
共计 1577 个字符,预计需要花费 4 分钟才能阅读完成。
我有一个疑问:为什么国内的 AI 大模型自称技术领先,但在实际编程过程中,程序员却多数选择使用 GPT、Gemini 等国外模型,而非国内的方案?
首先,我们需要讨论 AI 编程模型的能力以及评估方法的相关问题。当前主要面临三个挑战:
1. 随着模型能力的提升,评估其性能的方式也变得愈加复杂。现阶段,大部分国内外模型在进行简单的对话互动、产品展示以及数据分析脚本编写方面表现都相当出色,这使得这些任务之间的差异不明显。然而,当涉及到复杂项目及棘手的 bug 处理时,差距便显现出来。
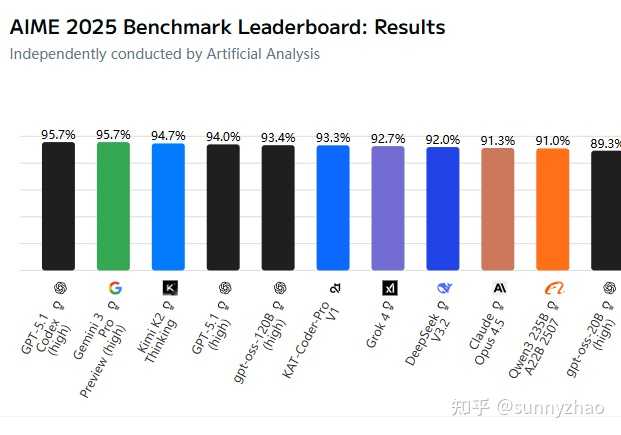
2. 在基准测试方面,性能评估已经出现饱和现象。例如,MMLU 测试在达到一定水平后,其升级版 MMLU-Pro 中大多数模型的得分均超过了 80,而在 AIME2025 的榜单上,有十个模型的得分超过 90 分。因此,单凭某一基准测试的分数,因其饱和性,无法有效比较出模型之间的真实差异。
3. 测评环境与实际应用场景之间的差异,尤其是在代码生成领域。模型的训练数据通常源自开源代码的问题或拉取请求,这些问题往往是局部的或片段化的,而不像真实场景中所面临的复杂性与整体性。此外,当前强化学习的训练成本较高,针对真实问题的训练复现方法尚未成熟,加之上下文和记忆管理的方案仍不完善,因此,模型在解决复杂编程问题时的能力显得相对薄弱。
在以上问题的背景下,我们可以从两个方面分析为何国产模型在实际应用中不如国外模型受到青睐。
首先,根本原因在于模型能力的差距。在评估编程能力的标准中,swe-bench verified 是针对处理真实 GitHub 问题的评估工具,这是评价模型编程能力的关键基准测试(尽管其样本仅有 500 个经过人工验证,说明评估的覆盖度确实不足)。目前得分最高的是 claude opus 4.5(80.9),接下来的排名依次是 claude-sonnet-45(77.2)、gpt-5..1(76.3)和 gemini-3-pro(76.2)。而国内模型中表现最佳的是 DeepSeek-v3.2,得分为 73.1,其余模型的排名依次是 kimi-k2 thinking(71.3)、qwen3-max(69.6)、minimax-m2(69.4)和 glm-4.6(68.0)。由此可见,国内模型与国外 75 分以上的模型之间仍存在显著差距。
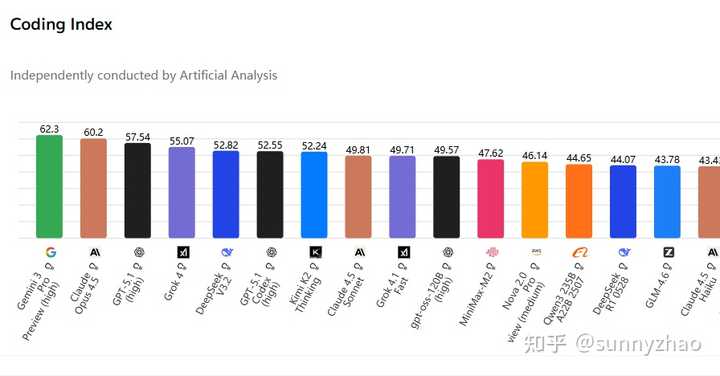
再来看看综合性的测评,如 scicode(科学编程)、livecodebench(较新的竞赛编程)和 terminal-bench-hard(终端复杂问题编程)的编码指数评分,前四名均为国外模型(得分均在 55 以上),DeepSeek-v3.2(52.82)位列第四,算是开源领域的一点成绩,尚超越了 gpt-5.1-codex(高)。因此,通过这些与真实编程任务相关的测评结果,可以直观地判断各模型的能力差异。
第二个问题则是基于编程代理的技术栈及生态的差距。claude 和 codex 早期便开始构建基于自家模型的命令行编程工具,而国内的 qoder、atra 和 codebuddy 等则是在最近三个月内发布的。由于在编程场景中的经验积累、产品优化以及领域内强化学习的进展,国内模型在这些方面面临一定的后发劣势,需要持续努力追赶。
总体来看,尽管大部分模型在处理简单编程任务时表现良好,但即使是最先进的模型目前也尚未能达到应对复杂编程问题的水平。而国内模型的编程能力与国外顶尖模型之间的差距虽然仍在,但这一差距正逐步缩小。








这数据一看,国产模型的自信可能是不少程序员心里的隐忧啊。