共计 1941 个字符,预计需要花费 5 分钟才能阅读完成。
在7月23日,Qwen3-Coder正式亮相,这是阿里巴巴目前推出的最具代理能力的编程模型。Qwen3-Coder包括多个版本,其中Qwen3-Coder-480B-A35B-Instruct是一个总参数达到480B,激活参数为35B的MoE模型,原生支持256K token的上下文,并且可以通过YaRN扩展至1M token,展现出卓越的编程和代理能力。该模型在Agentic Coding、Agentic Browser-Use和Agentic Tool-Use方面达到了开源模型的SOTA水平,表现与Claude Sonnet4相当。那么,它的性能究竟如何呢?

简短结论:单凭一己之力重塑编程模型格局
基本信息:
- 成本:$5每百万
- 平均行数:约200行(注释率13%)
- 速度:约160字每秒
- 平均耗时:46秒
编程成绩:
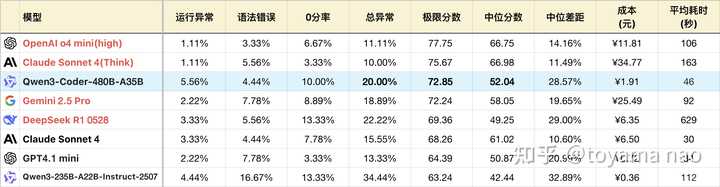
*表格经过适度裁剪以突出对比关系,未展示完整排序
**使用官方推荐的温度设置0.7
***测试方法详见大语言模型-编程能力测评 25-07月榜(新增C++)
****完整榜单更新可在Github查阅
编程语言分布:
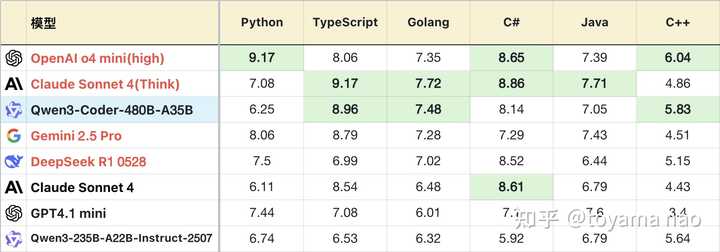
*图中,除了第一名以绿色标识外,其余与之相差0.3分以内的第二名也同样标绿。此举是考虑到测试本身的随机性,0.3分的差距可以视为同一水平。
本周是Qwen的开源周,每天发布一个新模型,今天的产品专注于各种编程应用场景的Coder版本。此前通用模型235B击败了自家的最强推理模型,因此参数更高、代码占比更大的Coder模型成绩更佳也在情理之中。虽然官方宣传称其“与Sonnet 4相媲美”,初看之下Coder的成绩确实在Sonnet 4之上,但实际上其错误率和稳定性都不及Sonnet 4。同时,Coder的错误分布较为均匀,而Sonnet 4的错误则主要集中在C++语言。Coder在多种语言上都有可能输出逻辑错误的0分代码,而Sonnet 4的0分主要集中在C++和少量Java问题上。
中位数排序显示,Coder的得分仅略高于GPT4.1 mini,低于OGA的三款模型,这意味着在实际使用中,Coder的整体体验稍逊于Sonnet 4。
接下来将进行更详细的对比分析。
优势:
- 对于任务要求清晰、需求明确的问题,Coder的表现相当不错。例如在第2题的正则表达式解析、第4题的售票系统和第10题的三视图投影中,Coder几乎能稳定获取满分,偶尔因考虑边界场景不周而失去几个用例。
不足:
- 推理能力:在题目中存在需要隐含推理的信息时,Coder的推理能力显得不足,无法理清问题的全貌,导致生成的代码只能部分应对测试用例。例如在第12题的函数计算器中,Coder的完成度不高。
- 代码冗长:Coder生成的平均代码行数可达200行,即使去掉注释,依然是21个模型中排名第三。其输出的代码中出现了“以勤补拙”的情况,如在第9题的文本解析器中处理HTML特殊字符时,Coder输出了30行代码来逐一列举各种字符,而实际上提取公共字符只需3行即可解决。在第11题的拼图问题中,Coder大量采用暴力穷举,导致代码冗长且执行效率低下。
- 突发性失忆:在因语法错误导致编译失败的场景中,有些情况尤其遗憾。例如在声明变量后不久,因产生幻觉而使用一个完全不同的变量名。
- 中英混合:在未明确指定的情况下,Coder输出的代码注释中大约一半使用英文,另一半使用中文,表现不稳定,偶尔会完全不写注释。然而,Coder的平均注释率为13%,并不算低。
- 代码中偶尔夹杂不可见字符NBSP,导致编译失败。如果用户的IDE未配置显示不可见字符,可能会在遇到这种情况时出现神秘错误。
赛博史官点评:
在国内无法方便使用Claude和OpenAI系列的情况下,一款具备在线编程能力的国产模型成为了迫切需求。可惜的是,无论是之前的Qwen2.5、Qwen3,还是字节的历代模型,都难以取代Claude的地位。新的Coder模型凭借其独特的优势,已经改变了现状,其高可用性和低成本使其在大部分场景中成为编程的首选。至于超越Claude,恐怕这一代模型尚难以实现,这仍需要大模型领域的专家们共同努力、齐心协力。阿里通义团队在大模型编程应用方面的长期投入终将收获成果。
目前所有评测文章将在公众号:大模型观测员上同步更新。