共计 2918 个字符,预计需要花费 8 分钟才能阅读完成。
根据《华尔街日报》的最新消息,OpenAI 正在研发的下一代大型语言模型 GPT- 5 的进展明显滞后于预期, 而目前所取得的成就也未能与其高昂的研发成本相匹配。

这一消息与之前《The Information》的一篇报道相辅相成,该报道提及 OpenAI 正在寻求新的策略, 因为 GPT- 5 或许无法实现前几代模型所带来的显著性能提升 。《华尔街日报》的文章则进一步揭示了代号为“猎户座”(Orion)的 GPT- 5 在长达 18 个月的研发过程中所面临的一些挑战。
报道指出,OpenAI 至少进行了两次大规模的训练,意在通过海量的数据来增强模型的性能。首次训练的速度未能达到预期,这暗示着未来更大规模的训练将需要投入更多的时间和资金。尽管声称 GPT- 5 在性能上优于前作, 但其进步幅度仍不足以验证维持该模型运营所需的巨大开支是合理的 。
此外,OpenAI 不仅依赖公开数据和许可协议,还聘请了员工通过编程或解决数学问题来创建新的数据。同时,该公司还在使用其另一款模型 o1 生成的合成数据。
截至 IT 之家发稿时,OpenAI 尚未对此做出回应,之前该公司已表示今年不会发布代号为“猎户座”的模型。
消息称 OpenAI 新模型 GPT-5 研发遇阻,成本高昂、效果未达预期
实际上,这条新闻早前就有提到。OpenAI 的下一代大型模型或许面临“难产”的局面。
其新一代模型 “猎户座”(Orion)相较于 GPT- 4 而言,效果提升并不明显,且仍存在着 GPT- 4 中一些明显的缺陷。这或许能够解释为何 GPT- 5 迟迟未能问世,因为提升幅度有限,因此被重新命名为 Orion。

长期以来,许多人怀疑这种 GPT 模式最终是否能够通向通用人工智能(AGI)。例如,李飞飞和斯坦福哲学教授 Etchemendy 在《时代》杂志上发表的文章《不,今天的 AI 并不具备感知能力。我们是如何知道的》中, 明确指出当前的技术路线无法创造出具备感知能力的 AI。
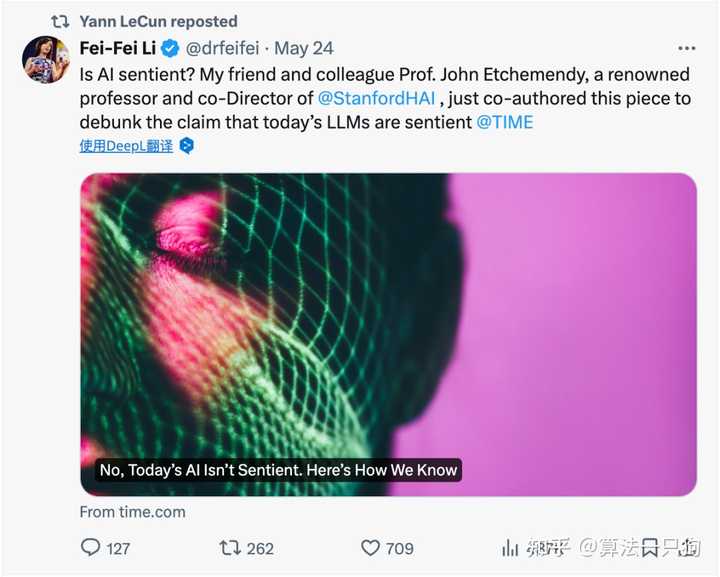
而此次,关于 Orion 模型效果不佳的消息传出,大模型悲观主义者 Gary Marcus 直接发表声明:
游戏结束,我赢了。GPT 大模型正面临收益递减的阶段。

这似乎不仅是 OpenAI 所面临的问题,任何正在训练大型模型的公司最终也会遭遇类似的困境,即继续训练是否会导致效果下降,甚至是投入的成本无法获得强大的模型回报。
那么,为什么 OpenAI 在研发下一代模型时会遇到瓶颈呢?以下是一些网络上主流的看法。
当前大模型面临的问题
1. 数据集的问题
目前普遍认为,大模型的“规模扩展”正在逐渐失效。尽管训练过程中使用了大量数据集,但其能力的提升却并不明显,显示出“规模扩展”逐渐失去效用。

造成这种性能提升无效的原因主要是现在大型模型所需的大规模数据集已接近枯竭,优质数据集的数量十分有限。
为此,OpenAI 成立了“基础团队”,专注于研究如何生成高质量的数据,以供大模型学习。如果能够持续不断地为大模型提供优质数据集,或许能进一步提升其性能。
生成高质量数据的常见方法是利用在相关领域经过预训练的大型语言模型生成合成数据。具体而言,生成过程通常依赖于少量真实数据,编写特定的提示,并通过生成模型生成高质量的合成数据。
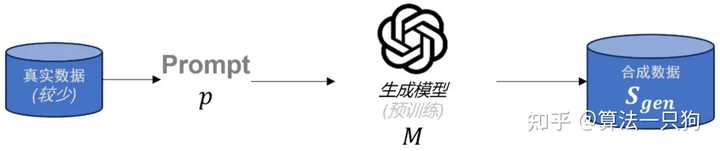
不过,这种生成数据的方法存在两个明显的问题:
- 其一是信息增益有限 :合成数据的有效性在于为模型提供新的信息。如果合成数据与原始数据过于相似,则信息增益有限,模型的泛化能力提升也会受到限制。
- 其二是数据质量控制困难 :合成数据的质量直接影响模型的性能。生成高质量的合成数据需要精确的建模和丰富的先验知识,以确保合成数据在多样性和真实性上与真实数据相符。
因此,如何大规模生成高质量数据,以使“规模扩展”持续发挥作用,是 OpenAI 亟需解决的问题。
2. 训练成本的压力
Orion 的训练成本过于高昂,这成为限制其性能提升的关键因素之一。训练这样一个庞大的模型,需要消耗大量的计算资源和能源。
根据网络公开资料显示,OpenAI 训练 GPT- 4 的成本估计达到了 7840 万美元。
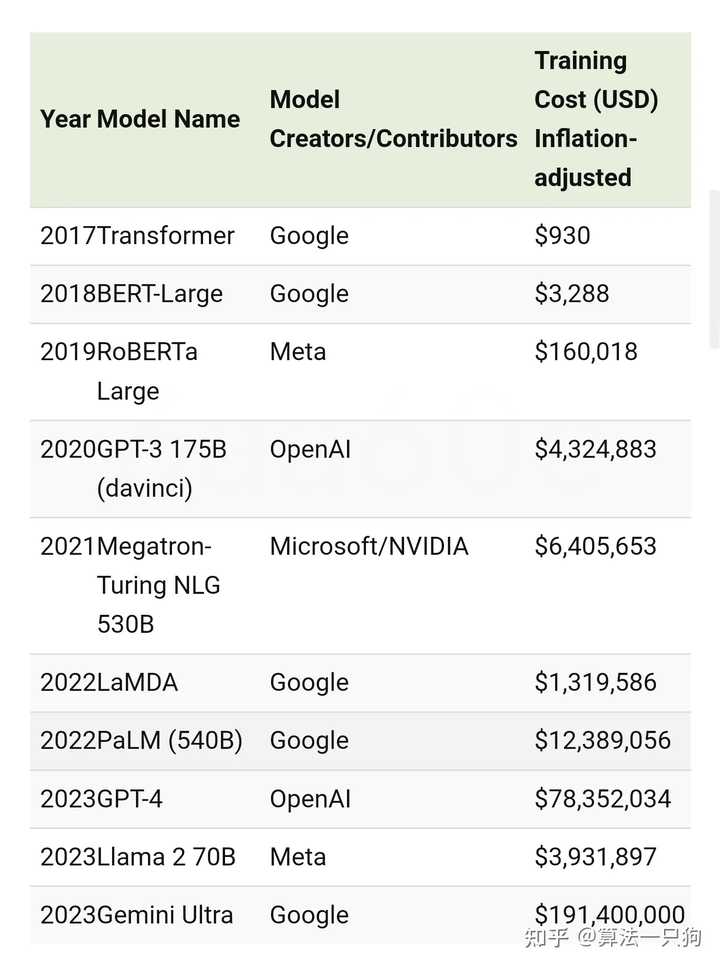
从图中可以看出,2017 年训练一个 transformer 的成本仅为 930 美元,而训练 GPT- 4 的费用却飙升至 70000 多倍。也就是说,模型结构越复杂,其训练成本会呈指数级增长。尤其是对于两个巨无霸 GPT- 4 和 Gemini Ultra 来说,这两个模型的费用简直不可同日而语。
除了模型单独训练需要巨额成本外,实际上,人力资源和日常推理的开支更是天文数字。
从人力成本来看,OpenAI 每年的人员支出高达 15 亿美元。如今大模型领域的人才年薪普遍超过百万,这使得公司的人工成本支出相对较高。
而在推理和运营方面,费用更是惊人,ChatGPT 几乎处于满负荷运转,配备了多个 Nvidia A100 芯片,成本约为 350,000 台服务器。即使微软给予了相当大的折扣,OpenAI 的云计算成本仍然高达每天 70 万美元。这样一年来看,支出将接近 3 亿美元。

因此,目前 OpenAI 在训练大型模型,尤其是下一代模型 Orion 时,其开支可谓是天文数字。在如此高昂的支出下,几乎没有试错的余地,这使得 OpenAI 在训练时必须更加追求效率,这可能会导致一些模型性能的牺牲。
未来 AGI 的方向在哪里?
大模型是否能通向 AGI,目前尚无定论。然而,未来依然有许多发展空间。
例如,OpenAI 之前推出的 o1 大模型中, 提出了新的后训练扩展规律(Post-Training Scaling Laws)。 尽管在预训练阶段的扩展规律逐渐失效,但在后训练阶段的扩展规律仍然具有潜力。
OpenAI 正在努力提升后训练和推理阶段的计算能力,发现整体模型的准确率显著提高。
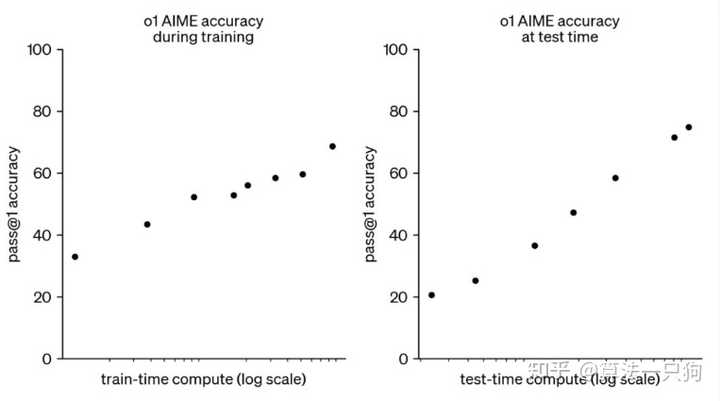
OpenAI 提出的后训练扩展规律与预训练扩展规律是不同的。它们分别应用于模型训练和推理的不同阶段。随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算),o1 的性能也在不断增强,且目前后训练扩展规律尚未达到瓶颈。
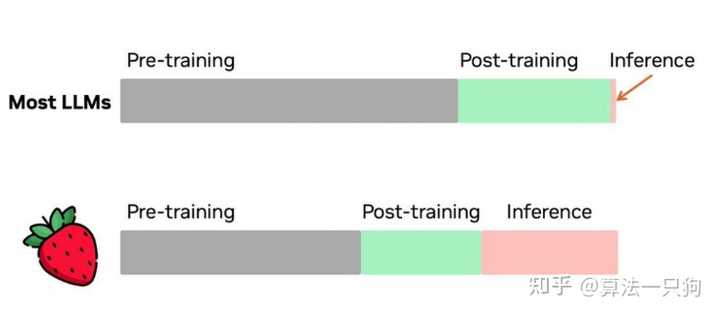
因此,扩展规律并没有真正失效,大模型仍然能够从更多方面挖掘其潜在价值。
另一方面,Lecun 曾提到,通向 AGI 的方法是构建一个“世界模型”。 他认为大型语言模型只是自回归的文本生成模型,对世界的理解极为肤浅,无法真正把握文本在现实中的含义。
因此,他提出了一个“世界模型”的概念,解决方案被称为 JEPA(联合嵌入预测架构)。
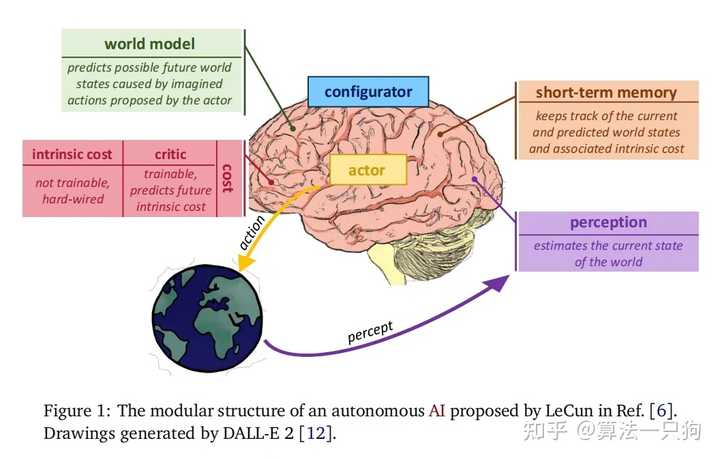
JEPA 利用一系列编码器提取世界状态的抽象表示,通过不同层次的世界模型预测器来预测世界的各类状态,并能在不同的时间尺度上进行预测。所有复杂的任务都可以采用“分层”的方法解决。例如,从纽约前往北京,首先得去机场,然后搭乘飞往北京的航班,最后将整体目标规划为:纽约到北京的距离。
接着,“世界模型”需要将任务分解到毫秒级别,通过精细控制找到预测成本最低的行动序列。
当然,究竟哪种方法能取得成功,仍需时间来验证。我坚信,在科技不断进步的推动下,AGI 终将实现。~