共计 860 个字符,预计需要花费 3 分钟才能阅读完成。
Qwen3 起初采用混合思维,但在 2507 版本中又恢复了传统的独立模型。
Deepseek 则最初由两个独立模型构成,但在 V3.1 的混合思维版本中,V3 和 R1 被合并,并替换了官方网站的 API。
之前的结论表明,混合思维的实现并非易事,那么 Deepseek 为何选择训练这样的 V3.1 版本呢?(从技术角度或是八卦均可)
Qwen 团队与开源社区有着密切的交流,恢复到 2507 版本显然是根据了明确的反馈——在许多单机部署的场景下,让用户自主选择使用哪种模型更为高效。此外,Qwen 自身还拥有闭源的 Plus 和 Max,7 月份最新的快照仍维持混合模式,底层很可能在进行某种路由处理。毕竟大厂的模型种类繁多,开源模式的回归也并不需要太多心理负担。

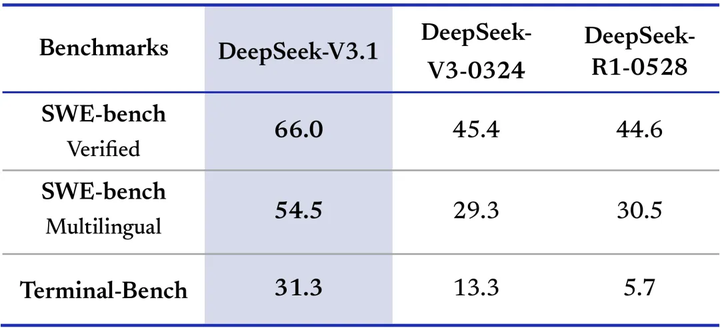
至于 Deepseek 的思路,目前只能进行推测,比较明确的是,Deepseek 已经瞄准了编程模型的市场。本次更新主要是针对该需求的强化,尤其是提升了 Agent 的能力,并在推理方面强调了思维链的简化,某种程度上也是为编程场景进行了优化。
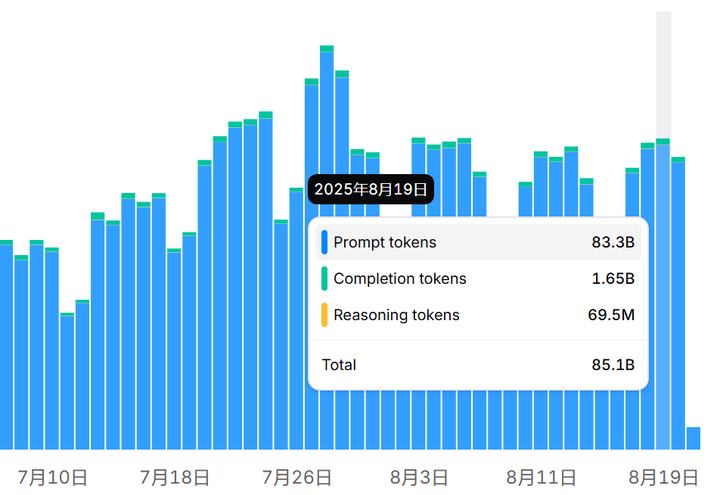
实际上,若我们观察所谓的混合模型 Claude Sonnet 4,会发现 Reasoning tokens 的占比极为有限。
因此,我认为“V3.1 合并了 V3 和 R1”的说法可能并不准确,可以说是以 V3 为基础,初步增强了一些推理能力。例如,连目前常见的推理预算都未能支持,而在推理模式下反而不支持函数调用。
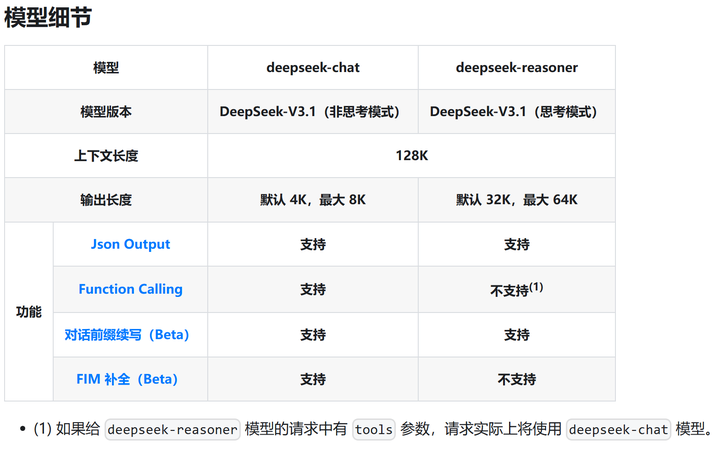
所以现在的最新版本是 V3.1,而非 R1.1。未来 Deepseek 可能会推出一个更为强大的推理模型,但就无需再突出推理能力,而是推出一个参数更多的型号,类似于 Claude Opus 和 Sonnet 之间的关系。