
共计 3647 个字符,预计需要花费 10 分钟才能阅读完成。
近期,随着 OpenAI、谷歌、DeepSeek、阿里巴巴、腾讯及智谱等企业在大型模型领域的激烈竞争,众多 AI 开发者和用户仍在探索智能体与技能的应用之际,一款名为 OpenClaw 的 AI 助手意外崭露头角,并迅速赢得了广泛关注。OpenClaw 瞬间跻身历史上增长速度最快的开源项目之一。那么,OpenClaw 究竟是什么呢?它最适合搭配哪些硬件呢?
OpenClaw 的定义

简单来说,OpenClaw 是一款可以在本地或自主托管环境中运行的开源 AI 助手。作为一个自主智能体,它能够利用大型模型来执行各种任务,主要通过社交聊天平台与用户进行交互。OpenClaw 可以在 macOS、Windows 或 Linux 系统上部署,用户可以通过 WhatsApp、Telegram、Slack、Discord、iMessage、Signal 和飞书等社交工具与其进行对话。
除了具备与大型模型类似的问答能力,OpenClaw 还能执行 Shell 指令、控制浏览器、读取或写入文件、管理日程,甚至发送电子邮件和启动特定应用程序,这些操作均可通过用户与 OpenClaw 之间的文字交流触发。

综上所述,若在部署 OpenClaw 的设备上赋予其足够权限,它便能够在用户指挥下,犹如人类般操控计算机。因此,OpenClaw 被称为真正的“贾维斯”。正因如此,OpenClaw 团队在用户进行部署时,会弹出安全风险提示。许多开发者也建议用户在备用 PC 上体验 OpenClaw,并始终关注安全问题。
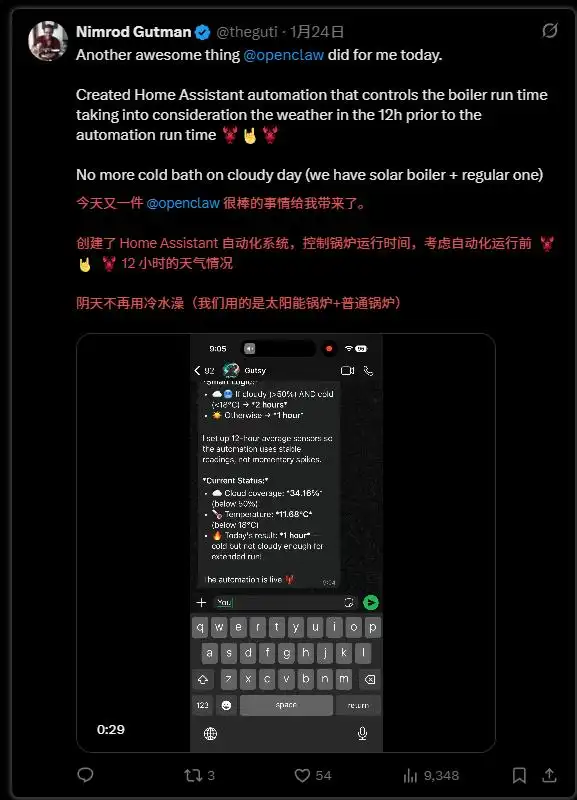
有用户将 OpenClaw 与实际生活场景相结合,直接让其控制烧水的锅炉,根据天气情况定时加热水,以免冬天没有热水可用。更有甚者,许多人借助 OpenClaw 进行股票交易、撰写自媒体文章和社区管理等工作。一些公司也尝试将 OpenClaw 作为内部“公司助手”,连接各类 SaaS 和数据系统来实现自动化。
部署 OpenClaw 所需的硬件
如果希望体验 OpenClaw,首先需要关注如何选择合适的大型模型服务来与其连接(毕竟 OpenClaw 本身并不是大型模型)。究竟是选择在线云端的大型模型,还是本地部署的大型模型呢?
使用云端大型模型的主要缺点是费用高昂。在这一过程中,用户需要通过 API 接入云端大型模型,OpenAI、谷歌等提供商通常按 Token 数量收费,加之 OpenClaw 的强大功能,自然会消耗大量 Token,输入百万 Token 需花费 5 美元,输出百万 Token 则需 25 美元。如果是企业客户,Token 的费用可能会高得惊人,初创企业和中小型企业往往难以负担,长期使用本地部署显得尤为重要。

此外,使用云端大型模型还存在隐私和安全的重大隐患。OpenClaw 允许智能体在本地执行 Shell、读写文件或调用脚本,一旦依赖云端大型模型进行“思考”和决策,攻击者可能通过提示词注入或恶意数据,远程诱导大型模型发出指令,使 OpenClaw 在用户的计算机上执行危险操作。
同时,为了使云端大型模型“理解上下文”,OpenClaw 可能会将聊天记录、文件片段甚至密码提示、聊天历史等信息打包发送给外部模型服务。一旦这些信息进入云端,就会受到对方隐私政策、日志政策和潜在数据滥用风险的制约。设想一下,作为公司老板的你,是否愿意将企业的核心数据暴露出去呢?
而且,接入云端大型模型势必会带来网络延迟和服务稳定性的问题,智能体在执行某些操作时,因网络波动或 API 限流可能会中断,导致操作未完成或“中途停手”的异常情况。由于大型模型输出存在随机性和不可预见性,同样的提示词和环境可能会产生不同的操作路径,因网络问题导致的中断在“系统级自动化”场景下意味着难以复现和回归测试,这对企业用户而言是得不偿失的。
OpenClaw 的理想硬件搭档:AMD 锐龙 AI Max+ 395 平台
与接入云端大型模型相比,对于企业用户而言,接入本地大型模型才是最佳选择。这实际上是将 OpenClaw 从“云端大号遥控器”转变为“自家机房的 AI 中枢”。这样的做法在隐私、安全、成本、可控性和场景适配上都有显著优势。
具体而言,在隐私和合规性方面,当 OpenClaw 与 Ollama、LM Studio 等在本地通过 GPU 运行模型时,整个推理过程(包括理解指令、读取文件和生成结果)均在本机完成,提示词、文档及中间结果都不会发送至云端 API,这对于处理财务报表、法律文书和客户数据等敏感信息尤为重要。
第二个优势在于成本结构更具可控性。采用本地模型替代云端模型后,整个智能体的链路不再因每次调用而需支付双向 API 费用,只需一次性硬件投资便能实现高频自动化任务,无需再“烧 Token”和“烧钱”。毕竟在本地部署各种开源大型模型后接入 OpenClaw,Token 数量几乎是无限且免费的。正如 OpenClaw 创始人所说的 Minimax 模型,也可以通过两台搭载锐龙 AI Max+ 395 的迷你 AI 工作站串联运行(某些设备支持一键启动组件集群),相比于顶配的 Mac Studio,这两台搭载锐龙 AI Max+ 395 的设备购买成本更低且更为可行。
此外,接入本地模型的另一大优势是支持离线使用,即 OpenClaw 的所有智能决策与工具调用均可完全独立于网络环境进行操作。对于在工厂、机房、科室或实验室等“封闭网络”中部署 OpenClaw 的机构而言,本地模型可能是唯一可行的方案,这样可以在内网环境中实现日志分析、控制脚本执行等自动化任务。

AMD 锐龙 AI Max+ 395 处理器表现出色,该处理器采用“CPU+IGPU+NPU”异构架构,集成了 16 个核心的 Zen 5 CPU、RDNA 3.5 图形单元以及高达 50 TOPS 的 NPU 算力,并通过 UMA 统一内存架构支持最高 128GB 内存,其中 96GB 可专用于显存。这有效解决了本地大型模型运行中的“显存焦虑”,使其能够在本地顺畅运行千亿参数规模的模型。
自发布以来,AMD 锐龙 AI Max+ 395 处理器凭借卓越的性能和出色的大型模型部署能力,开创了全新的迷你 AI 工作站细分市场。更重要的是,目前基于该处理器的迷你 AI 工作站产品已进入各行各业,为用户提供了前沿的 AI 体验。
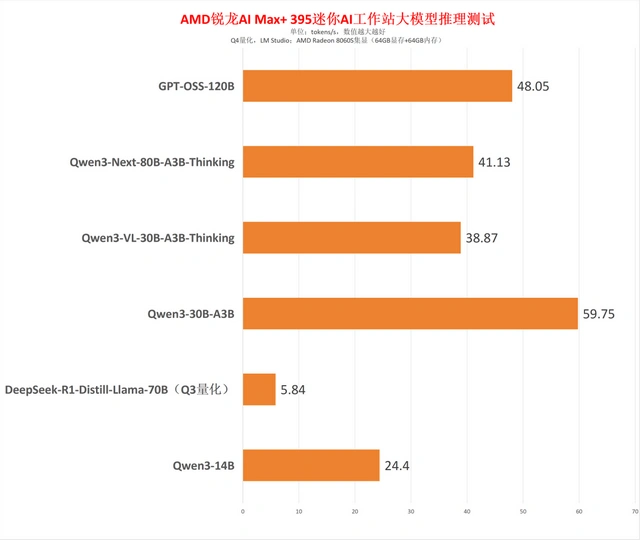
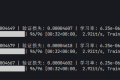
值得一提的是,AMD 锐龙 AI Max+ 395 迷你 AI 工作站非常适合用于本地大型模型的部署。根据以往测试结果,该平台能够流畅运行 70B 稠密大型模型(推理速度达到 5.84 tokens/s),而对于 120B 的 MoE 大模型,其推理速度更是高达 48.05 tokens/s,应对 80B、30B 等主流 MoE 模型几乎毫无压力。
探索高效部署大模型的新选择
AMD 锐龙 AI Max+ 395 平台以其对 128GB 内存的全面支持和高达 96GB 的显存分配能力,为大模型的部署提供了充足的硬件资源。在 64GB 显存的配置下,我们成功尝试了同时运行三个大型模型:包含两个 30B MoE 模型和一个 14B 稠密模型。结果显示,系统仅消耗了约 50GB 显存,剩余的硬件资源仍显得相当充裕。
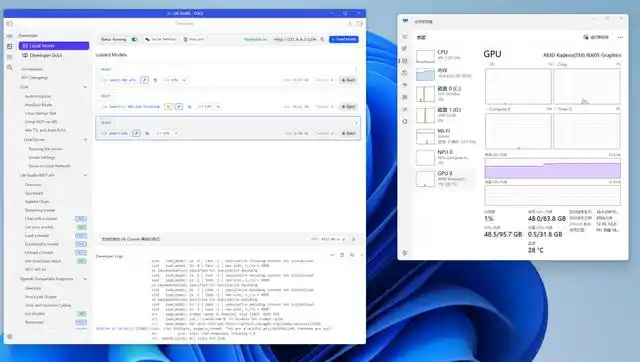
对于 OpenClaw 的用户而言,将其与 AMD 锐龙 AI Max+ 395 平台结合使用后,可以在操作过程中实现多模型的同时调用,或者灵活切换所需的各类大型模型。而如果选择其他基于 Windows 11 的独立显卡平台,情况就大相径庭了。以 RTX 5090 为例,其显存仅有 32GB,根本无法满足大型模型的部署需求,即使勉强实现,也会由于硬件资源紧张而频繁加载和卸载,效率自然难以提升。
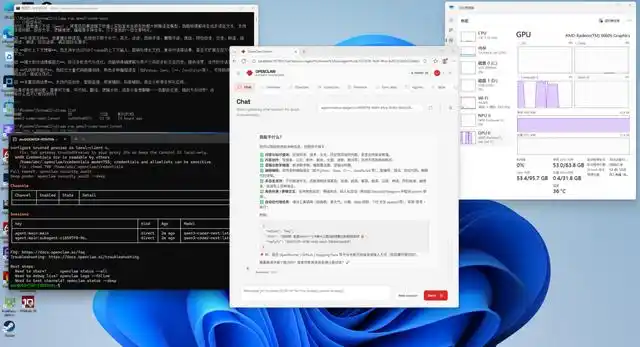
我们之前在搭载锐龙 AI Max+ 395 的设备上成功部署了 OpenClaw,并同时进行了 Qwen3-Coder-Next 模型的本地化部署。由于模型在本地运行,使用 OpenClaw 时无需担忧 Token 使用费用的问题。
进一步的应用场景是,将 AMD 锐龙 AI Max+ 395 迷你工作站视作本地大模型的 API 中心,其他局域网设备可以部署 OpenClaw 并远程调用该工作站提供的模型。这一方案对于初创企业和中小型公司而言,更加切合实际,能够提高工作效率。
结论
总体来看,OpenClaw 展现出了独特的魅力与强大的功能,标志着人工智能领域的又一次飞跃。普通用户能够迅速体验到这一新一代 AI 助手的吸引力。而对于企业用户、AI 开发者以及 AI 爱好者来说,接入本地模型不仅能在隐私保护和 Token 成本上获得保障,还可以消除网络延迟,实现多个大型模型的本地同步调用,甚至通过多台设备的协同来增强部署能力。毫无疑问,AMD 锐龙 AI Max+ 395 迷你工作站是当前市场上最佳的本地大模型部署平台,凭借其宽裕的硬件空间,能够高效运行超大参数模型,成为本地 AI 算力的核心。OpenClaw 与 AMD 锐龙 AI Max+ 395 的结合,无疑是一个理想的选择,值得大家关注并加快本地 AI 的部署进程。






我对OpenClaw的安全风险有些担心,特别是涉及到云端模型时,隐私保护怎么保障呢?