共计 2384 个字符,预计需要花费 6 分钟才能阅读完成。
在 5 月 6 日,科大讯飞(002230.SZ)正式推出了其新的认知大模型,名为“星火”。
当一些企业对大模型的商业化前景感到不安时,科大讯飞却顺应潮流,不仅在发布会上积极收集问题进行实测,还为大模型制定了七个评测维度。
值得一提的是,红星资本局观察到,科大讯飞已成为国内首个将大模型应用于实际的公司,并推出了针对教育、办公、汽车等多个行业的解决方案。
科大讯飞在人工智能领域的十年积累,成为了此时如星火燎原般的重要推动力。
现场互动与测试
科大讯飞的实际举措,七大评测维度
科大讯飞的做法令人瞩目。
在发布会当天,董事长刘庆峰和研究院院长刘聪共同在现场短短几分钟内就收集了上千个提问,并随机选择了 5 个进行现场测试。
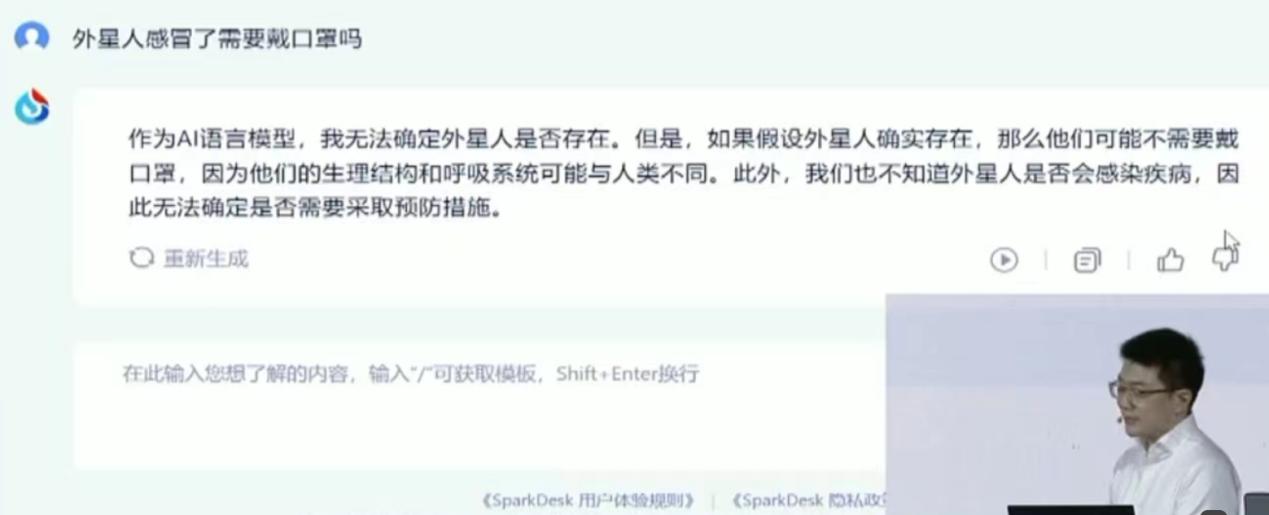
——“外星人感冒需要戴口罩吗?”
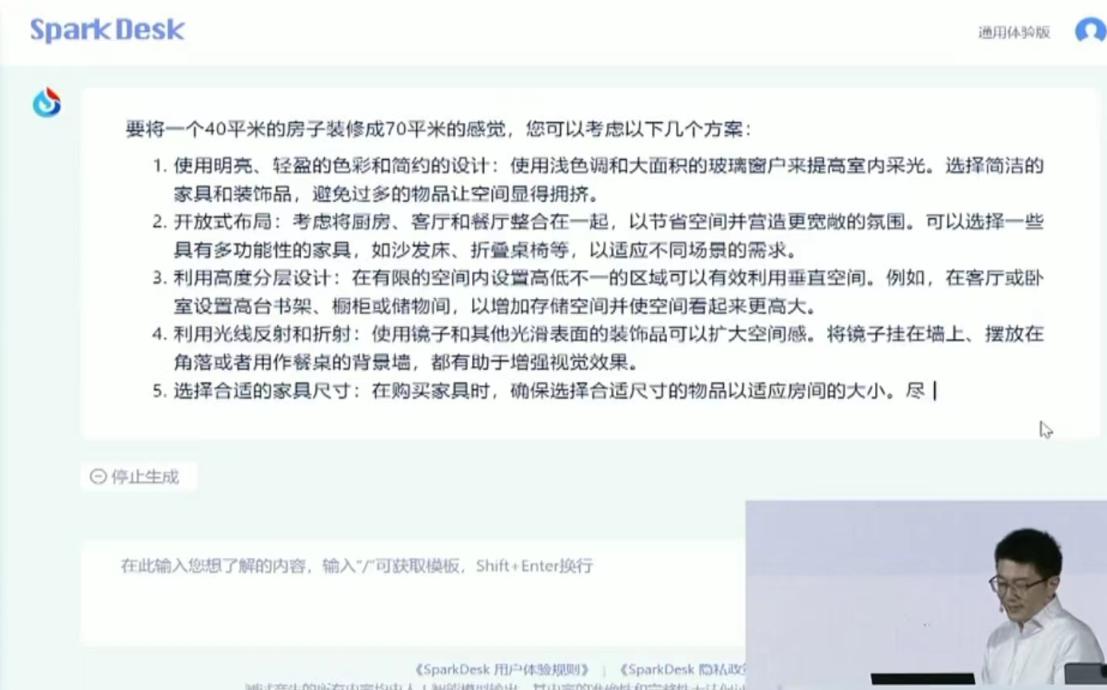
——“我想把 40㎡的房子装修成 70㎡的感觉,请给出可行的方案。”
——“在公共场合大声喧哗会影响他人的心情,那小声说话是否就不会影响?”
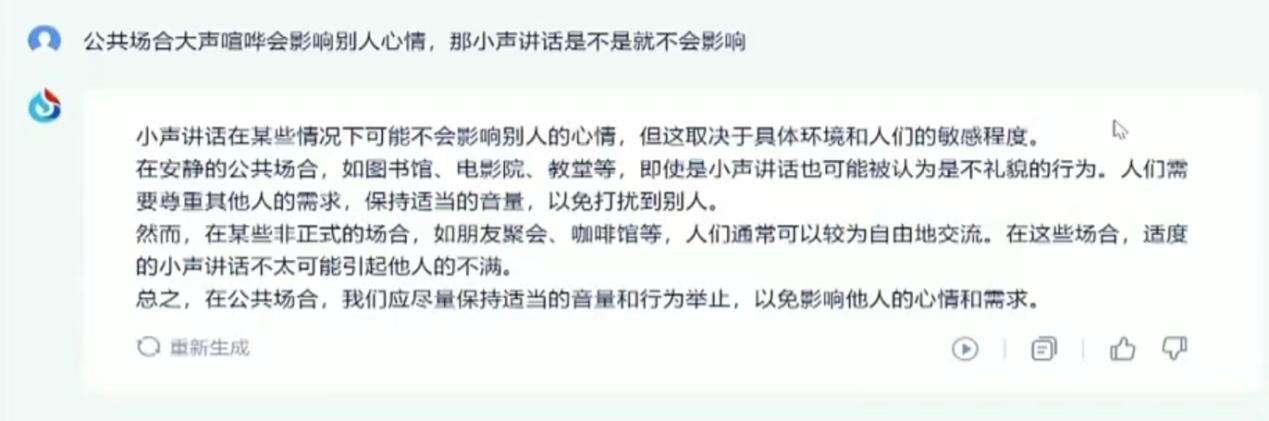
如果仅通过回答这些问题来验证星火的能力,那科大讯飞无疑会陷入常规。但刘庆峰显然更具前瞻性,他并非从企业的角度看待问题,而是从整个行业的视角出发。
“我想强调的是,若我们希望认知智能真正解决社会的实际需求,而不是仅仅停留于宣传层面,就必须建立一套科学系统来进行评估。”刘庆峰指出。
作为人工智能的先行者之一,科大讯飞通过全国重点实验室的合作,设计了一套评测体系,并与相关联盟共同探讨,形成了覆盖七大维度的 481 个细分任务,以评估通用认知大模型的能力。
这七大维度包括文本生成、语言理解、知识问答、逻辑推理、数字能力、编程能力和多模态,星火在发布会上接受了每个维度的考验。
——“请问孔子在 2008 年奥运会上说了些什么?”

——“等腰三角形的顶角是底角度数的两倍,请问这个三角形的底角是多少度?”

——“俗话说,男子汉大丈夫宁死不屈;但又有说法强调,男子汉大丈夫能屈能伸。这两种说法应如何理解?”

红星资本局在现场发现,虽然星火在某些维度上的表现有时略显不足,但整体来说表现出色,尤其是在多模态这一维度上,其表现可谓令人印象深刻。
刘聪首先通过语音输入,要求星火以“立夏”为主题写一篇 200 字的散文,接着又要求其用温柔的男声进行朗读,每个任务星火都顺利完成。甚至在被要求生成女性形象的虚拟人进行朗读时,星火在不到 10 秒的时间内成功创建了相关视频。
从接收语音需求到文本生成,再到语音朗读和实时生成虚拟人,星火展现出大模型可能带来的多样化形态与能力,让我们意识到大模型在日常生活中的另一种无限潜力。
行业对落地的担忧
科大讯飞一口气推出多项落地产品
目前,业界普遍认为,通用认知大模型的商业化前景仍不明朗,行业应用的落地依旧存在不确定性。而科大讯飞凭借多年在 AI 领域的深厚积累,此次推出了多款搭载大模型的产品。
以教育领域为例,科大讯飞的 AI 学习机 T20 系列已经实现了中英文作文的类人批改功能。
刘庆峰指出,作文能力的提升在语言学习中往往非常困难。因为针对性的指导和批改耗时耗力,教师难以对每位学生进行深入的分析与指导,而星火则为此提供了一种全新的解决方案。
从现场演示来看,这款学习机不仅能进行字词标点的纠错、识别句式和修辞错误等基本功能,还能围绕写作要求分析整篇文章的结构和文采,例如提出某一句可以优化、建议加入动作描写和人物状态的描写等。
相较之下,学习机可能仅调用了星火在文本生成、语言理解等方面的能力,而另一款产品则更全面地体现了星火的多维能力——“大模型 + 数字员工”。
在发布会上,刘聪要求星火复盘科大讯飞的“飞凡计划”,在无人干预的情况下,星火自动登录 HR 系统,按照要求导出数据、分析数据并生成 PPT。
红星资本局注意到,这一过程中,星火调动了语言理解、逻辑推理、数字能力、编程能力和多模态等多方面的能力来完成指令。
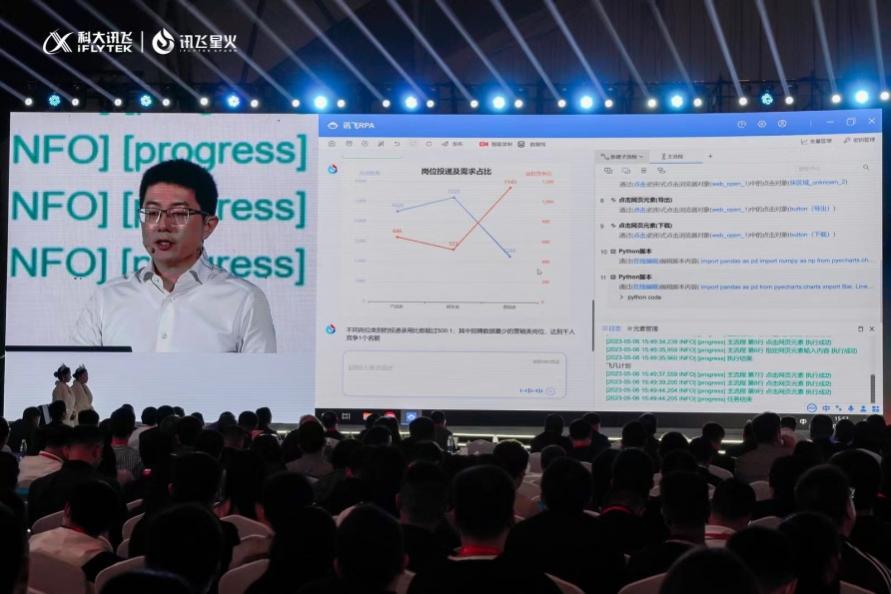
星火正在对科大讯飞的“飞凡计划”进行复盘
实际上,除了上述两个领域,科大讯飞还展示了星火在办公和汽车领域的应用成果,如“大模型 + 智能办公本”、“大模型 + 讯飞听见”和“大模型 + 智能座舱”等。
从目前来看,科大讯飞无疑是首个实现大模型落地应用的企业。可以说,星火的现状,或许正是许多投身于 AI 创业浪潮的人的梦想未来。
科大讯飞的深厚积累
在数据、算法、模型和算力方面均具优势
那么,科大讯飞为何能成为首个实现大模型应用落地的企业呢?
正如刘庆峰在发布会上所言,“这次的认知大模型本质上是一次对话式的通用智慧的涌现,语音与语言的核心能力是基础条件。”
红星资本局注意到,科大讯飞早在 2011 年就开始建设语音及语言信息处理国家工程实验室,并在认知智能领域持续投入研发,已有十几年的积累。
以数据为例,刘聪今年曾对媒体表示,在严格遵循法律法规的前提下,科大讯飞在多年的认知智能系统研发与推广中,积累了超过 50TB 的行业语料库,并且每天有超 10 亿人次的用户交互活跃。
当然,仅仅拥有数据是不够的,优秀的算法和模型同样至关重要。
科大讯飞的财报显示,其在认知智能大模型的核心——Transformer 深度神经网络算法方面积累了丰富的经验,并广泛应用于语音识别和图文识别等领域,已达到国际领先水平。
此外,科大讯飞已经开源了 6 个大类、超过 40 个通用领域的中文预训练语言模型,相关模型库的月均调用量超过 1000 万,Github 平台的星标数量在同类模型中名列前茅。
这一切也反映在科大讯飞逐年上升的研发投入上。根据财报显示,过去五年中,科大讯飞的研发费用分别为 12.63 亿元、16.40 亿元、22.11 亿元、28.30 亿元和 31.11 亿元。
更为重要的是,科大讯飞在算力方面拥有显著优势。
在今年 4 月,科大讯飞通过投资者关系活动记录表披露称,其自建了业界顶尖的数据中心,并已建立 4 城 7 中心深度学习计算平台,为大模型的训练提供了坚实的硬件基础。
这或许正是科大讯飞敢于喊出“10 月底整体赶超 ChatGPT”的自信所在,我们将拭目以待。
(唐浩)
(下载红星新闻,报料有奖!)