共计 1722 个字符,预计需要花费 5 分钟才能阅读完成。
根据介绍,旗舰型号Qwen3-235B-A22B在代码、数学及通用能力等基准测试中,展现了与顶尖模型DeepSeek-R1、o1、o3-mini、Grok-3及Gemini-2.5-Pro等相媲美的表现。此外,小型MoE模型Qwen3-30B-A3B的激活参数数量仅为QwQ-32B的10%,其性能更为出色,即使是像Qwen3-4B这样的较小模型,也能与Qwen2.5-72B-Instruct相抗衡。
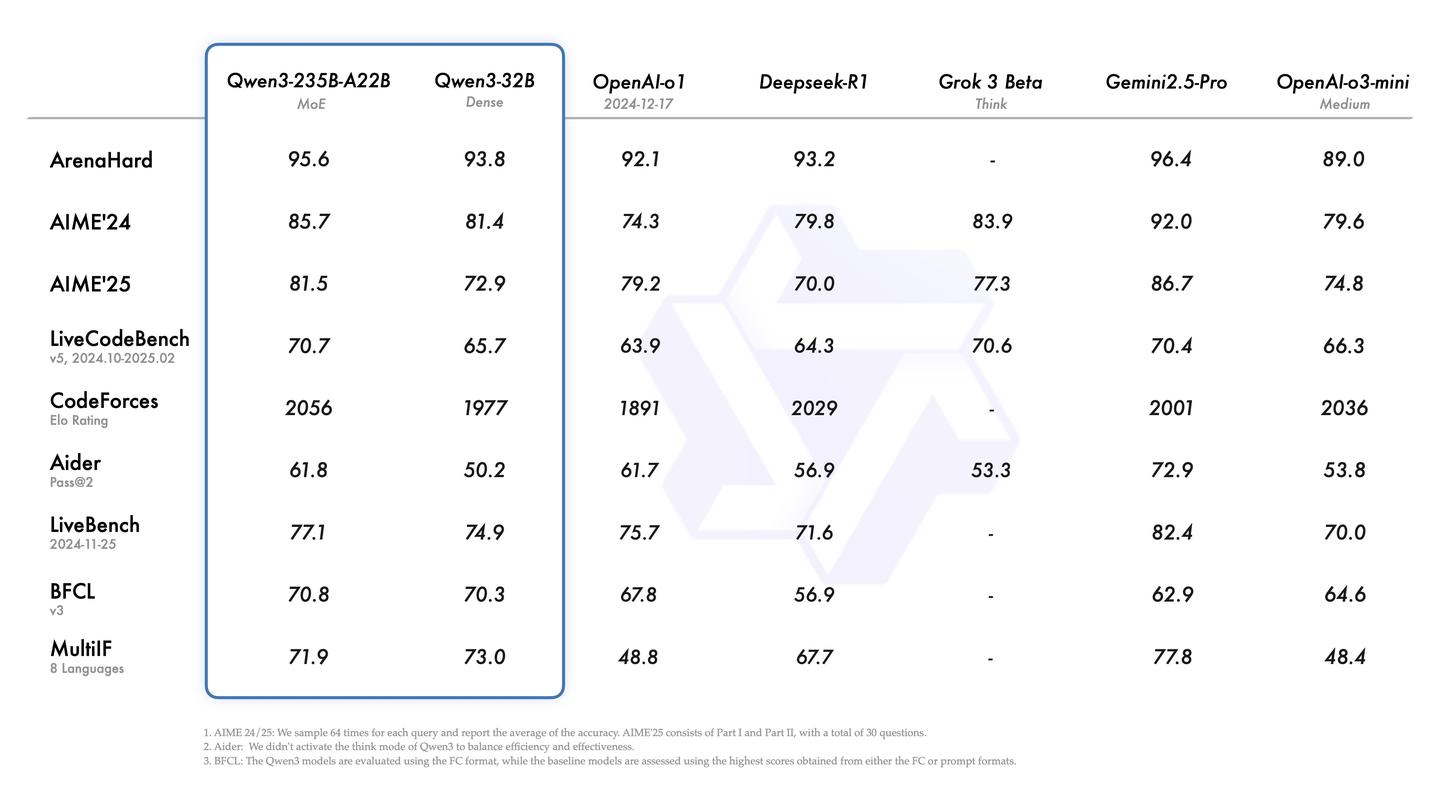
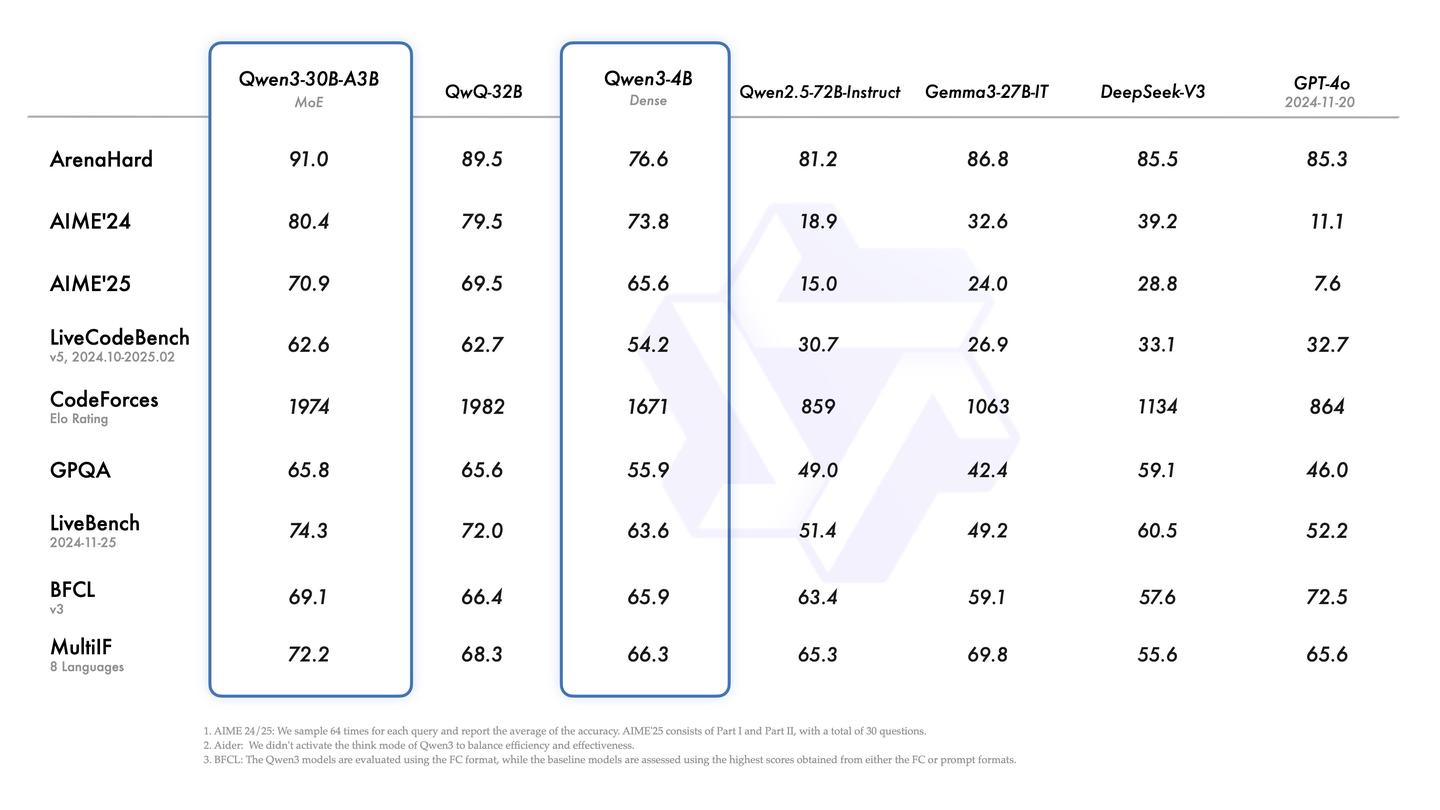
虽然Qwen3未能超越目前最强的闭源模型,但开源SOTA的最大优势在于其便于本地化部署,换句话说,它非常适合企业级的大模型应用。
在当前大模型开发的环境下,如果数据可以跨境,或者目标是出海业务,可以选择Gemini、GPT、Claude等知名产品。然而,若是专注于国内市场,模型就需要进行备案。如果可以使用API,选择的范围还算广泛;但若对数据安全有较高要求,必须进行本地化部署的选择就仅限于DeepSeek、Qwen和GLM。
之所以认为Qwen适合本地化部署,主要体现在两个方面。
首先是尺寸齐全。尽管DeepSeek表现出色,但其只有671B这一选项,其他几个蒸馏模型则依赖于Qwen和Llama作为基础。DeepSeek的一体机价格动辄200万,并且只能部署V3/R1中的一个模型,实话说,这对于普通企业而言并不容易承受。更别提微调了,相较于推理,其所需的算力更为庞大。
因此,Qwen在高校研究生和第三方开发者中获得了良好的口碑,因为它提供了中小尺寸的模型,让更多的人能够实践模型的部署和微调。
其次是对话与思考的结合。自去年9月o1发布以来,深度思考模式已成为大模型的标配,R1的成功也在于此。然而,之前的对话模型与深度思考模型是分开的,OpenAI目前的GPT系列和o系列也未合并。
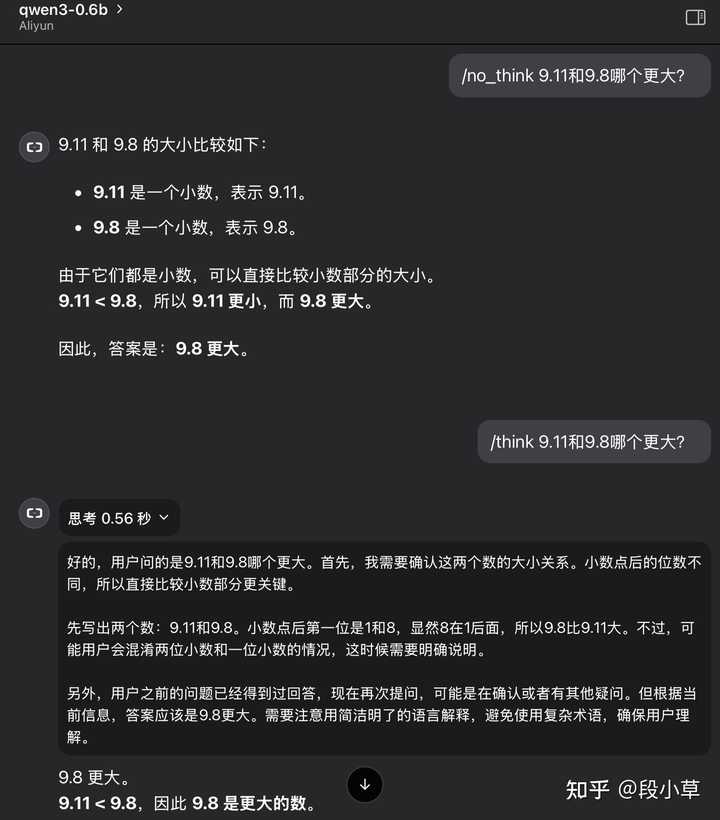
此次Qwen3将思考和非思考功能整合在一起,全系列模型均支持思考模式,使用者可以灵活控制思考的开关。

- 通过推理/非推理模型启动,只需在启动时调整 –enable-reasoning –reasoning-parser两个参数;
- 在推理模式下启动后,可以通过请求参数中的enable_thinking=True|False来控制模型是否进行推理;
- 即使在enable_thinking=True的情况下,也可以通过用户提示或系统消息中的/think和/no_think来切换思考模式。
效果示例如下(0.6b模型):
如果希望在个人电脑上进行本地部署测试,可以直接使用ollama进行安装,默认选项为8B模型,如果显存达到24G,可以尝试30B的MoE或32B模型(Q4_K_M),这可能是目前消费级显卡上能够体验到的最强模型。
ollama run qwen3:30b今年对于AI开发者而言依旧是利好的年份,Qwen3的性能和成本效益都十分突出。如今,开发AI应用变得相对简单,只需掌握一定的AI基础知识,了解大模型的技术原理及AI的能力界限,即可开发出属于自己的AI应用。
对于具备一定编程基础的开发者来说,这并不算困难,而且是一个不错的机会。如果你希望转向大模型开发但缺乏相关基础知识,我推荐参加知乎知学堂的「大模型全栈开发课程」,由行业专家系统讲解大模型应用开发的基础知识,帮助大家快速掌握大模型的技术架构和业务落地场景。目前为期两天的直播课程限时免费,点击下面的卡片即可领取↓↓↓
如果可以使用在线API,目前至少有三个平台可供选择:阿里云百炼、SiliconFlow和OpenRouter。
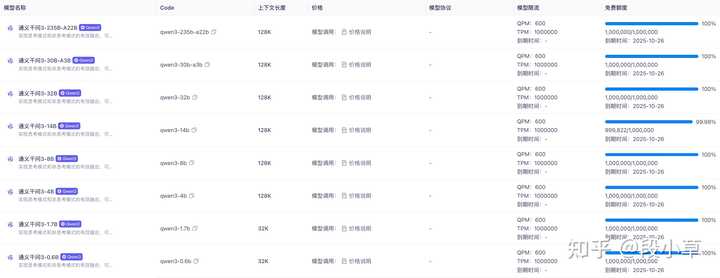
在阿里云百炼上,Qwen3的每款模型均提供100万tokens的免费体验额度:
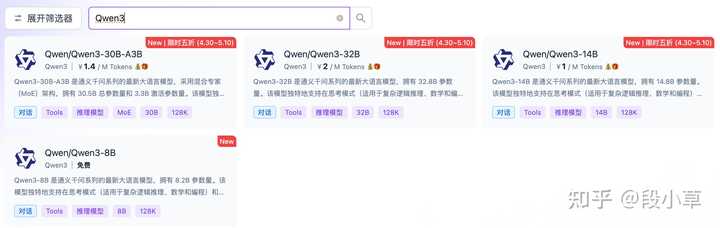
SiliconFlow上当前有四款模型可供使用,其中235B似乎尚未调试完成:
OpenRouter上则提供Qwen3 235B,每天也有免费的调用次数: