2、Claude Sonnet 4.5、Gemini 2.5 Pro、Grok4、DeepSeek R1 0528 等多种模型。
关于 GPT-5 Codex
准确性:通过本地 IDEA 进行自我测试,成功率达到 100%
GPT-5 Codex 提供了解决问题的思路、算法分析(包括问题的核心、所用的数据结构和算法)、详尽的 Java 代码、详细的代码注释、对 Java 代码的测试、以及包含边界用例的测试用例与说明。
关于 Claude Sonnet 4.5
准确性:通过本地 IDEA 进行自我测试,成功率同样是 100%
Claude Sonnet 4.5 提供了解决问题的思路和算法分析(包括问题的核心、所用的数据结构和算法)、详细的 Java 代码、详细的代码注释、以及测试用例与说明(但缺乏边界用例)。


关于 GPT-5
准确性:通过本地 IDEA 自测,成功率为 100%
GPT- 5 展示了解决问题的思路、算法步骤、详细的 Java 代码、详尽的代码注释、自我测试的 Java 代码、以及测试用例与说明(但没有提供边界用例)。
此外,回答中并未明确表明是否进行了 Java 代码测试用例的自测。

关于 Gemini 2.5 Pro
Gemini 2.5 Pro 提供了解题思路与算法分析(包括问题的核心、所用的数据结构和算法)、详细的 Java 代码、详细的代码注释、以及包含测试用例与说明(但缺乏边界用例)。


精彩回顾:
如何高效利用 Codex?OpenAI 内部最佳实践指南:8 个最佳应用场景
重磅消息!全新 GPT- 5 正式上线,全面提升,实力强劲
谷歌 Gemini 2.5 Pro 正式发布,科技助力编程,超越 Claude Opus 4,国内可直接使用