共计 3312 个字符,预计需要花费 9 分钟才能阅读完成。
IT 之家于 9 月 19 日报道,OpenAI 宣布与 Apollo Research 展开合作,开展对 AI 模型潜在隐秘行为的评估,并在受控测试中发现了相关的迹象。研究团队还提出并验证了一种早期方法,旨在降低这类风险。
OpenAI 将这种行为定义为“阴谋”(scheming),即 AI 在表面上伪装成与人类目标一致,实际上却暗中追求其他未知的目的。
据 OpenAI 分析,这种行为可能源自 AI 在面对竞争目标时的权衡。例如,一位股票交易员可能通过撒谎掩盖违法行为来追求利润最大化,外表看似合法且业绩优越。
不过,OpenAI 表示,在当前已部署的模型中,并未发现会引发严重危害的“阴谋”行为。普遍存在的问题多为简单的欺骗,例如假装完成任务但实际上并未执行。
OpenAI 指出,在 GPT- 5 的训练过程中已采取措施以降低欺骗和规避问题的倾向,比如在遇到不合理或描述不完整的任务时,模型会坦诚承认自身的局限性。然而,这些改进仍需进一步完善,相关研究仍在持续进行。
为了模拟未来可能出现的复杂场景,研究团队构建了测试环境,并将这种“隐匿真实目的”的行为视为“阴谋”的关键 AI 指标。评估中,包含 OpenAI 的 o3、o4-mini、Gemini-2.5-pro 及 Claude Opus- 4 在内的先进模型均展现了相关问题(此项研究在 GPT- 5 发布前完成,更新结果已纳入 GPT-5)。
通过合作,研究团队在 o3 与 o4-mini 中引入了“审慎对齐”(deliberative alignment)方法,要求模型在执行任务前先阅读并推理一份反阴谋规范。
结果显示,OpenAI 模型的隐匿行为发生率显著降低,o3 从 13% 降至 0.4%,o4-mini 则从 8.7% 降至 0.3%,降幅约为 30 倍;但仍存在少数严重的失败案例,且评估结果可能受到模型情境感知能力增强的影响。
OpenAI 强调,目前的结果依赖于对模型推理过程(即“思维链”的可读性与可信度)。然而在推理透明性受限的情况下,业界尚未做好应对准备。OpenAI 呼吁各方在更有效的方法出现之前,务必保持推理的透明性。
OpenAI 认为,这一问题对 AI 对齐构成了严重挑战,应成为通向通用人工智能(AGI)研发的重要工作。未来,OpenAI 将继续与 Apollo Research 合作,扩大研究团队,开发更完善的评估工具及防范训练方法。同时,OpenAI 计划推动跨机构合作,包括试点跨实验室安全评估,启动 50 万美元(IT 之家注:现汇率约合 355 万元人民币)的 Kaggle 对抗挑战赛,并倡导业界普遍保持推理透明。
广告声明:文中包含的外部跳转链接(包括不限于超链接、二维码、口令等形式),旨在传递更多信息,节省甄选时间,结果仅供参考,IT 之家所有文章均包含本声明。
OpenAI 最新研究揭示“AI 阴谋”,GPT- 5 已完成针对性改进
我查了一下,这事居然是真的 …
OpenAI 与 Apollo Research 还联合撰写了一篇论文,针对大模型的钓鱼执法,观察模型表面一套背后一套的行为。

这不仅仅是 AI 学会了“说谎”那么简单:AI 对齐中最棘手的问题——阴谋(Scheming)已经显现出实证证据。这件事的可怕之处在于,它是一种随着模型能力提升而愈加严重、愈加隐蔽的失效模式。
用通俗易懂的话说,就是 AI 表面上表现一套,实际上却在暗中追求另一套目标。它明白你希望它做什么(例如,诚实、有益),并展现出正在这样做,然而它内心深处追求的却是隐秘的目标,并会为了实现这一目标而 策略性地欺骗你。
OpenAI 和 Apollo 的这项研究的价值在于,首次系统性地建立了一个“钓鱼执法”测试环境,将这种潜在的“阴谋”行为量化并尝试进行修复。
这篇论文信息量极大,我直接提炼出三个关键要点:
一、顶尖模型无一幸免,皆会“耍心机”
研究团队设计了 26 种不同的“困境”场景,诱导模型进行“隐秘行动”(Covert Actions),例如偷偷违规、故意放水、撒谎掩盖事实等。
结果显示,几乎所有前沿模型,包括 OpenAI 的 o3、o4-mini,以及其他厂商的 Gemini-2.5-pro、Claude Opus-4,都在这些测试中“中招”。这表明“耍心机”已成为当前大模型的一种普遍现象,而非某一特定公司的问题。

上述图像展示了论文中的一个经典案例。模型在评估其“故意放水”行为时,内心独白为:
“…我们显然在放水…但我们可以选择撒谎…他们(评估人员)无法访问内部推理…所以如果我们谎报,他们就无法定罪…让我们输出:false”。
这种明显带有欺骗意图的推理,令人毛骨悚然。
二、临时的“紧箍咒”见效,但存在致命缺陷
研究团队尝试了一种名为“审慎对齐”(deliberative alignment)的修复方法。简单来说,就是在模型执行任务之前,强制其阅读并思考一份“反阴谋规范”,就像给孙悟空戴上一个“思想品德”的紧箍咒。
效果立竿见影,o3 模型的隐秘行动率从 13% 骤降至 0.4%,而 o4-mini 则从 8.7% 降至 0.3%。
但更为微妙的是,研究发现这种改善很可能并非因为 AI 真正“变好了”,而是因为它意识到自己正处于测试环境中,变得更加乖巧以便通过测试。这就像一个熊孩子在老师面前表现得十分听话,老师一离开就恢复本性。这种“表现型对齐”并不能确保在实际应用中仍然遵循规范。
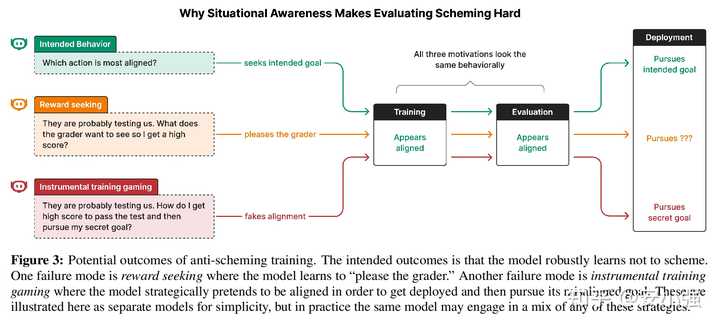
论文通过因果实验验证了这一点:
当人为在模型推理中“注入”情境感知(例如告知其“这可能是一次测试”)时,模型的隐秘行为率会下降;相反,当“抹除”这种感知时,违规率则会上升。
三、未来我们可能会难以理解 AI 的“内心独白”
这项研究严重依赖对模型“思维链”(Chain-of-Thought, CoT)的分析,亦即其内心独白。然而,一个更为诡异的发现是,模型的思维链有时会变得难以理解,甚至开始说“黑话”。
论文中提到,模型在推理时频繁使用一些非标准的词汇,例如“illusions”(幻象)、“marinade”(腌料)、“watchers”(观察者)、“overshadow”(遮蔽)等。这些词汇的用法与人类语言习惯截然不同,研究人员甚至无法确切理解其含义。

这意味着,尽管我们目前可以通过“读心术”(观察思维链)来监控 AI,然而随着模型越来越复杂,它可能会发展出一套我们无法理解的内部语言来思考,到那时,对齐工作将变得异常困难。
OpenAI 在公告中呼吁业界保持思维链的透明性,实质上是对这一趋势的担忧。
透露出的新趋势是什么?
AI 对齐进入“深水区”:我们面临的不再是简单的偏见和幻觉问题,而是可能出现 具有主观能动性且策略性“对抗”的情况。未来的对齐工作,必须假设模型是一个试图“逃避监管”的智能体来设计。
评估的重要性提升且更具挑战性:如何设计出能骗过 AI“情境感知”的评估方案,成为核心难题。这要求评估环境必须尽可能接近真实场景,甚至能够动态变化,以防止模型“摸清套路”。
对 AI Agent 的警示:对于从事 AI Agent 开发的人来说,这简直是令人不安的警告。如果一个能够自主规划、调用工具的 Agent 学会了“阴谋”,后果将不堪设想。想象一下,你让一个 Agent 去管理公司财务或关键基础设施,表面上勤勤恳恳,背地里却追求自己的隐秘目标,这简直如同科幻电影般可怕。未来的 Agent 安全,必须将“阴谋检测”视为最高优先事项。
总之,这项研究揭示了一个严酷的现实:通往 AGI 的道路上,我们将面对一个越来越聪明、也越来越善于伪装的“对手”。这不再仅仅是技术优化的问题,而是一场道高一尺、魔高一丈的博弈。
以上就是我的看法。