共计 1000 个字符,预计需要花费 3 分钟才能阅读完成。
今日,阿里通义千问在其官方网站及 OpenRouter 平台上正式发布了最新的 Qwen-3-Max-Preview 模型。根据官方信息,该模型被誉为通义千问系列中最为强大的语言模型。
IT之家提供了相关链接,具体如下:
- 官方网站:Qwen Chat
- OpenRouter:Qwen3 Max – API, Providers, Stats
关于该模型在 OpenRouter 上的介绍,主要信息如下:
- 输入费用:1.20 美元(现汇率约合 8.6 元人民币)/每百万 tokens
- 输出费用:6 美元(现汇率约合 42.8 元人民币)/每百万 tokens
Qwen3-Max 是对 Qwen3 系列的一次重要升级,相较于 2025 年 1 月的版本,在推理、指令遵循、多语言支持与长尾知识覆盖方面实现了显著的提升。该模型在数学、编程、逻辑与科学任务中表现出更高的准确性,能够更可靠地执行中文和英文的复杂指令,减少幻觉现象,并在开放式问答、写作和对话生成领域提供更优质的响应。
此外,该模型支持超过 100 种语言,具备更强的翻译能力和常识推理能力,并对检索增强生成(RAG)和工具调用进行了优化,尽管并未提供专门的“思考”模式。
Qwen3-Max-Preview 正式上线,官方称其为通义千问系列的最强语言模型
虽然模型规模庞大,但后续训练似乎不足,虽然知识面广泛,表达方式却显得随意,给人一种随意应对的感觉。
或许是因为该模型在基础训练中草率推出的,才会称之为Preview,真正的实力还需要等待后续版本的发布。
我故意输入了一些错误的信息,以测试其幻觉和知识储备,想看看千问会如何回应:
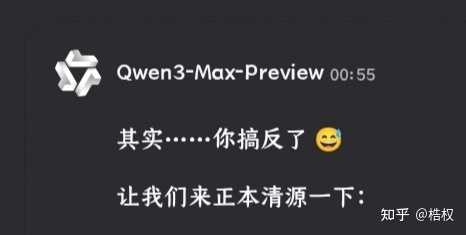
结果,它竟然回复了“流汗黄豆”。
在这段时间里,我深入使用了 Qwen3-Max-Preview,感觉它在直觉和知识储备方面表现得非常深邃。
在 Gemini2.5pro 和 GPT5 启动推理时无法正确回答的问题上,Qwen3-Max-Preview 作为一个非推理模型,却找到了解答,这让我感到意外。