
共计 1810 个字符,预计需要花费 5 分钟才能阅读完成。
近期,科技圈内频频讨论一款迅速走红的 AI 产品——OpenClaw,这款被称为“数字员工”的 AI 工具,声称能够实现真正的“动手能力”,在全球开发者社区引发了巨大反响。朋友圈和技术讨论群中充斥着“贾维斯时代降临”“个人 AI 助理的革命”等热议,令人感到无比兴奋。

作为一名常与 AI 产品博弈的产品经理,最初我对 OpenClaw 感到震撼。让 AI 直接执行任务的想法,确实具有划时代的意义。然而,当我高兴地花费不菲的资金配置设备进行实际体验时,现实的冷水却迅速浇灭了我的热情——在这光鲜亮丽的表象之下,隐藏着两个核心问题,许多人对此视而不见:高昂的 API 费用和极高的训练门槛。
OpenClaw 的角色定位相当明确——它并不是一种云端聊天机器人,而是一个运行于个人计算机的开源 AI 代理,强调“本地优先”的理念。它提供了一个网关,将你日常使用的聊天工具整合为一个统一的入口;同时具备智能体功能,能够调度大型模型进行决策;此外,还有技能库来执行具体操作;并设有记忆模块,记录你的习惯和历史任务。当你在外发送消息时,它能够在家中的电脑上完成邮件整理、报告生成等任务,整个过程在本地进行,数据始终掌握在你手中,保障隐私与控制权。
其名称也经历了几次变迁。从最初的 Clawdbot 到 Moltbot,最终演变为 OpenClaw,这不仅反映了商标的争议,也是其从依赖特定模型到寻求成为通用平台的身份转变。
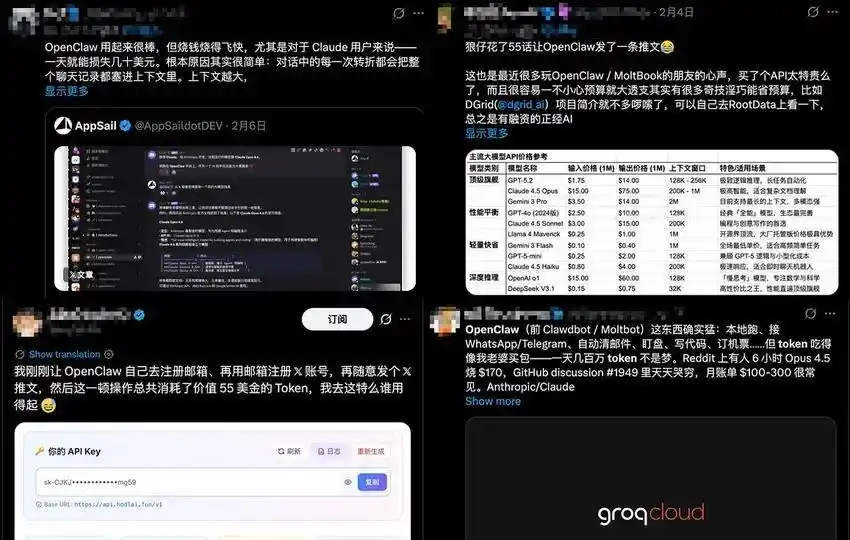
随着用户的需求变化,OpenClaw 从火热走向了让人“肉疼”的阶段,社区的情绪波动显而易见。最初,大家沉迷于分享各种引人注目的 Demo——如自动登录、文件整理和游戏——并未太关注成本问题。然而,当第一批用户在实际工作中依赖于它时,他们发现任务背后惊人的 token 消耗。一晚上完成几个任务,轻松就可能消耗数美元,而高端模型的一次复杂任务便可能需要数十万 token,账单随之暴涨,“这条龙虾太能吃了”成为用户们的共识。
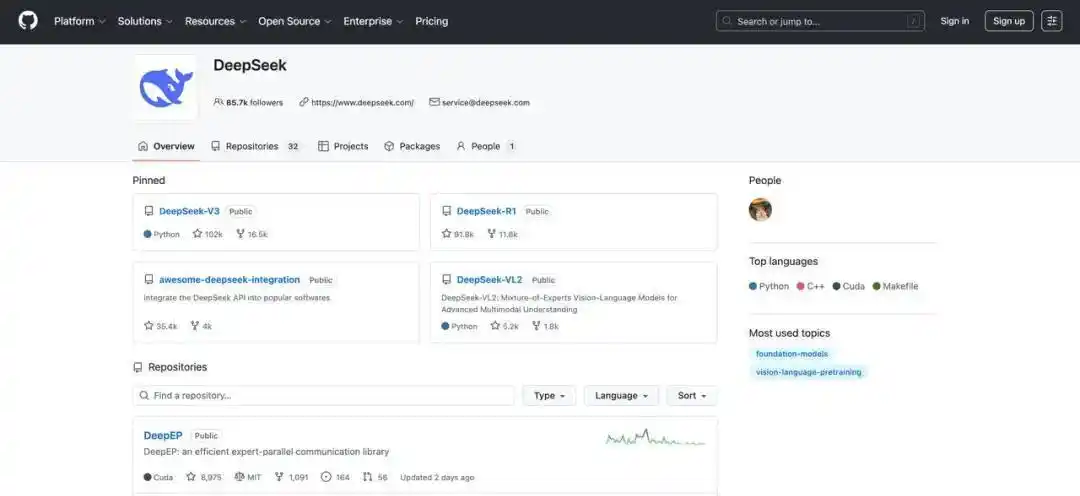
更深层次的问题在于,OpenClaw 并非开箱即用。若想让其在专业软件中表现出色,必须记录大量成功的操作轨迹,并利用监督微调(SFT)对其进行训练,仿佛是在教授实习生如何使用公司系统。这不仅需要技术能力和耐心,还需海量数据,时间成本之高让大多数普通用户望而却步。因此,社区的讨论焦点逐渐转向了“如何降低成本”和“如何进行微调”,有人通过模型分级调用来节省开支,还有人编写脚本来压缩上下文以降低费用,但这些措施仅能缓解问题,无法根本改变现状。
从产品经理的角度来看,它的真正价值在于执行能力——使 AI 从“军师”转变为能够出击的“将军”,直接将指令转化为行动。然而,这种能力伴随着明显的经济成本(token 消耗失控)和隐性的时间成本(个性化训练),使得在当前阶段,它更适合极客和专业领域的专家,而不是普通用户。

尽管 OpenClaw 的技能生态 ClawHub 蓬勃发展,但每一项技能同样面临调用成本和训练挑战,其护城河的稳固性将取决于能否将使用成本降低到普通人所能接受的水平。在风险排序中,经济风险位居首位,账单劝退率高;其次是安全风险,系统权限过高若被恶意利用可能导致严重后果;最后是投资回报风险——训练成果可能因为底层模型更新或软件改版而迅速贬值。
OpenClaw 的迅速崛起同时也暴露了产业面临的挑战:成本门槛迫使行业寻求降本方案,如混合模型策略、端侧轻量模型、本地决策与云端辅助相结合;个性化训练门槛催生了新的训练数据市场,未来或许会出现操作轨迹数据交易平台或预训练代理服务,让用户可以直接购买针对特定软件的成熟技能包。
OpenClaw 如同一盏明亮的探照灯,既照亮了 AI 自主执行的未来,也显露出成本与训练的双重挑战。它促使行业从单纯的能力幻想回归到计算成本与效率的现实,激发思考——如何让 AI 代理既能够负担得起,又容易上手。真正的革命并非技术惊艳的瞬间,而是技术、商业与体验之间找到微妙的平衡并实现普及的过程。当成本低至大众可接受,而易用性高到每个人都能掌握时,它才将真正成为一种生产力工具。如今,竞争已然拉开帷幕。





听说OpenClaw的模式需要大量数据,普通用户要是想用好,真得做好准备。