
共计 559 个字符,预计需要花费 2 分钟才能阅读完成。
Qwen3 最开始采用的是混合思维模式,然而在 2507 版本中又重新转向了传统的独立模型。
Deepseek 最初是基于两个独立的模型构建,但随着 V3.1 的发布,混合思维将 V3 与 R1 进行了合并,并更新了官网 API。
之前的看法似乎表明混合思维的实现并不简单,那么 Deepseek 为何选择训练这样的 V3.1 呢?无论是从技术层面还是八卦角度,均可探讨。
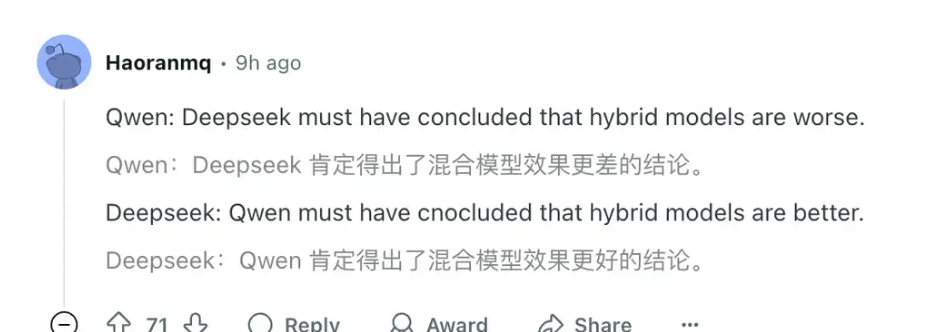
确实令人惊讶,毕竟就在不久前,Qwen3 将其原有的混合思维模型拆分成了两个独立模型,因为它们发现分开的效果明显优于合并。
不过,这一现象似乎并非绝对的定理,而是在特定条件下的观察结果。DeepSeek V3.1 则采取了不同的策略,将 V3 与 R1 进行了融合,重拾了 Qwen3 曾经放弃的混合思维。
简单来说,这个模型增加了一个思维开关,可以随时开启或关闭。
从 DeepSeek 一贯的节约理念出发,或许更容易理解其选择。
来源:知乎
原文标题: 为什么 Deepseek V3.1 和 Qwen3 在是否要做混合思考上做出了相反的选择?– 知乎
声明:
文章来自网络收集后经过 ai 改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!
正文完









