共计 2731 个字符,预计需要花费 7 分钟才能阅读完成。
Qwen3 推理模型重磅来袭!
全新开源的 Qwen3-235B-A22B-Thinking-2507,在推理能力和通用性能上取得了显著提升,其表现可与 Gemini-2.5 pro、O4-mini 等顶级闭源模型相媲美,并且创下了全球开源模型的最佳性能记录:
- 在编程(LiveCodeBench)、数学(AIME25)等关键领域,Qwen3 推理模型实现了 推理能力 的新突破;
- 在知识(SuperGPQA)、创意写作(WritingBench)、人类偏好对齐(Arena-Hard v2)、多语言处理(MultilF)等方面,Qwen3 推理模型同样展现了显著的进步;
- 新模型支持 256K 的长文本理解,能够轻松处理超长上下文。
期待大家从 推理表现 、 工程集成 、 成本控制 、 上下文管理 等多个角度,分享你在尝试或评估 Qwen3-235B-A22B-Thinking-2507 过程中的 真实体验 与深刻见解!
我时常出入于 Reddit 的一个名为 LocalLLaMA 的论坛,那里聚集了超过 50 万的用户,堪称在 AI 时代异常活跃的社群。
许多人可能对这个名字感到困惑,究竟为何一个 AI 社区会与 LLaMA(羊驼)相关联呢?答案就在于论坛的创建背景,这个群组成立于 Meta 发布 Llama 模型的同时,鉴于 Llama 是开源模型,便有了 Local(本地)与 LLaMA(羊驼)的组合。
然而,时至今日,这个论坛几乎不再讨论 Meta 的相关内容,因为 Llama 系列除了先发优势,其他方面几乎全是劣势。
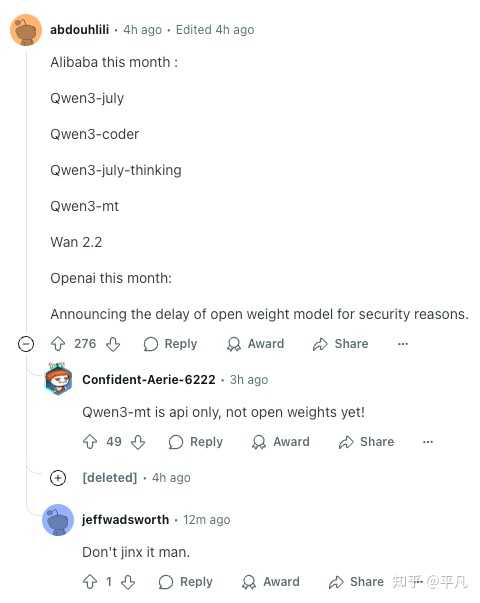
本周,论坛内热议的 AI 模型是阿里巴巴的 Qwen 系列,确切地说是基于 Qwen3 衍生出的三个重磅模型,接连发布了 Qwen3-Coder、Qwen3-235B Non-thinking 与 Qwen3-235B Thinking,甚至被戏称为“阿里开源周”。
有位外国用户在调侃,7 月份阿里巴巴推出了五款 AI 产品,而 OpenAI 则仅发布了推迟开源模型的公告。
最新发布的模型名为Qwen3-235B-A22B-Thinking-2507,正是题目中提到的 Thinking 模型。
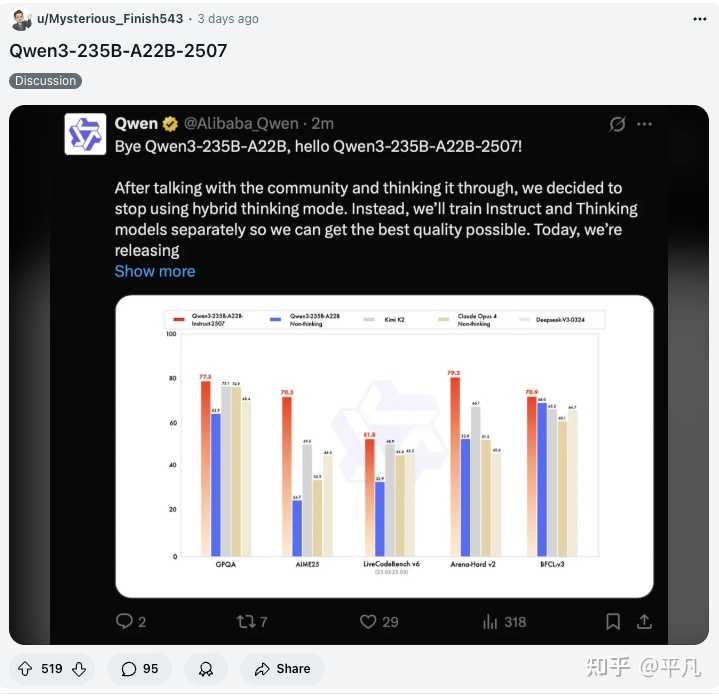
其前一代模型与 Claude 类似,采用可切换的 thinking/non-thinking 模式,而此次更新,Qwen3 模型采用了分别训练的方式,因此一次性推出了两个 AI 大模型,一个是 Non-Thinking 的 Instruct,另一个是 Thinking 推理大模型。
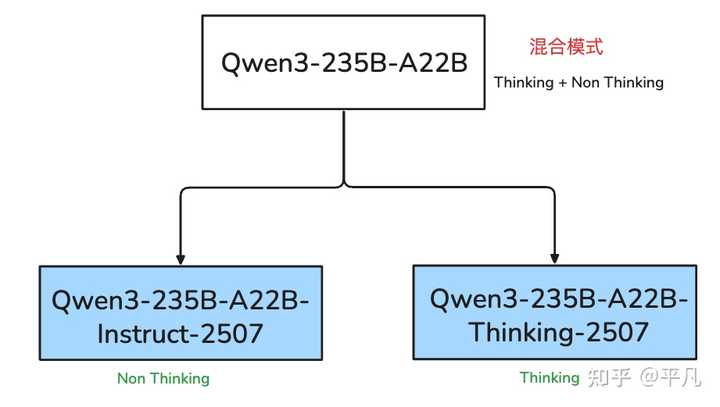
这一信息在论坛内引发了热烈讨论,毕竟几个月前还被视为技术领先的混合模式,现在却选择回归到思考与否的单一模式,这需要勇气。而结果显示,纯 thinking 模型的表现已跻身全球顶尖模型行列,其综合性能与 Gemini-2.5-Pro 和 O4-mini 相当。
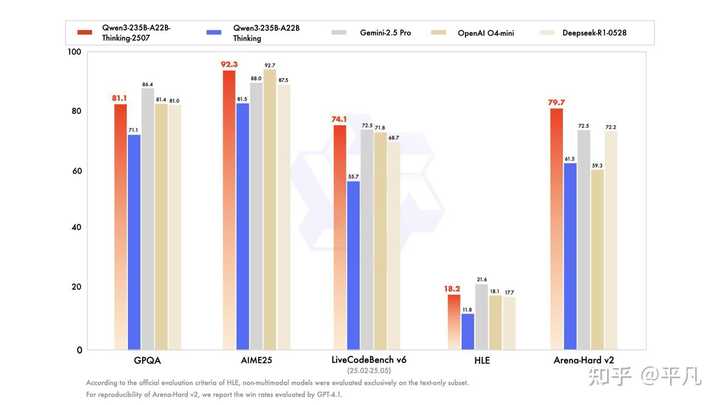
与此同时,该模型在上下文长度方面也有所提升,显然这是基于市场反馈进行的调整,毕竟在许多复杂问题中,上下文长度的重要性与模型本身的智力水平同样关键。
而在周一发布的 non-thinking 模型 Qwen3-235B-A22B-Instruct-2507,同样在业内引起了广泛关注,我在这里提到过对 Qwen3-non thinking 版本的看法,主要表现在根据市场反馈进行及时调整的勇气和决心。
同样,non-thinking 模型的性能也相当突出,去掉 thinking 后,算力和时间消耗都有显著提升,速度也有所增加。
数据和用户反馈表明这一决策是正确的,发布几天内就已在 LLM 竞技场上取得了第十名的好成绩。
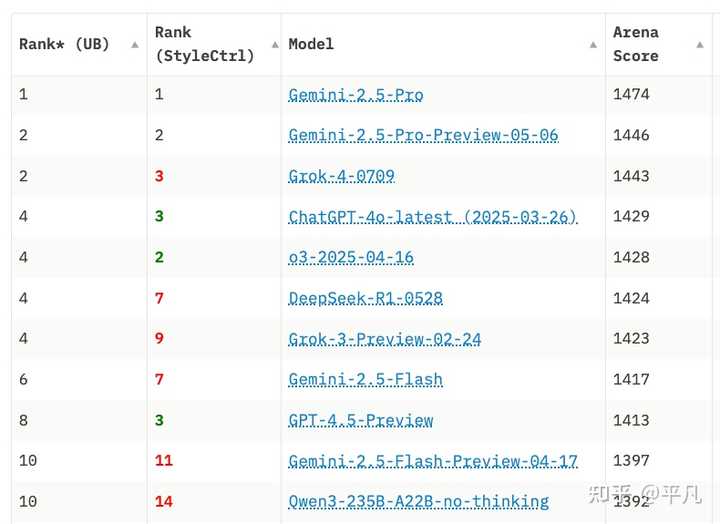
预计这一榜单很快会有变化,因为经过强化学习支持的后训练 thinking 模型将在许多需要推理的任务中表现更佳。
除了这两个模型,本周还有一款备受瞩目的新模型发布,即 Qwen3-Coder,这是基于 Qwen3 大模型专门针对代码生成与开发的模型。
我在下方这个回答中对 Qwen3-Coder 进行了测试,效果出乎意料地好。
阿里开源编程模型 Qwen3-Coder,性能可与全球顶级编程模型 Claude4 相媲美,技术亮点和使用体验如何?
尤其是这个代码模型给我一种“克制而理智”的印象,区别于同类产品 Claude,后者常常采用复杂的操作让人觉得其完成了很多任务,但结果通常令人失望。而 Qwen3-Coder 则思路清晰,能够高效考虑大多数任务,回头次数也仅有一两次。
从 token 消耗来看,其一个小时的消耗仅为 Claude Code 的 20% 左右,且作为开源模型,性价比极具优势。
从 HuggingFace 和 OpenRouter 这两个开源领域的风向标积极推文中也不难看出这一点。
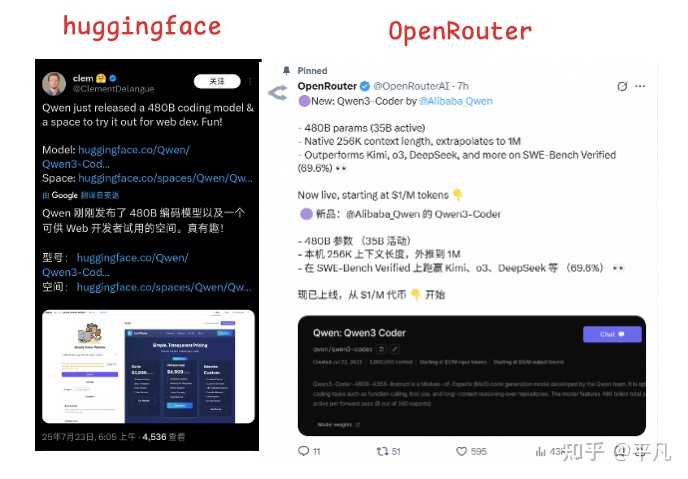
可以说,本周 Qwen 系列的三项重大更新,无疑使阿里在全球 AI 领域的地位更为重要。
以下是一张我非常喜欢的 Qwen 文化衫照片,可以看到 Qwen 的吉祥物卡皮巴拉已经在 AI 大模型圈中声名显赫。

可以说,AI 大模型的开源阵营已经成为中国的舞台,尤其是 Qwen3 旗舰模型的此次更新,其性能已可与 Gemini-2.5-Pro 相媲美,而后者是 Google 的闭源 AI 标杆。这次更新显示出中美之间的竞争格局正在发生变化,未来鹿死谁手尚未可知。
特别是 Qwen 系列自 2023 年起开始开源,现已覆盖几乎所有领域,模型数量更是超过 300 个。
这一数据令人震惊,因为 AI 的进步依赖于硬件和人才的双重支持,缺一不可。
阿里凭借其全方位布局,拥有强大的算力:阿里云(全球领先的公有云)、芯片(硬件设计与制造能力)、开源系列模型(人才及持续投资)、应用(Qwen3-Coder 一经推出便获得成功)、平台(魔搭 ModelScope),这每一个部分都令人惊叹。
若要找一个对标的公司,Google 可算一个,它拥有类似的架构,但 Google 的短板在于其彻底的闭源,而 Qwen 的一贯开源策略使其在用户口碑和社区建设上占据了明显优势。
最后,回到 LocalLLaMA 社区的反馈,用户对开源 AI 模型的喜爱程度非常高,短短几天内便有人分享了如何在低硬件上运行 Qwen3 的教程。
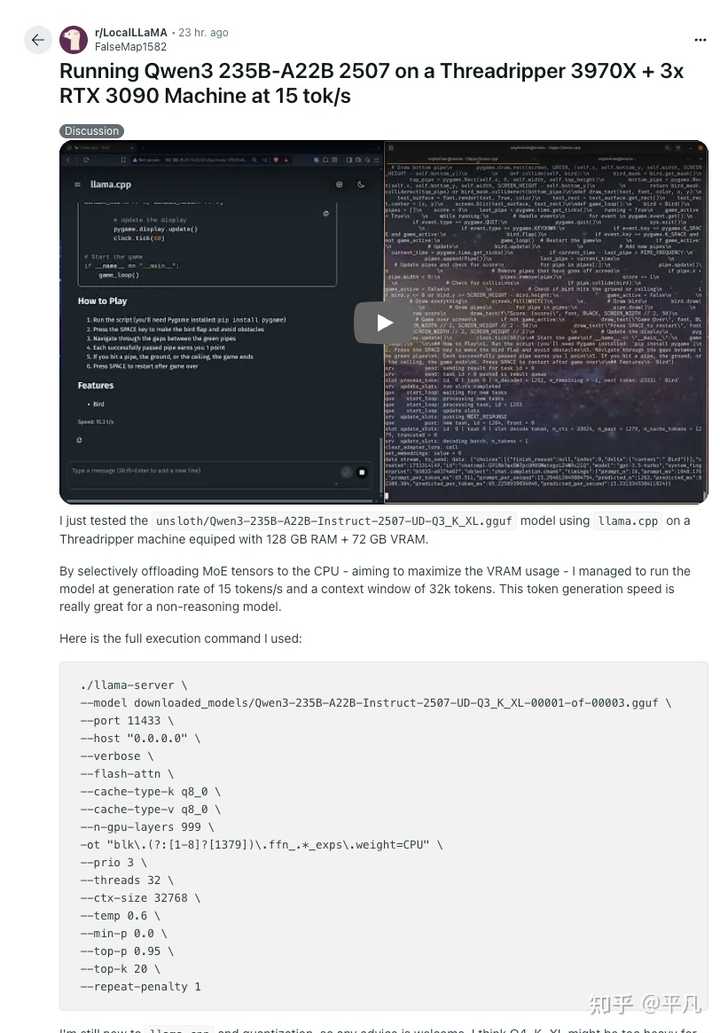
此次 Qwen3 的“三连发”便是一个有力的证明,短短一周内,可以看出阿里构建的“阿里云 +Qwen”路径走得相当稳健。这三项重大更新基本覆盖了基础大模型、推理大模型以及 Agent 能力这三个目前最重要的方向,而且都在全球范围内名列前茅,标志着中国的 AI 已经从“追随者”转变为“领导者”,而阿里则无疑是其中跑得最快、最稳的。