共计 3365 个字符,预计需要花费 9 分钟才能阅读完成。
编辑:元宇 好困
【新智元导读】最近,Anthropic 对其消费者条款进行了更新,这一举动引发了网友的强烈不满,甚至有人翻出了以往的争议。这种反应为何如此激烈呢?大家或许还记得 Claude 刚推出时,Anthropic 明确表示不会使用用户数据进行模型训练。然而,如今的变化不仅让其立场自相矛盾,还使得过去一些对用户的不当行为被重新提及。
最近,Anthropic 更新了其消费者条款,结果引发了公众的愤怒。
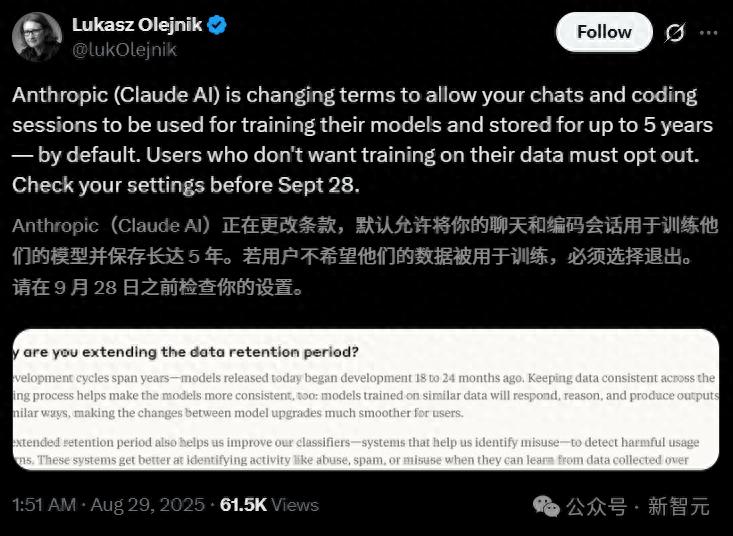
在此次条款更新中,Anthropic 改变了之前不使用用户数据进行模型训练的承诺,给现有用户提供了一个选择:是否同意使用自身的数据来进行模型训练。

看似 Anthropic 将“选择权”交给了用户,实际上仅给予了一个月的时间限制。
对于新用户来说,注册时必须做出选择;而现有用户则需在 9 月 28 日之前做出决定:
- 如果在 9 月 28 日之前选择接受,则该更新立即生效。这些条款变更仅适用于新的或重新开启的聊天与编程会话。
- 在 9 月 28 日之后,用户需要在模型训练设置中做出决定,才能继续使用 Claude 服务。
- 若用户选择将数据用于模型训练,其数据保留期将延长至五年。同时,若用户删除与 Claude 的对话,这些对话将不再用于未来的模型训练。
- 反之,如果用户未选择参与模型训练,那么公司现行的 30 天数据保留期将继续适用。
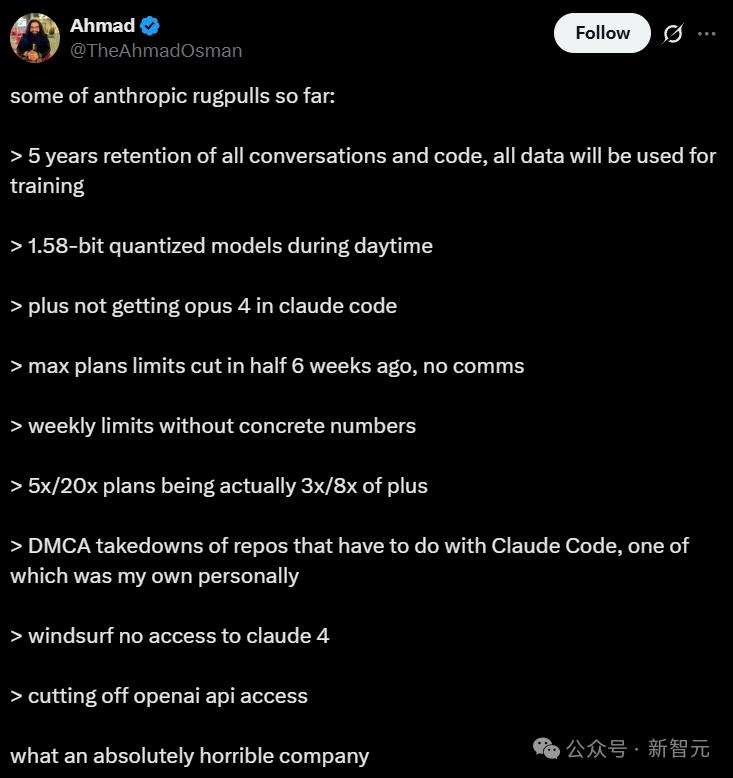
- 所有的对话记录和代码都会保留五年,并且全部用于模型训练
- 在白天悄悄将用户的模型替换为 1.58 bit 的“缩水版”量化模型
- Plus 会员在 Claude Code 中无法使用最强的 Opus 4 模型
- 六周前,Max 套餐的使用限制被毫无预警地削减了一半
- 每周的使用量上限从未具体告知用户
- 宣传的 5 倍和 20 倍套餐,实际提供的使用量仅为 Plus 套餐的三倍和八倍
- 随意发送 DMCA 通知,导致许多与 Claude Code 有关的代码库被下架,我的一个项目也因此受到了影响
- Windsurf 用户无法访问 Claude 4
- 已切断对 OpenAI API 的访问权限
此外,条款的另一项更新是:
这里提到的消费级用户包括所有使用 Claude 免费版、专业版和 Max 版的用户,此外也涵盖 Claude Code 的使用者。
而使用 Claude Gov、Claude for Work、Claude for Education 以及通过 API 接入服务的商业客户则不会受到此变更的影响。
面对 Anthropic 的这一新规,许多网友对此表示强烈不满!

不仅政策发生了变化,界面的设计也让人感觉很容易陷入误区。
揭秘 Anthropic 的种种奇葩做法,引发用户强烈反响
对于那些曾经在计算机上安装过软件的朋友来说,这种所谓的“文字游戏”绝对是耳熟能详的。

而且,Anthropic 的奇怪举动可不仅仅如此。
网友「Ahmad」在其推特中列举了 Anthropic 迄今为止的一些“背刺”行为:

用户数据,正是大公司的「金矿」
在 Anthropic 发布的关于政策更新的博客中,这些变化被包装成用户拥有选择权的形式,并宣称:
若用户不选择退出,将有助于提升模型的安全性,使我们在识别有害内容的系统变得更加精准,同时降低误标无害对话的风险。
大模型背后的真实动机:数据与用户隐私的博弈根据 Anthropic 的说法,接受新政策的用户表示:
这项调整将为未来 Claude 模型的能力如编码、分析和推理等方面的提升提供支持,最终使所有用户享受更优质的模型服务。
然而,这种美化的说法背后,实际情况却并不简单。

从行业整体来看,Anthropic 此次更新消费者条款的举措并非个案。
大模型的智能化水平提升,依赖于对真实用户数据的广泛训练。因此,各大模型公司都在竭尽全力争取更多用户数据,以不断完善其模型。
例如,谷歌近期也进行了一项相似的调整,将「Gemini Apps Activity」更名为「Keep Activity」。谷歌表示,从 9 月 2 日起,开启该设置的用户,其部分上传样本将用于「提升谷歌服务的整体质量」。

与谷歌、OpenAI 等其它大模型公司一样,Anthropic 对数据的需求显然超过了对用户品牌形象的重视程度。
Anthropic 的策略转变引发用户不满
通过接触数百万 Claude 用户的互动数据,Anthropic 能够获得更多真实编程环境下的文本数据,这将增强其在大模型领域相较于 OpenAI 和谷歌等竞争者的竞争力。
因此,我们可以推测,Anthropic 此次更新条款的真正意图,可能是为了挖掘用户数据背后的巨大价值。

Anthropic 的新规遭到广泛反对
过去,Anthropic 最吸引用户的地方在于其对数据隐私的高度重视。
自 Claude 发布以来,Anthropic 便明确表示不会利用用户数据来进行模型训练。
此前,使用 Anthropic 消费级产品的用户被告知,他们的输入和对话内容将在 30 天内被自动删除,除非法律或政策要求保留更长时间,或者内容被标记为违规(在此情况下,用户的输入及其输出的保留时间最长可达两年)。
然而,现在 Anthropic 要求新用户和现有用户必须选择是否同意其使用他们的数据来训练模型。
此外,现有用户需要在一个月内做出选择,且用户数据的保存期限也被延长至五年。

用户数据可能被用于训练模型,其中包含以下内容:
与用户的整个对话记录、任何内容及其个性化风格或偏好设置,以及在使用 Claude for Chrome 时所采集的数据。
需要注意的是,这些数据并不包括来自连接器(如 Google Drive)的原始内容,或远程和本地的 MCP 服务器,但如果这些内容直接被复制到与 Claude 的对话中,则可能会被记录。

谁来维护用户的隐私安全?
这些知名企业在悄然调整其政策,究竟谁能保护用户的隐私呢?
它们的政策变化给用户带来了不少困惑。
而且,这些公司在更新政策时,似乎有意淡化这一点。
用户隐私的隐忧:Anthropic 政策更新引发的思考

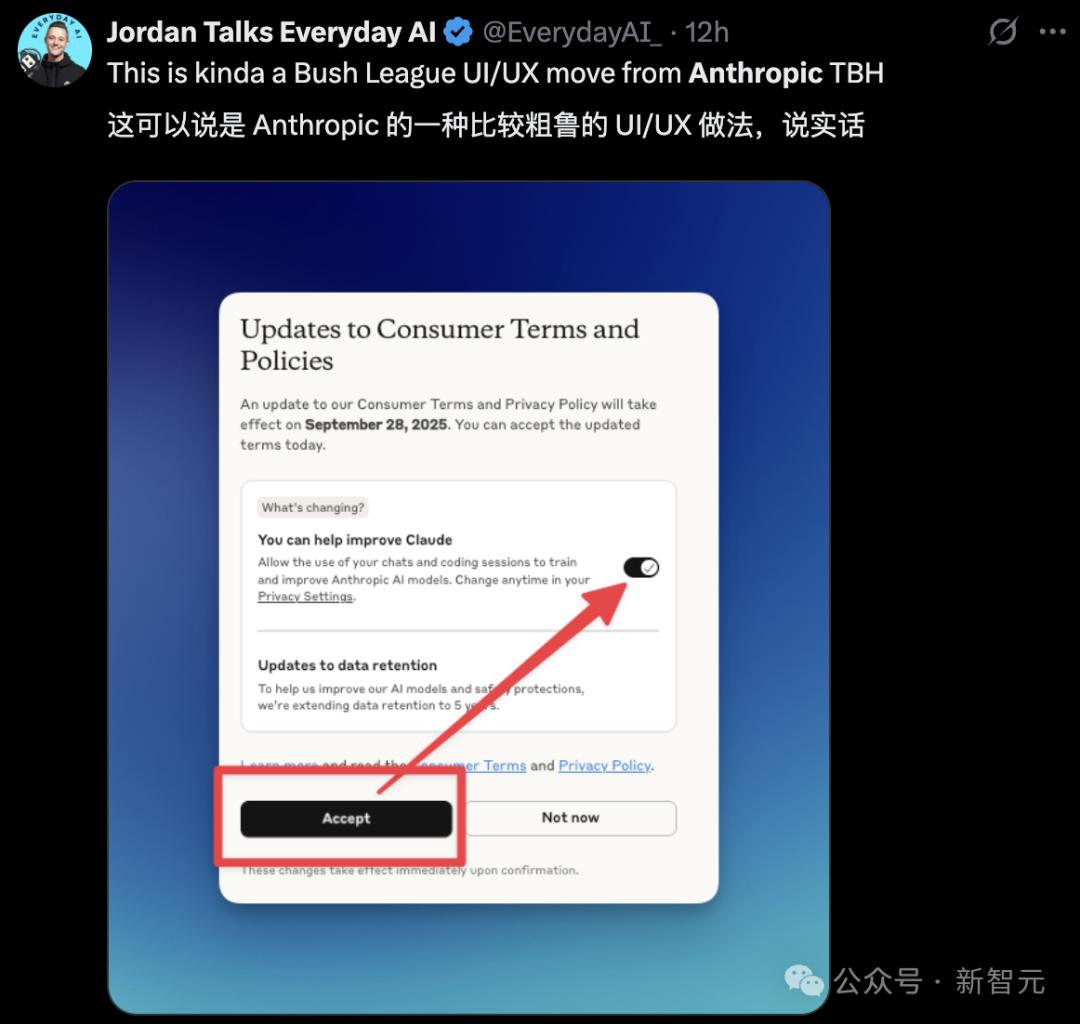
以 Anthropic 最近的界面更新为例,
在用户遇到政策更新的弹出窗口时,首先映入眼帘的是一个大标题——「消费者条款与政策更新」,旁边则是一个显眼的黑色「接受」按钮。按钮下方有一行小字和一个更小的开关,供用户授予数据训练的权限,而这个开关默认为「开启」状态。
这种设计引发了广泛的关注与担忧:
许多用户可能在并未意识到的情况下,便轻易地点击了「接受」,同意了数据共享的条款。
Anthropic 的政策调整,似乎也反映出整个行业在数据政策上的转变趋势。
在观察国际 AI 行业时,像 Anthropic、OpenAI 以及谷歌等大型企业,正因其数据保留政策而受到越来越严格的审视。
例如,最近 OpenAI 为应对《纽约时报》的版权诉讼,首次公开承认自 5 月中旬以来一直在秘密保存用户的已删除和临时聊天记录。
这一事件曝光后,网友们感到震惊:
难道那些被删除的 ChatGPT 聊天记录,都是你们存档的,准备等着法官来查吗?
回到 Anthropic 调整消费条款这一事件,它反映了公众对 AI 隐私问题日益上升的关注和忧虑。
用户数据在大模型竞争中的隐私保护挑战
在当今大模型竞争日益激烈的环境中,用户数据已成为决定胜负的关键因素。如何在确保模型性能的同时,有效地保护用户的隐私信息,已成为各大模型开发公司必须认真面对的重要课题。
参考资料:
https://www.zdnet.com/article/anthropic-will-start-training-claude-on-user-data-but-you-dont-have-to-share-yours/
https://www.theverge.com/anthropic/767507/anthropic-user-data-consumers-ai-models-training-privacy
https://www.businessinsider.com/anthropic-uses-chats-train-claude-opt-out-data-privacy-2025-8