
共计 1678 个字符,预计需要花费 5 分钟才能阅读完成。
今天,我们荣耀推出了通义千问系列的新型语音识别模型 Qwen3-ASR-Flash。该模型基于 Qwen3 基础模型,经过海量多模态数据和数百万小时的自动语音识别(ASR)数据的训练而成。
Qwen3-ASR-Flash 展现了卓越的语音识别性能,具备高精度和强鲁棒性,支持 11 种语言和多种方言。特别之处在于,它允许用户以任意格式提供文本上下文,从而获得个性化的 ASR 结果,并且还能够识别歌曲。
体验方式:
ModelScope:
https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo
HuggingFace:
https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
阿里云百炼:
https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model&url=2979031
Qwen3-ASR-Flash 的主要特点:
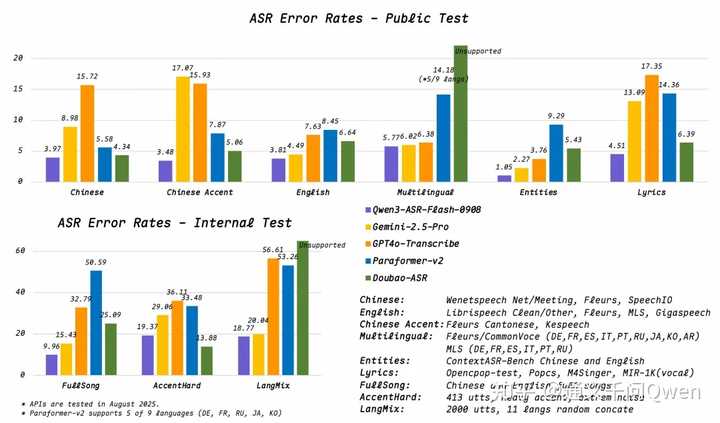
- 卓越的识别准确性: 在多种中英文及多语种基准测试中,Qwen3-ASR-Flash 的表现均处于领先地位。
- 出色的歌曲识别能力: 支持对歌声的识别,包括清唱和配乐歌曲,实测错误率低于 8%。
- 个性化识别: 用户可以提供各类格式的背景文本(如词汇表、段落或完整文档),模型能够智能利用这些上下文内容识别并匹配命名实体和其他重要术语,从而输出个性化的识别结果。
- 语言识别与非人声过滤: 模型能够准确识别语音语言,并自动排除静音和背景噪声等非语音片段。
- 鲁棒性: 在面对复杂的句子、语言切换和重复词语等挑战时,模型仍能保持高准确率,即使在复杂的声学环境下。
语种支持
Qwen3-ASR-Flash 单一模型能够精准转换多种语言、方言和口音:
- 中文: 包括普通话及四川话、闽南语、吴语、粤语等主要方言。
- 英语: 支持英式、美式及其他多种地方口音。
- 其他支持语言: 包括法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语及阿拉伯语。
背景提示
为了获得个性化的 ASR 结果,用户可以提供任意格式的背景文本,Qwen3-ASR-Flash 无需对上下文信息进行格式预处理。
支持的格式包括但不限于:
- 简单的关键词或热词列表。
- 任意长度和来源的完整段落或整篇文档。
- 以任意格式混合的关键词与全文段落。
- 无关甚至无意义的文本(模型对无关上下文的抵抗力极强)。
演示示例
Qwen3-ASR-Flash 单模型在单次推理中,示例 2 以外的情况未配置任何背景信息。
多种噪声环境下的连续识别
 https://www.zhihu.com/video/1948533435233711156
https://www.zhihu.com/video/1948533435233711156
电竞赛事解说
https://www.zhihu.com/video/1948533514745124437

英语说唱
https://www.zhihu.com/video/1948533587394696057

车载噪声环境下的方言识别
 https://www.zhihu.com/video/1948533651013870633
https://www.zhihu.com/video/1948533651013870633

多种语句切换
https://www.zhihu.com/video/1948533695876146294

化学课程讲解
https://www.zhihu.com/video/1948533733197054112

未来展望
Qwen3-ASR-Flash 将持续进行迭代更新,力求不断提升通用识别的准确性,同时我们也将开发更多功能,为用户提供更智能、更便捷的语音转文字服务。









