
共计 1308 个字符,预计需要花费 4 分钟才能阅读完成。
阿里巴巴通义千问团队重磅推出Qwen3-235B-A22B-Instruct-2507-FP8模型,性能大幅提升
在7月22日的凌晨,阿里巴巴通义千问团队发布了其旗舰模型Qwen3的重大更新,推出了名为Qwen3-235B-A22B-Instruct-2507-FP8的新版本,标志着非思考模式(Non-thinking)的重大进化。
这一新版本在多个核心能力上实现了显著进步,不仅超越了Kimi-K2等一流开源模型,甚至在性能上也领先于Claude-Opus4-Non-thinking等顶级闭源模型。
那么,这次的升级究竟有多强大呢?
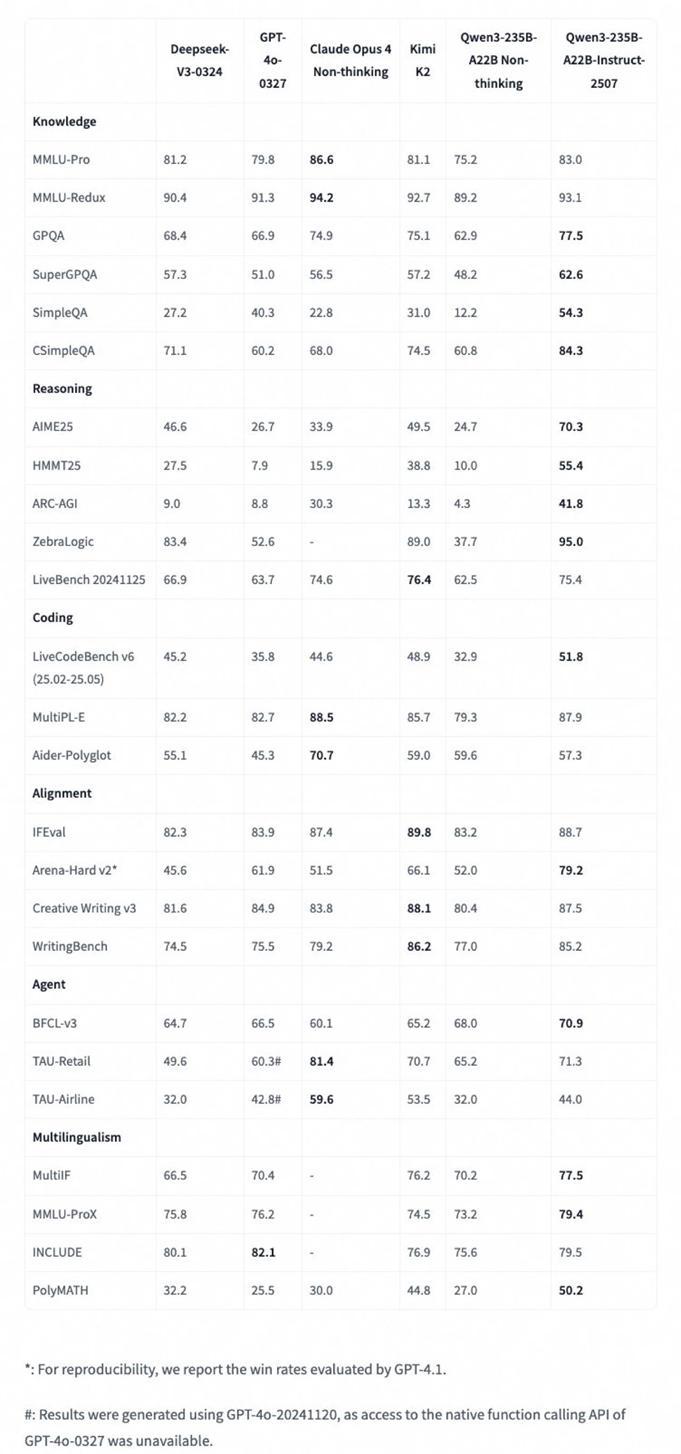
根据官方发布的数据显示,新模型的通用能力得到了全面提升,在多个权威评测中表现尤为突出:
在指令遵循、逻辑推理、文本理解、数学、科学、编程及工具使用等方面,它在GQPA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent能力)等多个评测中均取得了优异成绩,超越了Kimi-K2、DeepSeek-V3等顶尖开源模型和Claude-Opus4-Non-thinking等领先闭源模型。
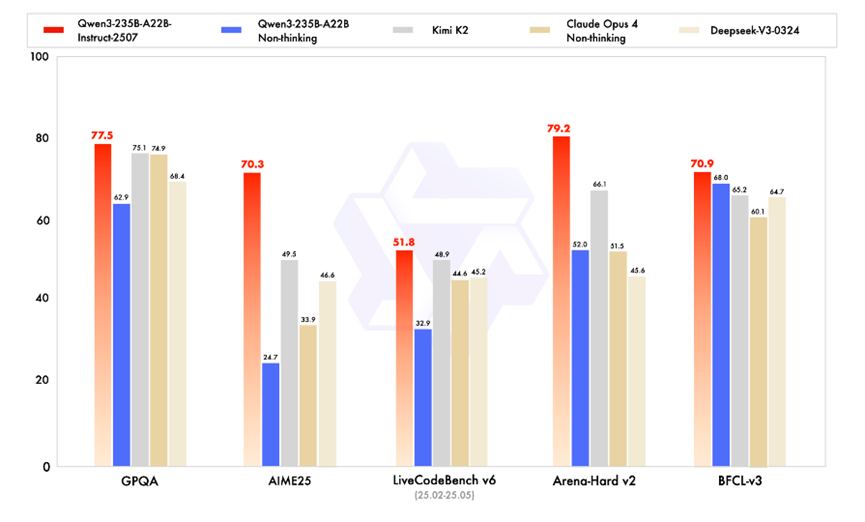
尤其值得注意的是,Qwen3模型在Agent能力方面的表现极为出色:在BFCL(Agent能力)评测中取得了卓越成绩。这表明该模型在理解复杂指令、自主规划和工具调用等任务上的能力,达到了一个全新的高度。未来的AI应用将围绕“主打Agent”这一核心竞争力展开。
除了令人瞩目的性能提升,本次更新还带来了三项显著的“体感”升级:
– 在多语言的长尾知识覆盖方面,模型取得了显著进展。
– 在主观和开放性任务中,模型显著增强了与用户偏好的匹配能力,能够提供更加实用的回复,生成更高质量的文本。
– 长文本处理能力提升至256K,进一步增强了上下文理解能力。
告别“混合思维”,分离训练带来的强大效果是什么?
此次更新的核心变化在于技术路线的革新。
通义千问团队宣布,正式放弃以往的“混合思维模式”,进入全新的“分离训练”时代。他们将用于直接回答的Instruct模型与用于复杂思考的Thinking模型进行独立训练。

简单来说,这种方式让“快思考”和“慢思考”各自发挥其优势,以在各自领域实现最优表现。
当前发布的Qwen3-235B-A22B-Instruct-2507-FP8,正是“快思考”路线下的最新成果。它专注于非思考模式(Non-thinking),旨在指令遵循、文本理解和知识问答等任务上实现更快、更准确和更强大的性能。
https://baijiahao.baidu.com/s?id=1838305117657836324&wfr=spider&for=pc








