共计 2214 个字符,预计需要花费 6 分钟才能阅读完成。
阿里巴巴的通义千问今天在官方网站及 OpenRouter 上发布了全新的 Qwen-3-Max-Preview 模型。根据官方说明,这一模型被誉为通义千问系列中最为强大的语言模型。
IT之家提供的链接如下:
- 官网:Qwen Chat
- OpenRouter:Qwen3 Max – API, Providers, Stats
在 OpenRouter 上,该模型的介绍如下:
- 输入费用:每百万 tokens 1.20 美元(现汇率约合 8.6 元人民币)
- 输出费用:每百万 tokens 6 美元(现汇率约合 42.8 元人民币)
Qwen3-Max 是对 Qwen3 系列的进一步升级,与2025年1月版本相比,在推理能力、指令遵循、多语言支持及长尾知识覆盖方面都有显著提升。该模型在数学、编程、逻辑推理及科学任务中展现出更高的准确性,能够更可靠地处理中文和英文中的复杂指令,明显减少幻觉现象,同时在开放式问答、写作及对话生成中提供更优质的回应。
此外,该模型支持超过100种语言,在翻译及常识推理能力上更为出色,并且针对检索增强生成(RAG)及工具调用进行了优化,尽管尚未包含专门的“思考”模式。
Qwen3-Max-Preview 上线,官方称其为通义千问系列最强大的语言模型
简要结论:偏科生的华丽蜕变
基本情况:
在Qwen3 235B初版发布后仅两个月,通义团队通过强有力的优化,将2507版本的逻辑推理能力提升超过50%,打造出一款冷静的推理机器。然而,用户也发现235B在知识问答和写作方面表现不佳,知识储备较少,跨学科的洞察力不足,编程能力同样存在许多缺陷,且在前端设计上不如K2。
幸运的是,通义团队还有一张王牌,那就是同样具备万亿参数的Max版本。参数的提升使得许多短板得以弥补,Max的知识量如同重生,学科知识丰富且有理有据,写作也不再单调,甚至展现出过人的词汇量。
Max的平均Token消耗比235B 2507低约15%,在阿里百炼平台上,分配的tps更高,能够达到35,使得Max的平均响应时间低至113秒,实用性极佳。
逻辑表现:
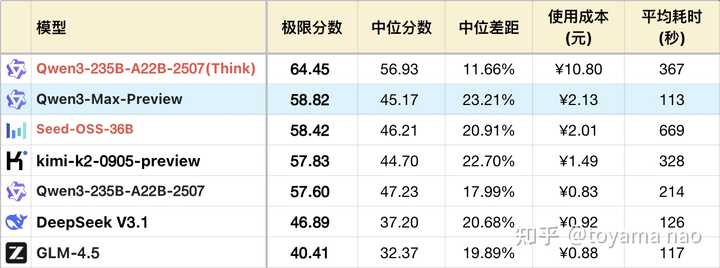
*表格仅展示部分可对照模型以突出对比关系,并非完整排序。
**题目及测试方式详见:大语言模型-逻辑能力横评 25-08月榜(GPT5/Qwen3/GLM4.5/DS V3.1)
***完整榜单更新可在Github查阅
Qwen3-Max与235B在大部分问题的表现相似,以下将重点描述其差异部分,读者可以参考之前的235B测评以了解其基本信息。
改进之处:
- 指令遵循能力:在很多与指令遵循相关的问题中,Max的表现普遍优于235B,特别是在#28数学符号重定义的题目上,除了需要遵循指令外,还需抵御按照原始定义进行计算的倾向,Max几乎达到了满分。在#40代码推导的题目中,Max的表现同样接近推理模型,几乎满分。
不足之处:
- 思路发散:或许是由于Max知识量丰富,在某些问题中,Max会尝试多种解法,甚至寻求创新的方法。然而,这些方法大多数无法成功执行,或者最终无法解决问题。例如在#32干支纪年问题中,正确的解法是发现数学规律并进行计算,而Max却尝试了至少四种方法,还试图编写程序,但最终未能得出正确答案。在#43目标数问题上,Max频繁更换思路,快速尝试后又迅速放弃,最终耗尽Token也未能完成题目。
- 数学误差:误差问题依然是qwen3系列的通病,Max也未能完全克服,在所有数学计算题中,Max都存在轻微的精度误差,在一些需要连续计算的题目中,误差会累积放大。例如在#22题中,Max与235B的表现相似,但在不涉及累计计算的题目,如#38函数交点,Max仍能保持对235B的优势。
编程表现:

*表格仅展示部分可对照模型以突出对比关系,并非完整排序。
**题目及测试方式详见:大语言模型-编程能力测评 25-09月榜(GPT-5/DS V3.1)
***完整榜单更新可在Github查阅
语言分布:
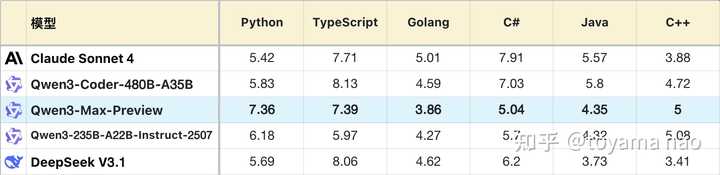
Max在编程能力上的提升主要源于指令遵循能力的优化,其基础异常率明显低于235B,而经过修正后的异常率甚至低于专门针对编程的Coder模型。语言分布在235B的基础上略有波动。再加上前文提到的百炼平台带来的更高tps,Max的平均响应时间低至49秒,接近Coder模型,使得Max在整体编程实用性上表现突出。考虑到Max目前仍处于预览阶段,待其正式发布后,超过Coder模型的可能性也并非遥不可及。
然而,Max的定价相对较高,实际使用成本仍高于Coder模型,因此Max更适合在Coder无法处理时出场,以解决疑难的Bug或生僻的SDK问题。
赛博史官评述:
从最初关于GPT-4是万亿参数级别大模型的传言,到如今真正的万亿参数模型已有两个,时间仅过去两年。万亿规模在各个方面展现出的优势,是低参数模型暂时难以企及的,未来其他活跃的大模型团队也有望在不久后发布自己的万亿模型。
自7月Kimi发布首个万亿模型开源以来,通义团队紧随其后,大模型竞赛正式进入万亿时代。
目前所有评测文章在公众号:大模型观察员同步更新。