共计 2135 个字符,预计需要花费 6 分钟才能阅读完成。

一、2025 年 AI 大模型 的技术演进方向
生成式 AI 正从单一文本生成向多模态融合转型,2023-2025 年期间模型架构呈现三大变化趋势:
二、避开选型两大认知误区
2.1 参数迷信症的破解之道
企业常陷入 ” 参数越大越好 ” 的思维定式,实测数据显示:当模型参数量超过业务需求阈值后,每增加 100 亿参数带来的准确率提升不足 0.3%,但推理成本上升 15-20%。某汽车零部件厂商的对比测试表明,在质量检测场景中,700 亿参数模型的误报率反而比 1300 亿参数版本低 1.2 个百分点。
2.2 盲目追新的代价清单
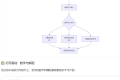
三、三维选型框架实战应用
3.1 需求锚定四象限法
将业务需求按响应时效(毫秒级 / 秒级)与知识密度(常识 / 专业)划分为四个象限:

3.2 生态适配度检测清单
开发对接成熟度、数据管道兼容性、运维监控体系三大维度共 18 项检测指标,其中关键三项:
3.3 持续进化能力评估
观察模型在以下场景中的表现:
实际操作三维选型框架时,先拿张白纸把业务需求拆解成两个维度:左边写 ” 响应速度 ”,标注清楚哪些场景必须毫秒级反馈(比如在线客服),哪些能接受秒级延迟(像报表生成);右边列 ” 知识类型 ”,区分哪些需要常识判断(用户情感分析),哪些必须专业领域知识(工业设备故障诊断)。把这俩维度交叉画个田字格,四个格子立马显出真章——电商推荐系统往往卡在 ” 即时响应 + 常识型 ” 区域,这时候选 50 亿参数的轻量模型就够了,别一股脑全上大模型烧钱。
生态适配这块得带着放大镜查技术细节,重点盯三个命门:第一看模型能不能转成 ONNX 格式,这直接决定能不能塞进现有服务器;第二查数据管道,特别是权限体系能不能跟公司数据湖无缝对接,别搞出数据泄露的幺蛾子;第三必须让模型在推理时输出注意力热图,这样出了问题能快速定位是哪个模块抽风。至于持续进化能力,每月 1 - 2 次的安全更新是底线,最好选能动态扩展 5 - 8 个接口的架构,哪天老板突发奇想要接新业务也不至于重头再造轮子。

如何判断大模型参数是否超出业务需求?
当模型参数量超过业务需求阈值时,每增加 100 亿参数带来的准确率提升不足 0.3%,但推理成本会上升 15-20%。通过压力测试观察误报率变化,例如在质量检测场景中,700 亿参数模型可能比 1300 亿参数版本误报率低 1.2 个百分点。
边缘计算适配需要哪些关键技术支撑?
主要依赖知识蒸馏和动态稀疏化技术,前者通过迁移学习保留核心能力,后者通过动态调整神经元激活范围,可将推理速度提升 40-60%。这两种技术能实现 200-500 亿参数量级模型在边缘设备的稳定运行。
三维选型框架具体如何落地应用?
需求锚定阶段需划分响应时效(毫秒级 / 秒级)与知识密度(常识 / 专业)四象限,生态适配需检测 18 项指标中的关键三项:ONNX 运行时支持、数据湖兼容性和注意力热图监控,持续进化则要求安全补丁更新频率保持在每月 1 - 2 次。
基础大模型与行业精调模型如何选择?
研发创新场景 使用 1000 亿 + 参数的基础大模型(延迟 300-500ms),生产系统推荐 200-500 亿参数的行业精调模型(延迟 100-200ms)。后者通过预训练阶段注入行业知识,专业语料库构建成本已下降 75%。
行业知识注入的成本变化体现在哪些方面?
2023-2025 年期间,生物医药、机械制造等领域的专业语料库构建成本下降 75%,主要得益于自动化标注工具和领域自适应预训练技术的成熟,使得行业知识注入从后期微调提前到预训练阶段。
声明:本文涉及的相关数据和论述由 ai 生成,不代表本站任何观点,仅供参考,如侵犯您的合法权益,请联系我们删除。