共计 3757 个字符,预计需要花费 10 分钟才能阅读完成。

在人工智能快速发展的今天,模型的处理能力不断提升,特别是在长文本解析、多模态理解和复杂推理等领域的突破。无论是负责算法开发的工程师,还是产品经理,评估大模型的各项能力已成为 AI 行业的日常工作之一。本期将介绍如何在 20 分钟内,使用文心快码和只需 5 句话构建一个 MBTI 性格测试器,即便是零基础也能轻松上手。
一、需求分析背景
为何要为大模型设计 MBTI 性格测试?在社交网络上,MBTI 被视为人们自我标识的工具,能够在一定程度上反应个体的性格特质、价值观、交流风格及社交态度。既然大模型具备模拟人类思维的能力,那么它是否也会拥有 MBTI 性格特征呢?在职业发展和人际交往等诸多场合中,人们经常参考 MBTI,同样地,对 AI 模型进行 MBTI 性格测试也可以作为一种启发式工具,帮助分析、比较和预测模型的行为模式、倾向以及潜在的局限性。
对算法工程师和产品经理而言,了解大模型的 MBTI 特性有助于改善 人机交互体验、选择合适的模型以匹配任务、揭示模型的内在偏好与偏见,并为模型的开发和调优提供指导。而对于与 AI 进行互动的用户来说,给模型贴上“MBTI 标签”能够快速了解它的“脾气”——即知道它在什么类型的任务中表现更佳,怎样与之交流更加高效。因此,为大模型进行 MBTI 性格测试不仅富有趣味性,也具有实用价值。
参加过 MBTI 测试的朋友都了解,测试一共包含 93 个问题,完成全套测试大约需要 30 分钟。如果采用人工方式进行测试,用户需在客户端或网页上与大模型逐个提出问题,记录每个答案,这样一来,时间成本就会显著提高。然而,需要注意的是,在实际应用中,进行 MBTI 性格测试时,不可能只对一个模型进行测试,也不可能只测试一次。当需要测试多个模型,且为了确保模型表现的稳定性而进行多次测试时,人工测试的效率显得极为低下。即使最终得到测试结果,为了清晰比较不同模型的差异和观察稳定性,仍需耗费时间整理测评报告。整个流程繁琐复杂,难免让人感到沮丧。总体来看,人工测试主要存在以下问题:
场景设计耗时:构思有效的测试用例既耗时又费力;
样本生成低效:手动构建或生成高质量输入 / 输出样本的效率低下;
执行繁琐易错:手动调用不同模型的 API、进行多轮测试并记录结果,极易出错且难以实现规模化;
报告缺乏洞察:难以直观比较模型之间的差异,也难以发现稳定性问题。
幸运的是,我们可以借助文心快码这一编程工具,轻松编写自动化脚本。接下来将详细介绍具体的操作步骤。
二、清晰表达你的需求给 Zulu
文心快码的强大之处在于:它不仅可以生成代码,还能根据需求自动补充场景设计、分解任务,并输出可直接运行的结果。要最大化利用其功能,关键是准确描述需求。在表达需求时,建议详细说明背景、目标、交付标准和执行步骤,以便文心快码能够真正理解我们的意图,准确执行任务。以下是一个示例:
可以提前准备一个文档,包含模型名称、域名、API 密钥,明确告诉文心快码需要测试的模型,并指明要调用的 API,同时提供相应的 MBTI 测试题目。接着提出测试要求,表明需要进行 5 次测试以观察稳定性。此后,告知交付标准,最后提供初步的行动指引:首先让它编写一个项目设计文档,以便了解其思路;然后进行单模型测试以验证项目的可运行性,这样在试错成本更低的情况下为后续全量测试做好准备。
三、观察执行过程
将你的提示输入到文心快码 Zulu 对话框中后,Zulu 便会开始执行任务。在此过程中,我们只需关注它的操作:
第一步:编写项目设计文档 design.md,内容包括系统架构、核心模块设计、数据流和测试计划等部分。
第二步:开发核心测试模块。
第三步:开发报告生成模块。
第四步:开发主程序模块。
第五步:进行单模型测试,确认逻辑和输出是否正确。
在这个过程中,我们可以看到Zulu 能够自动调用相关工具,复用相同的终端,协助完成环境搭建和服务启动,整个过程无需我们操心。
【依赖自动安装】Zulu 自动识别项目中的依赖配置文件,并生成干净的虚拟环境,安装所有所需的依赖。
【服务自启动】Zulu 能够智能识别项目的启动命令,自动运行它,使开发环境的启动变得极为简单。
【错误自修复】如果在环境搭建或服务启动过程中出现问题,Zulu 会主动检测错误并提供修复建议。例如,当缺少某个依赖时,它会自动尝试安装,甚至直接解决问题。
例如 :在运行测试时,若终端报错:ModuleNotFoundError: No module named ‘toml’。Zulu 会立即捕捉到这个异常, 自动执行 pip install toml 命令来修复缺失的依赖,无需用户手动干预,随后继续执行后续任务。
项目初步完成后,Zulu 将提供清晰的项目使用说明和总结。
四、不断优化工作流程
Zulu 为我们开发的自动化脚本基本上已经完成了。但若整个过程是个“黑盒”,难免会引发疑虑:模型是否完成了所有测试?三次测试是否都已完成?如何应对呢?可以添加一个调试需求,以便实时观察模型的输入,使测试过程更加透明。
Zulu 可以根据当前的上下文,在原有代码库中精准定位并进行修改。即使不懂代码、不清楚如何修改,只需输入需求,Zulu 凭借其强大的理解能力,结合现有代码库,迅速找到需要修改的地方。而且,修改过程完全透明:删除的代码以红色标示,新增的代码以绿色标示。
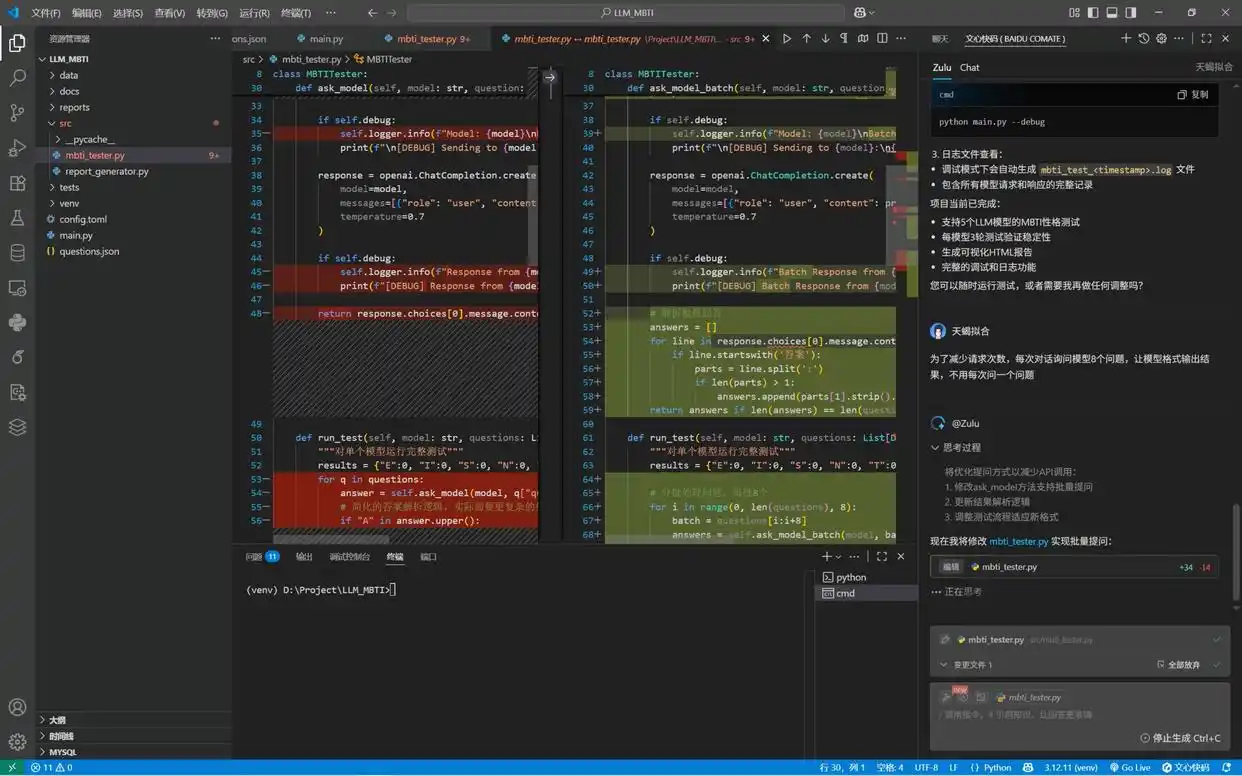
通过 Zulu 优化 MBTI 模型测试流程的全面指南
在工作中,直接输入需求:“希望确认每次请求模型时,输入内容是否符合预期。因此,请增加一个调试模式,让我能够查看模型的输入,最好能将其记录到日志文件中。”这样做不仅能验证调用是否如预期,还便于后续问题的追踪。经过 Zulu 的修改后,调试模式下的执行命令也被提供出来以供测试。
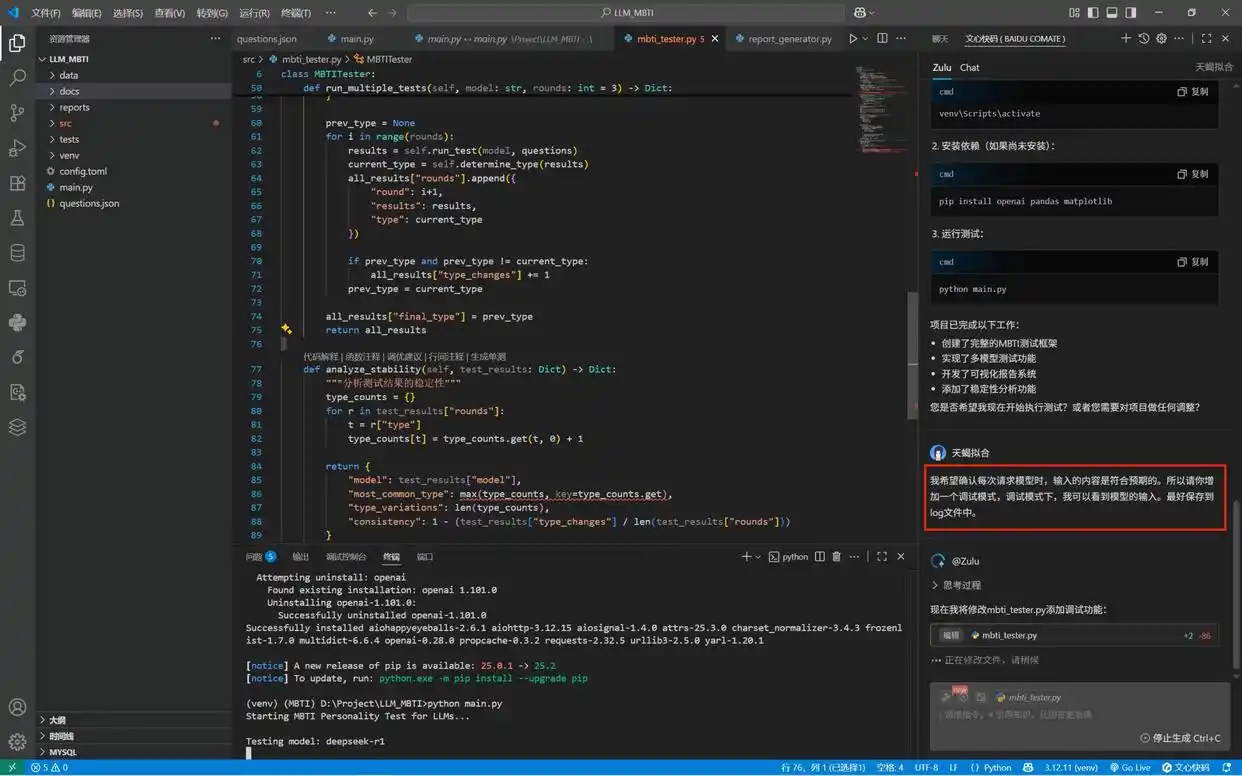
实际上,在整个项目中,Zulu 的应用能够持续优化我们的工作效率。
1. 提升效率
在实际测试中,我们意识到逐一测试问题的效率太低,因而我们命令 Zulu:“为了减少请求次数,每次对话询问模型 8 个问题,以便模型能够批量输出结果。”Zulu 迅速理解了我们的意图,调整了主程序逻辑,将串行请求转换为批量处理,这大幅提升了测试的速度。
2. 自动生成报告
在单个模型的 MBTI 测试基本没有问题的情况下,我们可以指示 Zulu 生成综合报告:“请将 reports 目录下所有单个模型的测试结果整理成一份综合报告。”
3. 性能进一步优化
如果测试速度依然是个问题,我们可以提出更高的要求:“请改用多线程异步并行请求来测试模型,以便加快测试速度。”在这种情况下,Zulu 会重构代码,从而极大缩短测试耗时。
完成 Zulu 的调整后,项目基本就绪。我们可以在终端中输入调试模型的运行指令“python main.py –debug”,开始测试并生成报告。在调试模式下,测试过程将清晰可见。
五、通过预览调试功能完善报告
到此为止,测试报告已经生成,在 reports 目录下可以找到综合报告以及每个模型的历史测试报告。通过预览网页可以验收成果,若发现问题,仍可进行修改。
如果使用文心快码插件,Zulu 的多模态能力也能协助修改。Zulu 支持上传图片,并根据指令识别图片内容或将其转化为代码。可以截取有问题的界面并上传到对话框,再输入修改需求。如果使用的是 Comate AI IDE,则可利用预览调试功能进行修改。只需在 IDE 的左侧边栏点击预览按钮,打开预览调试界面,圈选问题位置,然后在 Zulu 对话框输入修改需求,就能完成修改。
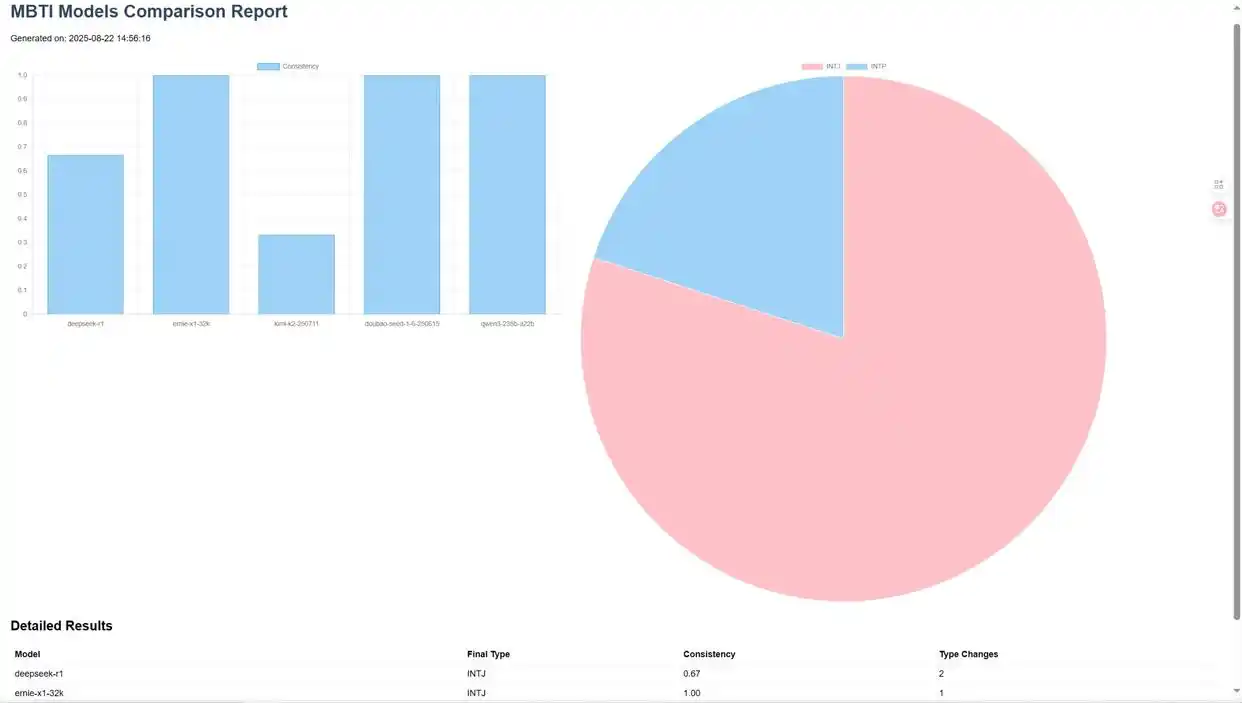
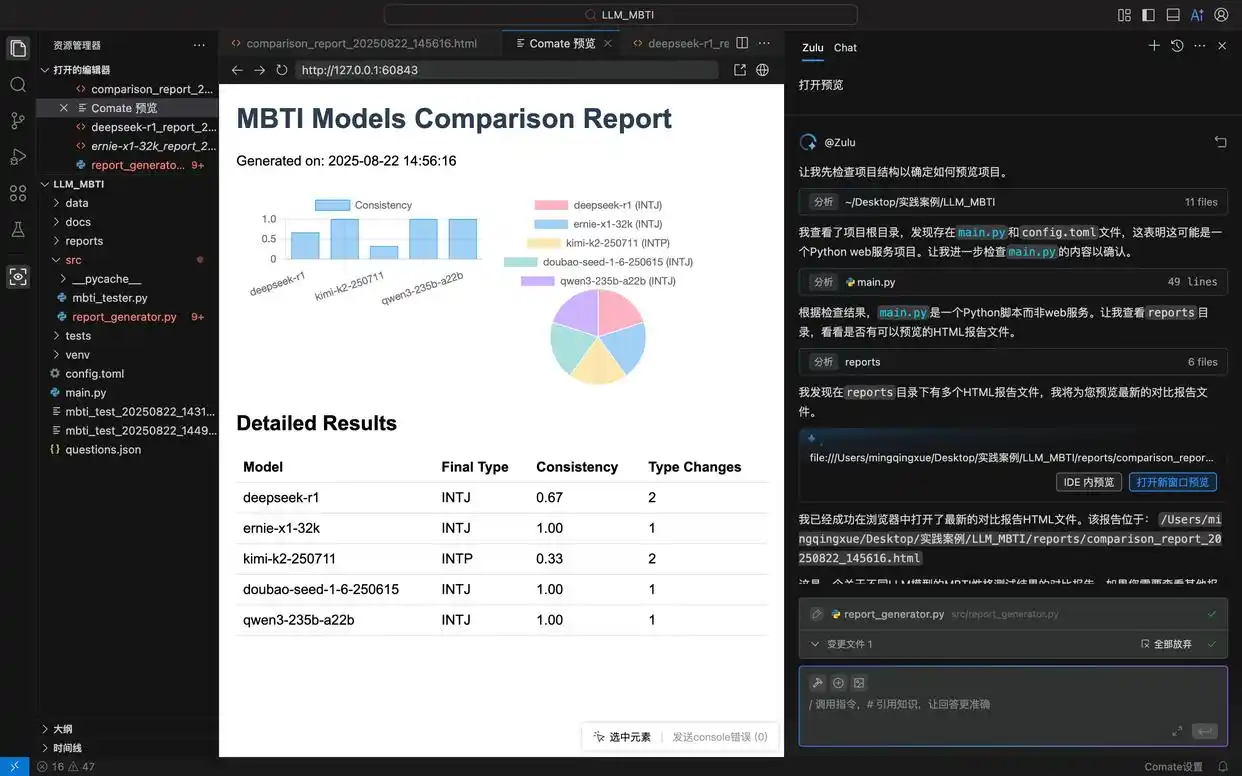
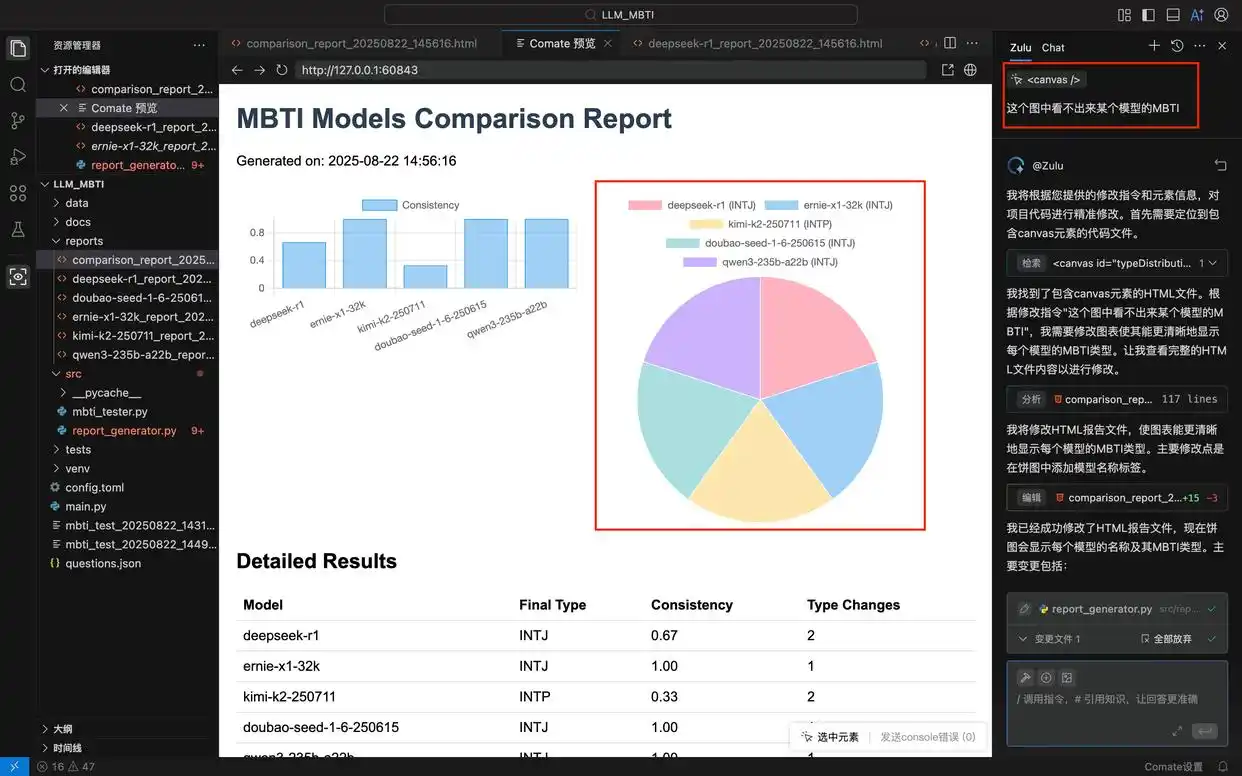
在这个项目中,我希望 报告中的饼图能够展示每个模型的 MBTI 类型,因此在 Comate AI IDE 中选中这个组件,输入调整需求,Zulu 便对报告的 html 文件进行了针对性修改,刷新预览窗口后,便能看到最新的报告样式。
六、展示我们的成果
最后,我们利用 Zulu 的代码解读功能介绍我们的项目成果:我们实现了一个用于测试不同 LLM 模型 MBTI 性格类型的 Python 项目,主要功能包括:
1. 核心测试功能:
-
使用标准 MBTI 测试题目评估 LLM 模型
-
支持批量测试多个模型
-
异步执行提高测试效率
-
多轮测试评估结果的稳定性
2. 报告系统:
-
生成每个模型的详细 HTML 报告
-
创建多模型对比报告
-
包含可视化图表展示测试结果
-
记录历史测试数据
3. 技术特点:
-
基于 Python 3.12 开发
-
使用 aiohttp 等异步库
-
集成 Chart.js 进行数据可视化
-
完善的日志记录系统
4. 测试结果示例:
-
对五种主流的 LLM 模型进行了评测
-
大部分模型表现出 INTJ 性格特征
-
不同模型的测试结果稳定性各异
从构想到实现,仅用 5 句话,耗时不足 30 分钟,在文心快码的支持下,我们成功开发出一个大模型 MBTI 测试器,旨在实现模型的自动化评估。以往需要几位同事共同协作、耗时数天才能完成的任务,现在一个人就能轻松搞定。尽管这个项目的代码量不小,但即使没有编程基础的人也能顺利完成开发。AI 编程工具现已不再是专业程序员的专属利器,而是提升日常工作效率的得力助手,帮助简化繁琐的流程,使得我们能将时间和精力投入到更具价值的方案设计和战略规划上。