
共计 1444 个字符,预计需要花费 4 分钟才能阅读完成。
在2025年6月6日的清晨,阿里巴巴正式发布了 Qwen3-Embedding 系列模型(包括Embedding和Reranker),这套模型专门为文本表示、检索和排序任务而设计,构建于Qwen3基础模型之上。
阿里巴巴推出Qwen3新模型Embedding及Reranker,展现卓越的多语言和跨语言支持
最近我正忙于研发RAG,恰巧通义团队发布了新模型,立刻就尝试了。普通工程师并不需要过于关注细节,使用即可。如果数据量较小,直接选用Qwen3-Embedding-0.6B就非常合适(相比我之前使用的bge-m3有显著提升),而重排模型则可以用Qwen3-Reranker-4B。
接下来,下面是我的正式分析:
① 模型结构的主要功能

Qwen3-Embedding以Qwen3 dense为核心。输入端将Instruction与Query组合成一条序列,同时保持Document不变,因而同一模型可以处理检索、STS和分类等多种场景,并支持32K的上下文长度,避免长文档被截断。
Embedding向量提取自最后一层[EOS]位置的隐藏状态,没有额外的池化层,这样推理路径更加简洁。
同一权重支持多种分辨率向量(MRL),如768、1024、4096等维度,能够灵活裁剪,方便在边缘或服务器端根据需求进行部署。
Reranker则将相关性判断简化为“yes/no”的二分类模式,只需查看下一个token的两项概率便可打分,接口友好,延迟较低。
② 训练流程的稳定性
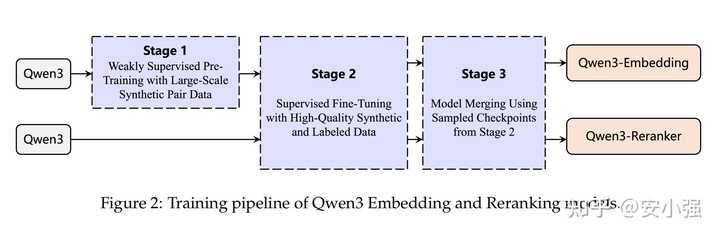
整体训练流程分为两个阶段:
第一阶段,利用Qwen3-32B自动生成超过1.5亿的多语言、多任务文本对,通过弱监督对比学习进行训练。这种“自举数据”相比于从论坛收集的数据具有更高的可控性,能够精确匹配任务、语言和难度。
第二阶段,结合1200万高质量的弱监督对和700万人工标注对进行监督微调,并通过Slerp插值将多个检查点融合,显著提高了在不同数据分布下的鲁棒性。
消融实验表明,若去掉弱监督或模型合并,性能会显著下降,证明这两个步骤是不可或缺的。
③ 最终效果的评估
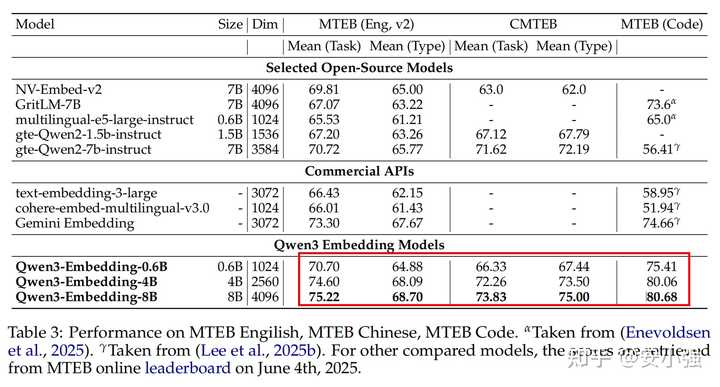
在MTEB-Code基准(nDCG@10)中,8B版本的得分达到了80.68,4B版本为80.06,甚至0.6B也有75.41,整体优于NV-Embed、GritLM以及Google Gemini-Embedding等商业模型。无论是英文、中文还是多语种检索均保持SOTA水平。
而Reranker的表现更为出色:
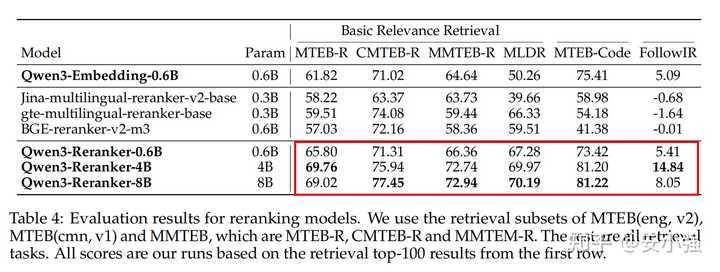
应用建议
在处理长文档RAG时,可以直接使用32K上下文,无需进行切片(不过根据经验,仍建议根据具体业务需求进行适当切分,我通常使用512的长度)。
在算力有限的情况下,可以选择0.6B + 768维;如果需要更高的精度,可以更换为4B/8B + 4096维。
对于Reranker,可以从前100个检索结果中提取,按照模板输出“Yes/No”概率即可。
欢迎大家交流。









