共计 3555 个字符,预计需要花费 9 分钟才能阅读完成。
快乐的QwensWeek!Qwen3推理模型震撼来袭!
全新开源的Qwen3-235B-A22B-Thinking-2507在推理能力和通用性能上实现了显著提升,与Gemini-2.5 pro、O4-mini等顶尖闭源模型相媲美,并在全球开源模型中创造了SOTA最佳表现:
- 在编程(LiveCodeBench)和数学(AIME25)等核心领域,Qwen3推理模型的推理能力取得了新的突破;
- 在知识(SuperGPQA)、创意写作(WritingBench)、人类偏好对齐(Arena-Hard v2)和多语言能力(MultilF)等方面,Qwen3推理模型同样展现了显著进步;
- 新模型支持256K长文本理解,轻松处理超长上下文。
期待大家从推理效果、工程集成、成本控制和上下文管理等方面分享您在试用或评估Qwen3-235B-A22B-Thinking-2507过程中的真实体验与深刻见解!
在这一周,AI界的焦点无疑是Qwen,短短几天内,该模型接连推出三款新作和一款附加服务:
- 周一:发布了Qwen3-235B非思考模式(Non-thinking),其性能与众多国内外顶尖闭源模型持平或超越,正面挑战Claude Opus 4的非思考版本。
- 周三:Qwen3-Coder-480B问世,参数量高达480B,其Agentic Coding能力与Claude Sonnet 4不相上下。
- 周四,尽管没有推出新开源模型,但基于Qwen3的大模型开发的翻译模型Qwen-MT作为附加服务,支持92种语言和方言,其性能优于同等级的GPT-4.1-mini和Gemini-2.5-flash。
- 周五:Qwen3-235B思考模式(Thinking)上线,再次刷新SOTA分数,成为当今全球最强的开源推理模型,性能与闭源的Gemini 2.5 Pro相抗衡。

这还不是结束,Qwen团队已经透露下周将继续发布新模型,暗示将推出更小、更快、更强的闪电级模型。这显然是一次经过精心策划的模型发布,我只想说:希望这样的发布能再来得更猛烈一些!
AI圈的朋友们开玩笑说,现在每天都要熬夜到深夜,以前是害怕错过海外的AI动态,现在则是担心一觉醒来,Qwen又一次重新定义了SOTA。
当然,Qwen并非故意让大家熬夜,而是因为真实的DDL冲刺。Qwen3-Coder熬了一夜,Qwen3-235B-A22B-Thinking-2507则在周五下午下班前正式发布(这次轮到国外团队熬夜了)。毕竟,Qwen的开源可不是简单的上传,而是为大家做了大量的上下游Infra社区工作。
这一波真是值得敬佩!Qwen团队的成员们一定要注意休息啊!下周二再发布flash模型也不迟!(狗头)
这样的发布节奏已经不仅仅是单纯的“卷”,我认为可以称之为饱和式开源,这正是Qwen的工作表现。
先来看一下最新发布的模型。
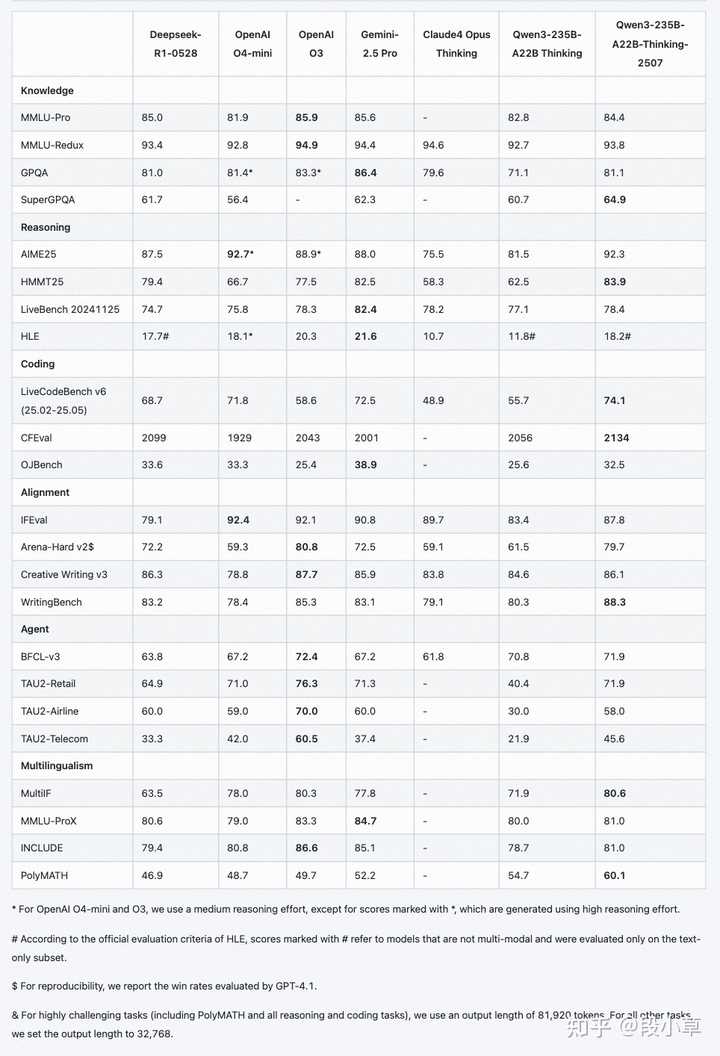
自四月底Qwen3发布以来,不到三个月,Qwen便推出了这次“小更新”。此次更新中,Qwen3的混合思维模式重新拆分为对话和推理两个模型,推理思维链的长度延伸至超过80k:
在推理模式下,Qwen3-235B-2507的分数相比于Qwen3大幅提升,在AIME25、LiveCodeBench v6、Arena-Hard等多个评测集上超越了Gemini 2.5 Pro和o4-mini等闭源模型:
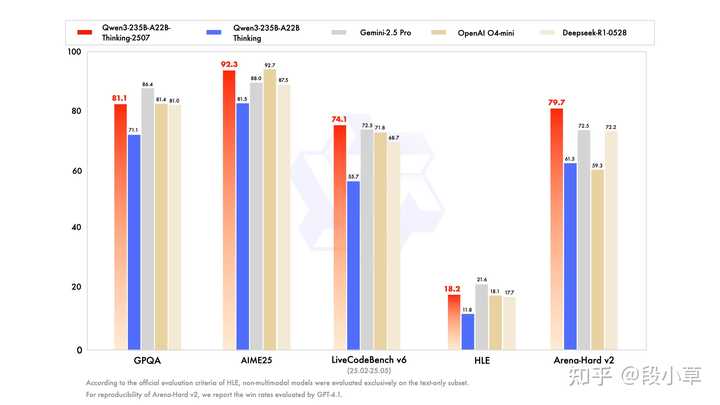
以下是更详细的分数:
QwenChat网站上已更新至最新模型版本,欢迎免费体验:Qwen Chat
对于有条件自行部署的用户,也可以通过HuggingFace或魔搭获取模型:
- https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
- https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Thinking-2507
为何大家选择Qwen,卷的尽头又是阿里?
除了模型的优异表现,今天我想多聊聊Qwen的开源影响力。
昨天有朋友问:“Qwen3真的能与Gemini 2.5 Pro相抗衡吗?”我回答:“当一个200B级别的开源模型被拿来与闭源SOTA对比时,它就已经不再是输家。”
许多普通用户对Qwen的体验和感受并不明显,有人则称我是“千问吹”。我觉得这很荣幸,就是要吹,不吹怎么让Qwen有动力继续开源。
我认为Qwen的成功归功于它实现了全尺寸、全场景、开发者友好的目标。
如今,Qwen已成为全球衍生模型生态中最庞大的基础模型。早在Qwen2.5时代,Qwen就已超越Llama的衍生模型数量,位居全球第一。今年以来,Qwen不断巩固其开源的霸主地位。
在HuggingFace平台上,基于Qwen的模型数量已接近15万个,占据HuggingFace上所有模型的7.9%。
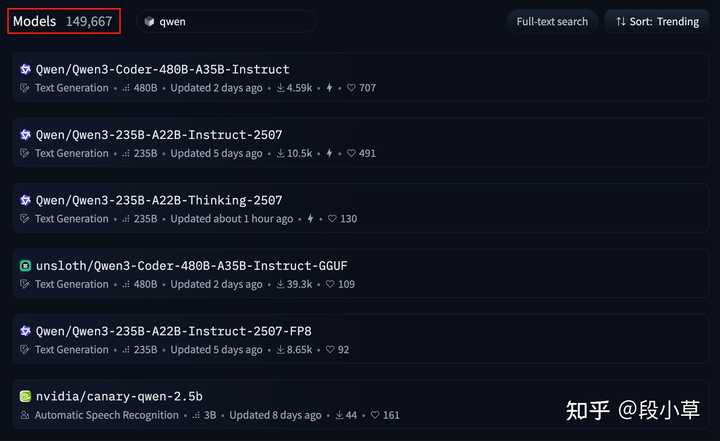
相比之下,Llama的衍生模型有13.5万个,BERT有4.2万个,Mistral有3.5万个,GPT有3.4万个。
值得注意的是,Qwen官方仅发布了327个模型,意味着每个模型都衍生出了成百上千个第三方模型。
这说明什么呢?
这表明大量开发者正以真金白银的GPU小时为Qwen投票,自发地基于Qwen训练自己的模型。
为什么选择Qwen?
- 首先是尺寸全,从0.6B到235B(以及480B的Coder模型),Qwen3几乎覆盖了所有场景,并在每个尺寸上都接近SOTA成绩。
- 其次是场景全,除了文本模型,Qwen还陆续推出了视觉模型、TTS模型等多模态模型。
- 更重要的是开发者友好。与一些模型仅提供权重,开发者需自行适配框架、进行量化和处理问题相比,Qwen的开源更像是“交钥匙工程”,省时省力。
Qwen每次发布后,社区都会迅速响应。HuggingFace、vLLM、Ollama、LMStudio等全球主流工具和社区几乎都能在第一时间完成兼容支持。这不是偶然,而是千问团队在模型发布前付出了巨大的精力去逐一对接、调试和优化的结果。
这种对开发者关系的极致重视,使得每个使用Qwen模型的人都能立即上手,而不是面对一堆文件无从下手。
毫不夸张地说,当前学术界和产业界在相当程度上依赖Qwen的基础模型进行科研和落地。高校的朋友甚至开玩笑说,研究组里的几个研究生就指望Qwen的小模型基座来顺利毕业。
因此,Qwen的开源工作是最彻底、最扎实的,这使得它能够吸引更多开发者,共同构建开放、繁荣、人人可用的技术生态。
国内开源与国外闭源,悄然变化的格局
如果我们把视线拉得更远些,会发现一个更大的竞争格局正在悄然变化。
随着大模型的兴起,美国一直是AI的风向标。一年前,OpenAI引领模型和产品的潮流,而Meta则是开源的佼佼者。但如今,情况正在发生转变。
- OpenAI曾表示将发布自GPT-2以来的首个开源模型,却一再失信;
- Meta在经历Llama 4的失利后,决定转向闭源阵营;
- xAI曾承诺开源上一代模型,而Grok 4发布时却未提及Grok 3开源的事宜。
- Claude、Gemini一向保持闭源…
当国外顶尖公司走向“闭源保守”时,以Qwen为首的中国力量,勇敢地扛起了开源的大旗。
这种悄然发生的战略逆转说明,中国企业不再是先进技术的追随者和使用者,而是正逐渐成为全球AI开源生态的“基础设施提供者”和“游戏规则的制定者”。
因此,我们看到,越来越多的国外开发者选择了Qwen,成为Qwen的忠实用户:
这,就是在这场技术竞争中,属于中国开源力量的阳谋。
总结:开源定义未来,Qwen已握船票
总的来说,这周Qwen的三连发,其意义远超模型本身。
- Qwen以硬核技术和卓越的分数,打破了闭源模型的性能垄断;
- Qwen通过极致的“饱和式开源”,提供了最全的尺寸和场景模型;
- Qwen以“交钥匙工程”的开发体验,吸引了大量社区朋友,赢得了全球开发者的认可。
对于中小企业和开发者而言,创新的门槛从未如此之低。曾经需要支付高昂成本的顶尖AI能力,如今触手可及,真正朝着科技平等和AI普惠迈进.
展望全球,当硅谷巨头们在开源和闭源的十字路口犹豫不决,甚至出现战略倒退时,以Qwen为代表的中国AI力量,用最果敢的行动给出了自己的答案:
最彻底的开放,才是最坚固的护城河。
下一个时代,或许真的会由开源来定义,而手握最强性能、最全矩阵、最大生态的通义千问,已经牢牢把握了那张驶向未来、问鼎全球的最重要船票。