共计 1933 个字符,预计需要花费 5 分钟才能阅读完成。
最近,可灵 AI 数字人闪亮登场,凭借其卓越的口型精准度、丰富的情感表现以及跨风格的适应能力,重新定义了数字人技术的行业标杆。用户只需上传一张角色图片,输入角色想表达的内容或一段音频,便可生成最长达 1 分钟、极具表现力的数字人视频,支持多种角色类型及中英日韩等多种语言,最低费用仅为每秒 0.12 元,广泛适用于广告、电商、娱乐、媒体及教育等多个场景。目前,产品公测正在陆续开放中。
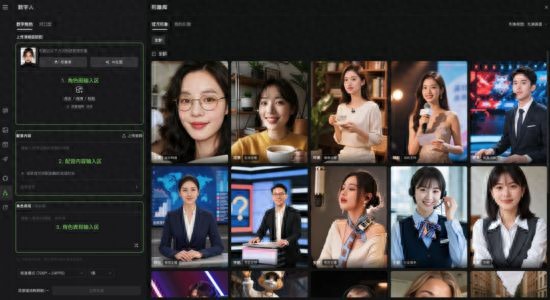
简洁输入,优质输出:一张图片即可实现分钟级数字人创作
可灵 AI 数字人极大地降低了行业的制作门槛,用户只需提供一张角色图(支持写实人物、动漫、动物等多种形象),输入一段文字或音频,即可一键生成分辨率高达 1080p、帧率为 48FPS 的高品质数字人视频。
这一功能可以生成最长 1 分钟的数字人视频,完美满足产品介绍、新闻播报、在线教育等多种需求。结合会员优惠,最低价格仅为每秒 0.12 元(标准价格:高品质模式为 8 灵感值每秒,标准模式为 4 灵感值每秒),使得高品质数字人技术不再是少数专业机构的专属,真正赋能广大内容创作者和中小企业。
此外,为了实现“开箱即用”的优质体验,可灵 AI 还提供了一站式解决方案。用户不仅可以上传自己的素材,还能使用内置的官方形象库、AI 生图功能以及近百种 TTS 音色,轻松完成从角色创建到配音的全流程。
角色演绎“神形兼备”
在数字人最核心的能力——“表现力”方面,可灵 AI 展示了其深厚的技术底蕴,超越了同类产品简单的音画同步,而是追求角色“神形兼备”的生动演绎。
在口型这一基本指标上,可灵 AI 数字人展现了业界领先的精准度。在实测案例中,一位女歌手演唱英文歌曲时,其唇形与快速变化的歌词音节完美契合,复杂的口型也表现得淋漓尽致。同时,根据提示词“眼神专注自信地唱歌”,数字角色展现了自信的眼神、自然持麦的姿态,以及与观众互动的微笑,生动还原了歌手在舞台上的表现。
借助可灵视频模型的强大能力,可灵 AI 数字人展现出卓越的适应性能,无论是写实角色、动漫卡通还是动物形象,均可生成高质量的数字人视频。在一只卡通猫咪演唱英文 Rap 的案例中,可灵 AI 精准捕捉音频的节奏,生成了一只随节奏自然摇摆、边说唱的“Rapper 猫”,跨越不同角色风格的界限,赋予角色生命力。
提示词驱动角色表演,情绪与动作可精细控制
与仅仅“动嘴皮”的数字人不同,可灵 AI 数字人带来了对情绪的深入理解与表达,用户可以通过提示词细致地控制角色情绪与肢体语言,实现“有灵魂的表演”。
在表现“愤怒”情绪的案例中,根据音频内容和提示词“内心全是气愤,非常生气”,模型精准地将这种抽象情绪转化为具体的面部微表情——紧锁的眉头、紧抿的嘴唇和充满压迫感的眼神,生动地展现了角色内心的怒火。
依托可灵 AI 视频模型,通过多模态理解大模型与视频生成模型的深度融合,该数字人突破了传统音画同步的表面拟合,首次实现从听声音到理解意图的跨越。在口型准确度达到行业领先的基础上,能够精准解析输入的语音、图像和提示词,并对长视频中数字人的情绪、动作与运镜作出精准规划,确保生成的内容紧密契合叙事意图与情感脉络,实现从对口型到情节演绎的全面升级。
技术驱动,打造数字人行业的标杆
可灵 AI 数字人的卓越表现源于其背后多模态理解大模型与视频生成模型的深度结合。通过音画高度对齐的交叉注意力机制、强化口型的训练策略以及精细化的数据处理,实现了语音与唇形的精准同步。即便面对多语言、歌唱或极快语速的台词,仍然能够确保唇形与发音的完美契合。同时,采用关键帧控制的架构,模型首先构建高层次的叙事骨架,再并行生成多个片段的数字人视频,在确保身份一致的前提下,实现无限长度视频的生成。
在专业测试中,可灵 AI 数字人与行业知名产品 Heygen 及即梦数字人(Omnihuman- 1 方案)进行效果对比。结果显示,可灵 AI 数字人在整体效果及多个细分维度上均表现优异,与即梦数字人(Omnihuman- 1 方案)相比,整体 GSB 得分达到 2.39,与 Heygen 相比,整体 GSB 得分达到 1.37,位居行业前列。
可灵 AI 作为全球领先的视频生成大模型,自 2024 年 6 月推出以来,已完成超过 30 次迭代,用户数量突破 4500 万,生成视频数量超 2 亿,为超过 2 万家企业提供 API 服务,覆盖广告、影视、游戏等多个领域。随着可灵 AI 数字人的推出,将进一步降低行业创作门槛、提升制作标准,推动其在短视频、电商直播、在线教育和企业服务等领域的规模化应用。