
共计 6269 个字符,预计需要花费 16 分钟才能阅读完成。
编程范式概述
编程范式,也被称为编程风格或程式设计法(Programming paradigm),是软件开发中一种典型的编程风格。常见的编程类型包括函数式编程、命令式编程、声明式编程以及面向对象编程等。这些范式对开发者理解程序的执行过程起着重要的指导作用。在利用 AI 框架进行编程时,开发者通常会涉及两种主要的编程范式:1)声明式编程和 2)命令式编程。

本节将深入探讨这两种编程范式对 AI 框架整体架构设计的影响,并分析当前主流 AI 框架在不同编程范式之间的区别。
程序开发中的编程范式
-
命令式编程(Imperative):通过具体的命令指导计算机如何(How)完成任务,以达到预期的结果。
-
声明式编程(Declarative):仅需表明期望的结果(What),执行过程(How)则由计算机自行处理。
编程与编程范式的关系
编程是开发者为计算机编写程序的过程,旨在通过代码解决特定问题。它涉及制定一定的运算规则,使得计算机能够依照这些规则执行并产生所需的结果。
为了使计算机理解人类意图,开发者需要将解决问题的方法、思路用计算机可识别的形式传达给计算机,从而使其能够按照指示逐步完成特定任务。这种人与计算机之间的沟通过程被称为编程。
命令式编程的特点
命令式编程(Imperative programming)是一种定义计算机行为的编程模型,几乎所有计算机硬件的运行方式都是基于命令式的。
其操作过程可以划分为几个步骤:首先,需要将解决方案提炼成一系列抽象的步骤。接着,通过编程将这些步骤转化为程序指令(算法),这些指令按照特定顺序排列,用以阐述如何完成任务或解决问题。这要求开发者明确程序应当实现的目标,并告知计算机如何进行所需的计算,包括每一个细节的操作。简单来说,即是将计算机视为一个始终遵循指令的执行者。
因此,在命令式编程中,规范化并抽象出待解决的问题为某种算法是至关重要的步骤,随后才是编写具体算法并实现正确解决方案的工作。
目前,开发者在命令式编程中主要处理硬件控制和指令执行。AI 框架中的 PyTorch 主要采用命令式编程的方式。
以下代码演示了一个简单的声明式编程过程:创建一个名为 results 的集合变量,用于存储结果,并遍历数字集合 collection,判断每个数字是否大于 5,若是,则将其添加至结果集合 results 中。这个过程需要明确指示计算机每一步的执行方式。
results = []def fun(collection): for num in collection: if num > 5: results.append(num)声明式编程的概念
探索声明式编程与函数式编程的深层内涵
声明式编程(Declarative programming)是一种与命令式编程截然不同的编程理念。它专注于目标的特征,而非具体的执行流程。这种方式让计算机理解所需达成的目标,而无需详细告知其内部操作,因而有效避免了许多潜在副作用。相比之下,命令式编程则必须通过明确的算法逐步指示每一个操作步骤。
副作用在计算机科学中是指函数在被调用时,除了返回结果外,还可能对原有环境产生其他影响,例如更改全局变量、修改参数,或者影响外部存储的信息等。
在声明式编程中,通过函数、推理规则或项重写(term-rewriting)规则来定义变量间的关系。而其语言处理器(如编译器或解释器)则采用固定的算法来从这些关系中推导出结果。
当前,开发人员常用的声明式编程语言包括数据库查询语言(如 SQL、XQuery)、正则表达式、逻辑编程和函数式编程等。在人工智能框架领域,TensorFlow1.X 便是一个典型的声明式编程应用实例。
以 SQL 为例,这种数据库查询语言清晰地展示了声明式编程的特点,用户无需创建变量来存储数据,只需告知计算机查询的目标即可:
>>> SELECT * FROM collection WHERE num > 5深入了解函数式编程
函数式编程(Functional Programming)同样是一种独特的编程范式,旨在避免在软件开发中使用共享状态、可变状态及其带来的副作用。它将计算过程视作函数的运算,强调不使用程序状态和易变对象。从理论上讲,函数式编程属于声明式编程,因为它没有可变的状态,也无需明确执行顺序。
其核心理念是仅使用纯数学函数进行编程,函数的输出完全依赖于输入参数,而不产生任何副作用,如输入输出或状态变更。程序通过函数组合(function composition)构建,应用的状态在不同的纯函数间流动。相较于命令式编程中的面向对象编程,函数式编程更趋向于声明式编程,代码更加简洁明了,具有更高的可预测性和可测试性,因此可以视为声明式编程的一种特殊形式。
函数式编程的一个显著特征是“函数第一”(First Class),这意味着函数可以出现在任何上下文中,例如可以将一个函数作为参数传递给另一个函数,甚至可以作为返回值。以下是一个 Python 代码示例:
def fun_add(a, b, c): return a + b + cdef fun_outer(fun_add, *args, **kwargs): print(fun_add(*args, **kwargs))def fun_innter(*args): return argsif __name__ == '__main__': fun_outer(fun_innter, 1, 2, 3)AI 框架中的编程模式
在当今主流的人工智能框架中,无论是 PyTorch 还是 TensorFlow,均以 Python 为核心的高级语言作为前端,为用户提供脚本化的编程体验。其后端则采用更低层次的编程模型和语言进行开发。后端的高性能可复用模块与前端紧密结合,通过前端驱动后端的方式进行执行。同时,AI 框架为用户提供了声明式(declarative programming)和命令式(imperative programming)两种编程方式供选择。
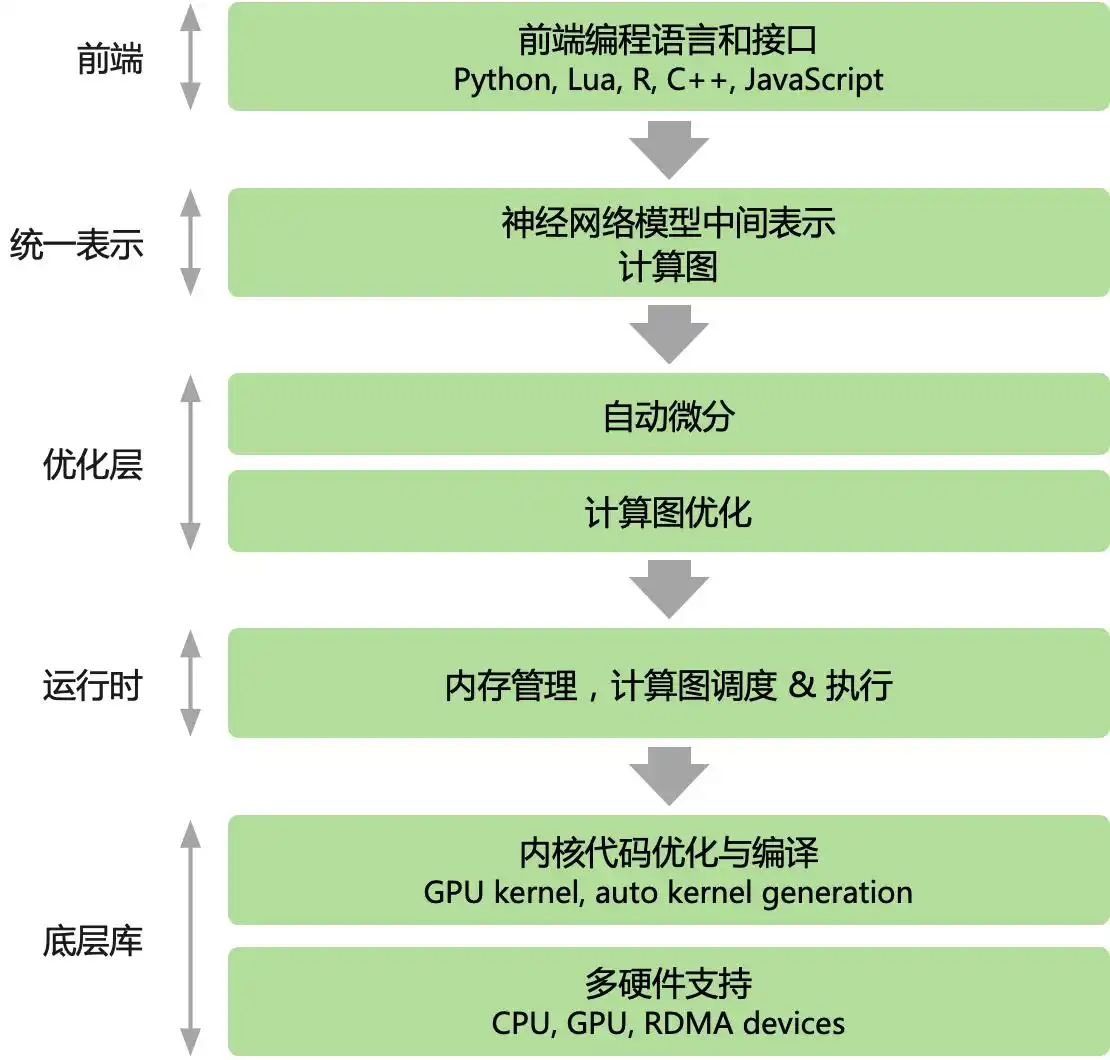
深入探讨 AI 框架中的编程模型
在主流的人工智能框架中,TensorFlow 以声明式编程为用户提供了便利,而 PyTorch 则通过命令式编程提升了开发者的控制力。不过,二者之间的界限并非绝对,multi-stage 编程与即时编译(Just-in-time, JIT)技术的引入,使得这两种编程模型可以有效结合。随着 AI 框架逐渐增加更多的编程模式和功能,例如 TensorFlow 的 Eager 模式以及 PyTorch 的 JIT,主流框架纷纷选择支持混合编程,以实现两者的优势互补。
命令式编程
在命令式编程模型中,用户通过 Python 语言直接控制后端算子的运行,表达式会立即进行求值,这种方式也称为 define-by-run。开发者需要逐层构建神经网络模型,并为每一次训练迭代编写计算任务。在执行程序时,系统会依据 Python 的动态解析特性,逐行解析并执行具体计算,因此被称作 动态计算图(动态图)。
命令式编程具有调试方便和灵活性高的优点,但由于缺少对算法的统一描述,导致在执行前无法进行编译期的优化。
相较于此,命令式编程在数据和控制流的静态性限制方面较为宽松,使得调试变得更加简单,灵活度显著提高。然而,其缺点在于,模型在执行前无法获得完整的计算图描述,从而失去了在编译阶段进行各种优化的机会。
以 PyTorch 为例,其编程特性强调即时执行,属于一种声明式编程风格。接下来,我们将通过 PyTorch 实现一个简单的两层神经网络模型并进行训练:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitimport torchimport torch.nn as nnimport torch.optim as optim# 导入数据 data = pd.read_csv('mnist.csv')X = data.iloc[:, 1:].valuesy = data.iloc[:, 0].values# 分割数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 将数据转换为张量 X_train = torch.tensor(X_train, dtype=torch.float)X_test = torch.tensor(X_test, dtype=torch.float)y_train = torch.tensor(y_train, dtype=torch.long)y_test = torch.tensor(y_test, dtype=torch.long)# 定义模型 class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.fc1(x) x = self.fc2(x) return xmodel = Net()# 定义损失函数和优化器 criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters())# 训练模型 for epoch in range(5): # 将模型设为训练模式 model.train() # 计算模型输出 logits = model(X_train) loss = criterion(logits, y_train)声明式编程
在声明式编程模型中,前端语言的表达式并不直接执行,而是构建出一个完整的前向计算过程表示,经过优化后再进行执行,这种方式被称为 define-and-run。开发者首先定义整体的神经网络模型前向表示代码,随后在 AI 框架后端将该模型编译为 静态计算图(简称:静态图)以便执行。
其执行方式相对直接:前端开发者所编写的 Python 表达式不会立即执行;而是通过 AI 框架提供的 API 定义接口,构建完整的前向计算过程,最终对数计算图进行优化后再执行。
采用声明式编程的 AI 框架的优势主要体现在:
-
在执行之前能够获取整个程序(即神经网络模型)的全貌
-
在深度学习运行前可实施编译优化算法
-
有助于实现卓越的性能优化
然而,声明式编程也存在一些明显的不足:
深度学习框架的编程范式分析
在人工智能框架中,API 对神经网络的数据类型和控制流程的定义存在一定的局限性。
由于神经网络的特殊性,AI 框架必须预先设定相关的概念(DSL),这导致了调试的困难和灵活性不足。
以 Google 的 TensorFlow 1.X 为例,其编程特性展现出计算图、会话和张量等元素,代表了典型的声明式编程风格。接下来,我们将利用 TensorFlow 构建一个隐层全连接神经网络,优化的目标是最小化预测值与真实值之间的欧氏距离。此实现通过基本的 TensorFlow 操作构建计算图,并反复执行以训练网络。
import tensorflow as tfimport numpy as np# 首先构建计算图# N 是 batch 大小;D_in 是输入大小。# H 是隐单元个数;D_out 是输出大小。N, D_in, H, D_out = 64, 1000, 100, 10# 输入和输出是 placeholder,在用 session 执行 graph 的时候# 我们会 feed 进去一个 batch 的训练数据。x = tf.placeholder(tf.float32, shape=(None, D_in))y = tf.placeholder(tf.float32, shape=(None, D_out))# 创建变量,并且随机初始化。# 在 Tensorflow 里,变量的生命周期是整个 session,因此适合用它来保存模型的参数。w1 = tf.Variable(tf.random_normal((D_in, H)))w2 = tf.Variable(tf.random_normal((H, D_out)))进入前向传播阶段后,我们将计算模型的预测值 y_pred。需要注意的是,与 PyTorch 的实现不同,此处只是定义了计算过程,并未执行计算,真正的计算将在后续的 session.run 中进行。
h = tf.matmul(x, w1)h_relu = tf.maximum(h, tf.zeros(1))y_pred = tf.matmul(h_relu, w2)# 计算 loss loss = tf.reduce_sum((y - y_pred) ** 2.0)# 计算梯度 grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])通过梯度下降法更新参数。assign 仅定义了参数更新的操作,并不会立即执行。在 TensorFlow 中,更新操作是计算图的一个组成部分,而在 PyTorch 里,由于其动态计算特性,参数更新则被视为普通的 Tensor 计算,并不属于计算图的范畴。
learning_rate = 1e-6new_w1 = w1.assign(w1 - learning_rate * grad_w1)new_w2 = w2.assign(w2 - learning_rate * grad_w2)# 计算图构建好了之后,我们需要创建一个 session 来执行计算图。with tf.Session() as sess: # 首先需要用 session 初始化变量 sess.run(tf.global_variables_initializer()) # 创建随机训练数据 x_value = np.random.randn(N, D_in) y_value = np.random.randn(N, D_out) for _ in range(500): # 用 session 多次的执行计算图。每次 feed 进去不同的数据。# 这里是模拟的,实际应该每次 feed 一个 batch 的数据。# run 的第一个参数是需要执行的计算图的节点,它依赖的节点也会自动执行,# 因此我们不需要手动执行 forward 的计算。# run 返回这些节点执行后的值,并且返回的是 numpy array loss_value, _, _ = sess.run([loss, new_w1, new_w2], feed_dict={x: x_value, y: y_value}) print(loss_value)函数式编程的优势
无论是 JAX 还是 MindSpore,这些框架均采用了函数式编程的模式,这种模式在高性能计算、科学计算及分布式计算中展现出独特的优势。
其中,JAX 是为 GPU/TPU 提供高性能并行计算的框架,其核心在于将神经网络计算与数值计算相结合。与一般的 AI 框架相比,JAX 兼容 NumPy、Scipy 等 Python 原生数据科学库,并在此基础上扩展了分布式、向量化和高阶导数计算的能力,同时也实现了硬件加速。其编程范式强调无副作用和 Lambda 闭包特性。而华为推出的 MindSpore 框架,提供了可微分的函数式编程架构,使用户能够专注于机器学习模型的数学原始表达。
本节小结
-
本节详细回顾了不同 AI 框架下深度学习的多样化编程方式。
-
深入了解了声明式编程与命令式编程的定义及其主要区别。
-
预计未来将以命令式编程为主,提升易用性,并与声明式编程的优化技术相结合。









听说声明式编程能大大提高开发效率,真的值得一试吗?