共计 1422 个字符,预计需要花费 4 分钟才能阅读完成。
2025年4月29日,qwen-3正式发布。
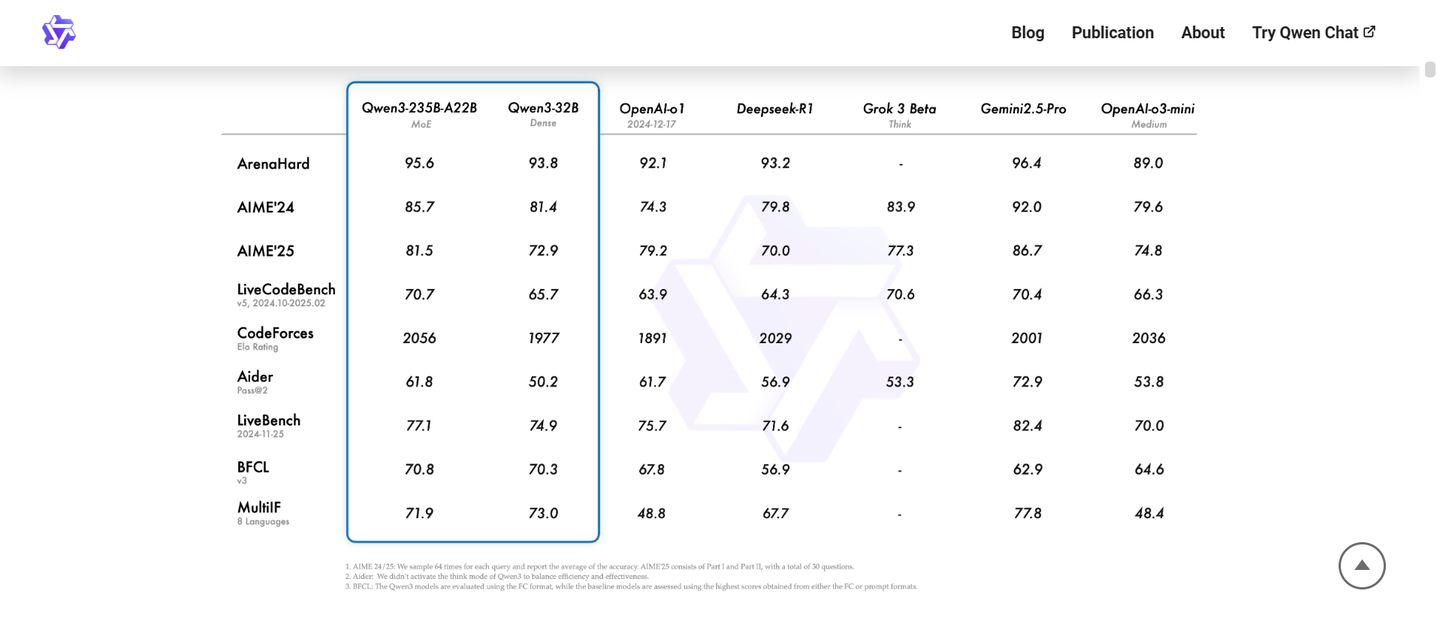
那么,这款模型在实际应用中表现如何?是否能在某些情况下与国外优秀的闭源模型如gemini 2.5 pro和o3相媲美呢?
https://qwenlm.github.io/blog/qwen3/
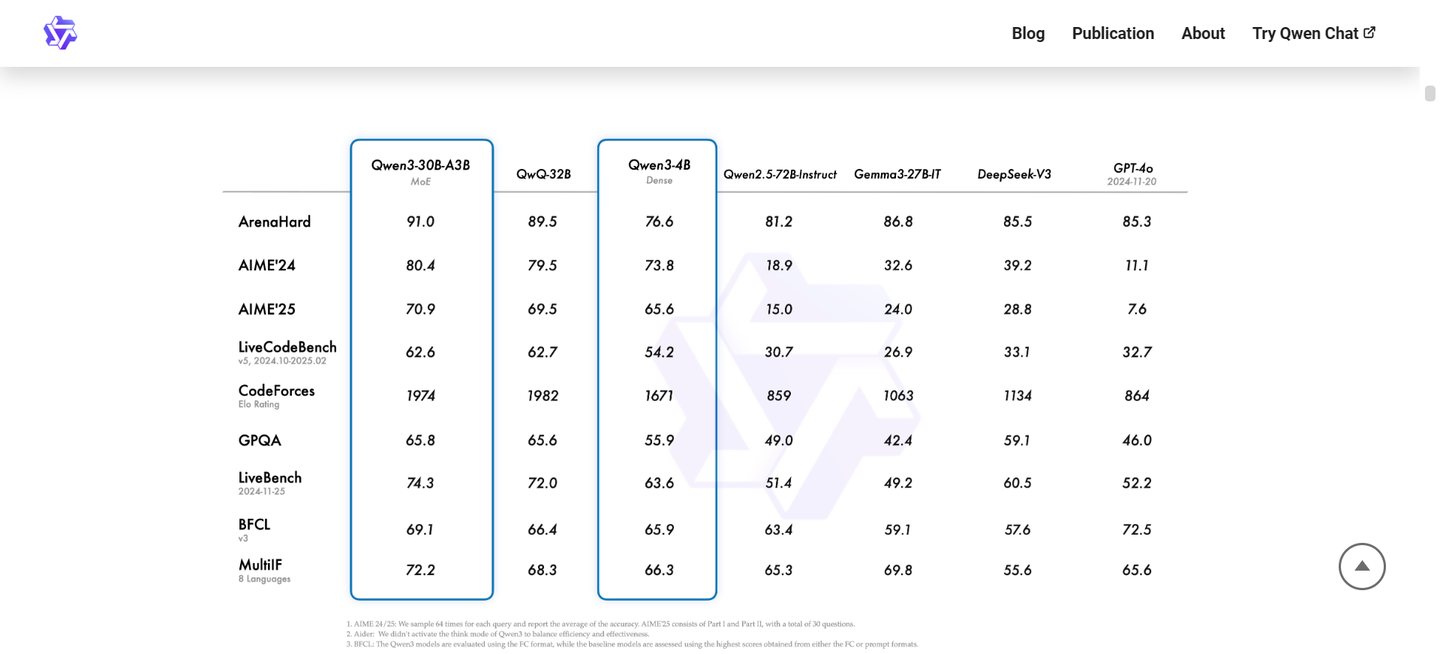
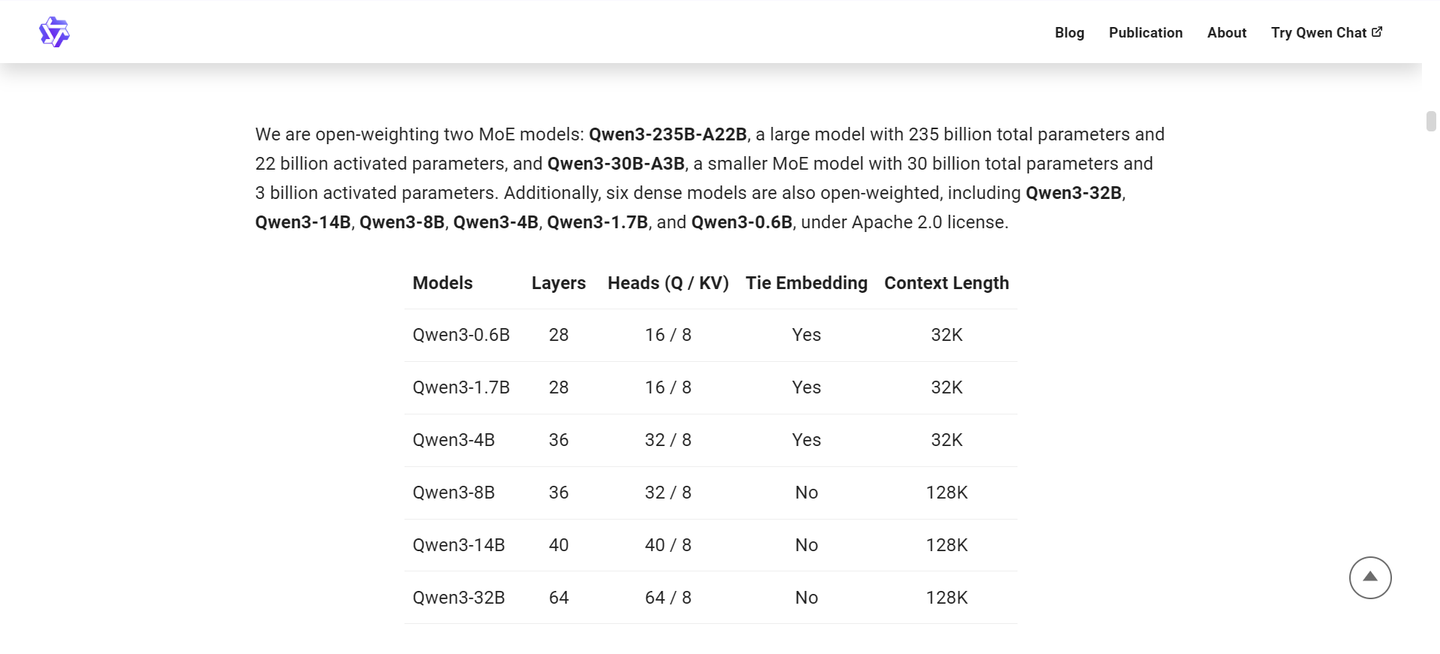
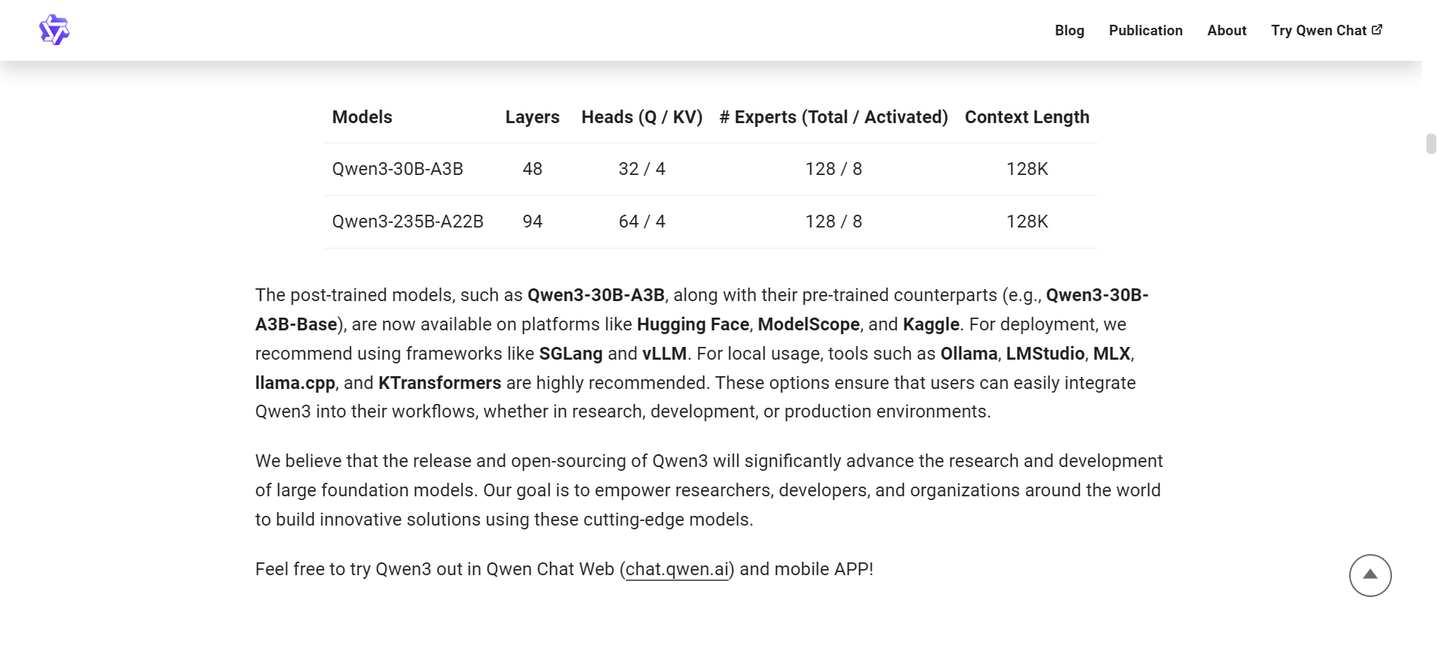

我将Qwen3 30B A3B这个模型称为“生存知识宝典”。
我拥有一台配置为AMD Ryzen AI 370、32G内存的Windows掌机。通过纯CPU AVX2来运行,在整体处理器功耗限制为12W的情况下,30B A3B Q4KM量化模型由于其MOE架构的特点,单次激活的参数量较小,因此可以实现8-10 tokens/s的回答速度,且其回答质量明显优于7B或更小的模型。
我常常思考,在极端生存情境中,人们如何获取必要的生存知识并重建文明——中国历史上曾有《赤脚医生手册》和1970版《十万个为什么》,意在编纂简洁的知识手册,以便迅速恢复最基础的工业文明。然而,我始终认为这种极为简明的书籍虽重要,但仍缺乏一些深度。毕竟,知道机动车上的电动马达可以发电与实际将其连接到简易风车或水车并接入电路之间的知识差距是巨大的,而简易知识手册无论如何无法涵盖这一部分知识。
直到大语言模型的问世,一个知识丰富的大语言模型显然远胜于传统手册。
然而,存在一个小问题:能耗。
在极端生存情况下,获取电能的难度可能相当大。好一点的情况下,或许能借助一块太阳能板在正午时段输出十几二十瓦的电力,而条件较差的环境下,或许只能依靠设备电池的剩余电量来获得有限的知识。因此,在这种情境下,评估一个大语言模型的适用性,就必须考虑生成一个token所需的能量。
根据我的测试,Qwen3 30B A3B在12W CPU功耗下可以实现平均9TPS的速度,这意味着在我的测试系统上,该模型的单token能耗约为1.33焦耳。相比之下,QWQ-32B在相同环境下的单token能耗则约为10焦耳。
在这种特殊使用情境中,推理型模型并不适用,因为推理型模型需要生成大量的思考token来提升最终回答的质量,这将导致其在回答问题时的能耗显著高于非推理型模型。而Qwen3恰好可以通过在问题后添加/nothink来强制模型不进行推理,这样在特殊工况下获取单个回答时,Qwen3 30B所需的能耗仅为QwQ 32B密集推理模型的约5%。
假设在紧急时刻,你需要针对当前困境获取急需的知识,而你的笔记本与我的掌机配置相同,剩余电量为50%。以典型笔记本电池容量(50-70瓦时)进行推算,你大约会有100,000焦耳的电能可以用来生成回答。这些能量足以让Qwen3 30B A3B输出约8万字,而QwQ 32B只能输出约4000字。
显然,Qwen3 30B A3B的输出能力已经接近一本简易手册的容量。虽然7B或一些更小的模型在相同能耗下也能输出如此多的内容,但这些小模型的知识量和回答质量却远不及以30B为基础的Qwen3。可以说,在这种特殊情况下,Qwen3 30B A3B具有无可比拟的优势。如果你拥有像太阳能电板这样的低功率能量获取方式,它甚至能够成为重建文明的种子。