共计 876 个字符,预计需要花费 3 分钟才能阅读完成。
规模庞大且功能强大!

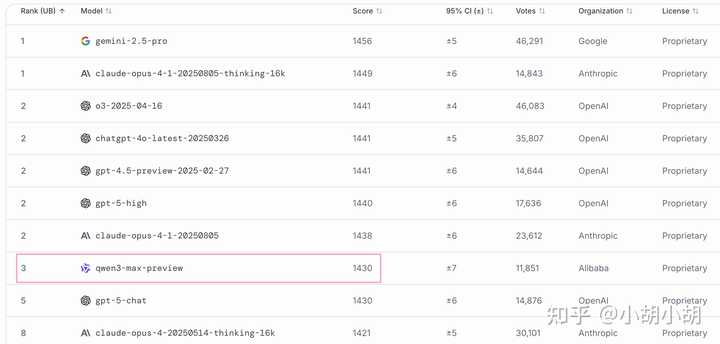
lmarena 排行榜 text 榜(超过 gpt-5-chat)
他们的官方博客标题为: 大即是优
一种让人感觉财力雄厚且技术过硬的印象 …

我将博客中的信息进行了简要总结:
基本信息概述
Qwen3-Max-Instruct
LMArena 排行:预览版全球排名第三,超越 GPT-5-Chat
正式版提升点:代码生成和智能体表现
SWE-Bench 认证(真实编程挑战):69.6 分
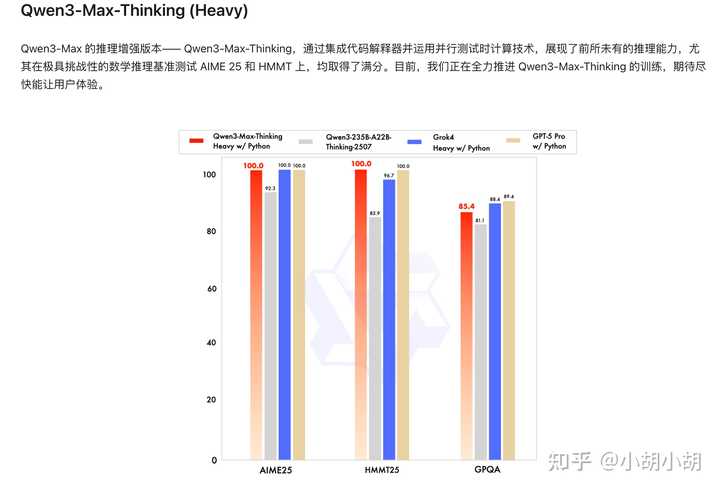
Tau2-Bench(智能体工具调用):74.8 分,超越 Claude Opus 4 和 DeepSeek-V3.1Qwen3-Max-Thinking
集成 代码解释器 + 并行测试计算
数学推理基准:AIME 25、HMMT → 100% 正确率
仍在训练中,暂未开放 技术创新亮点
PAI-FlashMoE:高效 MoE 并行训练技术
ChunkFlow:长序列高吞吐训练方案
SanityCheck / EasyCheckpoint:提升大规模训练的稳定性
调度链路优化:降低集群运行损耗 lmarena 排名(20250924)
此外,他们还推出了一个重型版本,专注于深度思考:
总结一下: 规模庞大且功能强大,直指 OpenAI。
来源:知乎
原文标题: 如何评价 9 月 24 日凌晨发布的 qwen3 max 正式版?有哪些惊喜?– 知乎
声明:
文章来自网络收集后经过 ai 改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!
正文完