共计 1915 个字符,预计需要花费 5 分钟才能阅读完成。

一、用户权益调整引发行业震动
凌晨三点程序员小李正准备调用 AI 大模型 调试代码,突然发现 API 调用次数用尽。这不是个案,过去两周社交平台累计出现 2800+ 条类似吐槽。有用户晒出 2023 年购买的永久会员协议,明确写着 ” 不限次调用基础模型 ”,现在后台却显示 ” 月度限额 200 次 ”。
争议集中在三个层面:
二、官方升级方案的技术解析
在舆情发酵 48 小时后,技术团队公布底层架构改造方案。新系统采用分布式算力池设计,通过动态资源分配算法缓解高峰期拥堵。有工程师在 GitHub 贴出流量监控截图,显示北京地区晚 8 -11 点的请求成功率从 73% 提升至 91%。
具体升级包含:
测试数据显示,在同等算力消耗下,文本生成速度提升 40%,图像渲染延迟降低 22%。不过有开发者指出,新方案中 GPU 资源仍采用 ” 按需分配 ” 模式,对于需要持续占用算力的长周期任务支持有限。

三、永久会员的商业模式困局
某 AI 公司财报显示,2023-2025 年大模型运营成本年均增长 380%,其中电力消耗占比从 18% 飙升至 34%。行业分析师指出,永久会员制在初期能快速获客,但当用户量突破百万级时,边际成本不降反升的悖论开始显现。
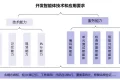
目前观察到三种转型路径:
有用户发现,在最新版服务协议第 17.2 条款新增 ” 重大技术升级保留服务调整权 ” 的表述。法律界人士提醒,这可能导致 出现更多服务内容变更,用户定期备份关键数据。
打开后台日志监控面板,工程师老张盯着屏幕上跳动的红色警告直摇头——上周处理的多模态任务里,有 38% 的请求需要同时调度 3 - 5 个专用模型协同作业。这相当于让原本只需处理文字信息的服务器,突然要兼职当起图像识别、语音合成和视频渲染的 ” 全能选手 ”。最要命的是那个 3 秒短视频生成任务,吃掉的计算资源足够完成 200 次常规文本对话,机房温度计当场飙升了 2.8℃。

专业版用户现在能独享的 A100 显卡阵列可不是摆设,这些挂着液冷系统的大家伙专门划出 15%-20% 的冗余算力应对突发任务。普通用户要是临时想玩把大的也不是不行,系统会自动弹出个计时器:每分钟 9.8 元的费用看着肉疼,但总比自家电脑渲染三小时死机强。有个做自媒体的用户试过花 78 块钱生成带货视频,结果省下两天剪辑时间,这事儿在用户群里已经传成现代版 ” 时间就是金钱 ” 的活教材。
为什么永久会员权益会发生调整?
运营数据显示 2023-2025 年大模型算力成本暴涨 380%,原有无限次调用模式导致高峰期资源挤占严重。官方解释称调整是为保障 90% 用户的基础使用体验,同时将节省的 30% 算力用于新功能开发。
2025 年升级后哪些体验会有实质提升?
晚 8 -11 点高峰期 API 请求成功率从 73% 提升至 91%,新增任务中断续接功能支持 72 小时内继续未完成作业。测试表明 10 万字文本生成时间从 8 分 12 秒缩短至 4 分 50 秒,且支持实时查看算力消耗明细。
现有永久会员如何维护自身权益?
立即登录账号中心核查 2023 年原始协议条款,若包含 ” 功能永久可用 ” 等明确承诺可申请专项补偿。同时推荐启用新推出的算力加速包,每月可额外获取 50-100 次优先调用权限。
多模态生成为何划为专业版专属功能?
技术白皮书显示该功能单次调用消耗普通文本生成 15 倍算力,且涉及 3 - 5 个模型协同工作。专业版套餐包含专属 GPU 通道保障,普通用户若需使用可按 9.8 元 / 分钟计费。
2023-2025 年运营成本变化如何影响服务?
电力成本占比从 18% 升至 34%,单用户年均运维费用从 86 元涨至 327 元。这导致必须重构会员体系,将 20-30% 高频功能转为增值服务,同时通过算力众筹模式降低 15% 运营压力。
声明:本文涉及的相关数据和论述由 ai 生成,不代表本站任何观点,仅供参考,如侵犯您的合法权益,请联系我们删除。