
共计 4512 个字符,预计需要花费 12 分钟才能阅读完成。
审校 | 重楼
引言
现如今,许多依赖人工智能(AI)编程助手的用户,主要使用 Claude Code、GitHub Copilot 和Cursor 等云服务工具。尽管这些工具的性能非常出色,但它们存在一个显著的缺陷:为了使其正常运行,你的代码需要传递到外部服务器。
这意味着,在得到结果之前,你的每个函数、应用编程接口(API)密钥和内部架构选择都将被传送给 Anthropic、OpenAI 等服务提供商。尽管他们声称会保护用户隐私,但对于许多团队而言,这种风险是难以承受的,尤其是在处理以下类型的情况时:
•专有或机密的代码库
•企业客户系统
•研究项目或政府相关的工作
•任何受保密协议(NDA)约束的内容
在这种情况下,本地开源编程模型显得尤为重要。
通过在本地运行人工智能模型,你将拥有更多的控制权、隐私保护和安全性。所有代码均不会离开你的设备,外部日志也不会被生成,完全不需要依赖“相信我们”的承诺。此外,若你拥有高性能的硬件,还能够节省大量的 API 和订阅费用,可能高达数千美元。
在本文中,我们将探讨七款开源的 AI 编程模型,这些模型在编程基准测试中表现优异,并逐渐成为专有工具的有力替代选择。
文章的最后部分将提供这七种模型的比较表,帮助你迅速掌握相关信息。
1. Moonshot AI 的 Kimi-K2-Thinking
Kimi-K2-Thinking:开源智能体的未来
Kimi-K2-Thinking 是由 Moonshot AI 团队研发的一款尖端开源思维模型,旨在作为智能体工具,为用户提供逐步推理的能力,同时能够灵活调用各种函数和服务。该模型在进行 200 到 300 次连续的工具调用时,展现出了极为稳定的长期智能体表现,较以往系统在经历 30 到 50 个步骤后出现的漂移问题,取得了显著的改善。这一进步使得研究、编程及写作等流程能够实现更高效的自动化。
从架构设计来看,K2 Thinking 模型具备高达 1 万亿的参数,其中 320 亿个为活跃参数。它的结构包含了 384 个专家,每个 token 选择 8 个专家,同时还有 1 个共享专家。此外,模型设有 61 层(其中包括 1 层密集层),以及 7168 个注意力维度和 64 个注意力头。该模型应用了 MLA 注意力机制与 SwiGLU 激活函数,支持 256000 个 token 的上下文窗口,词汇表则包含了 160000 个词汇。值得一提的是,它是一款原生 INT4 模型,利用训练后量化感知训练(QAT)技术,能够在低延迟模式下实现约 2 倍的速度提升,并有效减少 GPU 内存的占用。
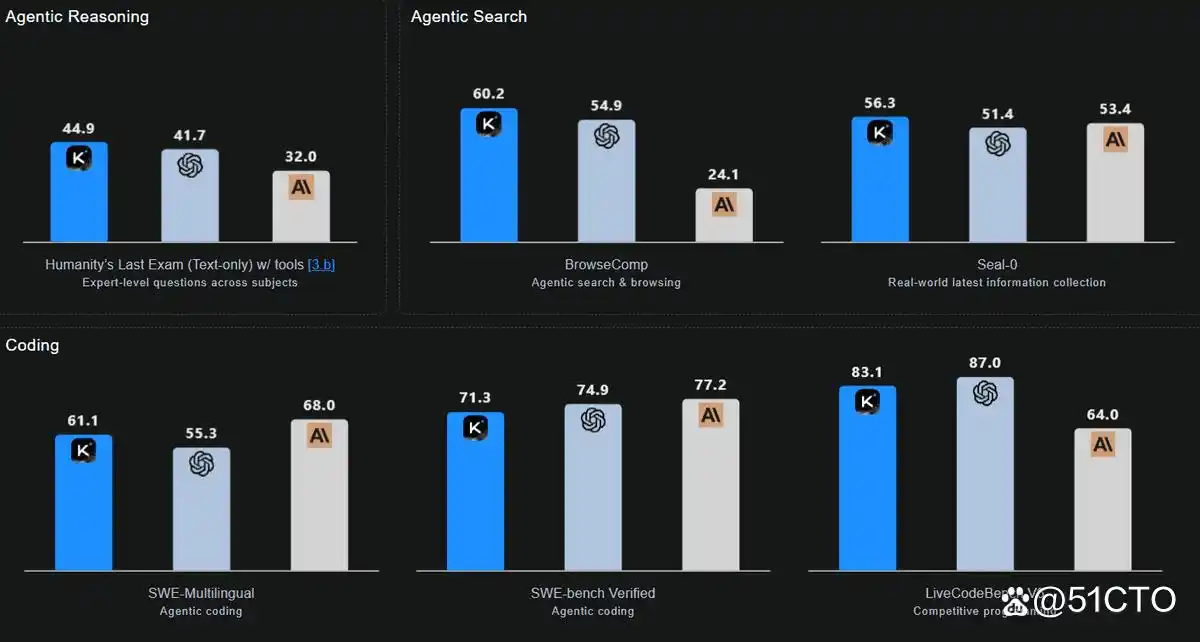
K2 Thinking 的卓越表现与 MiniMax-M2 的创新设计
在各项基准测试中,K2 Thinking 展示出了令人瞩目的成绩,特别是在需要长期推理和工具运用的领域。其编程能力全面且均衡,在多个测试中表现出色,分别在 SWE-bench Verified、Multi-SWE、SciCode 和 Terminal-Bench 等评测中获得了 71.3 分、41.9 分、44.8 分和 47.1 分的优异成绩。尤其是在 LiveCodeBench V6 的测试中,K2 Thinking 以 83.1 分的佳绩凸显了其在多语言处理和智能体工作流程中的强大能力。
2. MiniMaxAI 的 MiniMax-M2
MiniMax-M2 重新定义了智能体工作流程的高效性。这款紧凑、快速且经济实惠的专家混合(MoE)模型拥有 2300 亿个参数,每次处理 token 时仅激活其中的 100 亿个参数。通过智能路由选择最相关的专家,MiniMax-M2 达到了通常仅大型模型才能实现的端到端工具使用性能,同时显著降低了延迟、成本和内存占用,使其成为理想的互动智能体和批量采样工具。
MiniMax-M2 的设计专注于精英编程与智能体任务,且不损失通用智能,其工作流程围绕“计划→执行→验证”循环展开。由于仅需激活 100 亿个参数,这些循环依然保持高速响应。
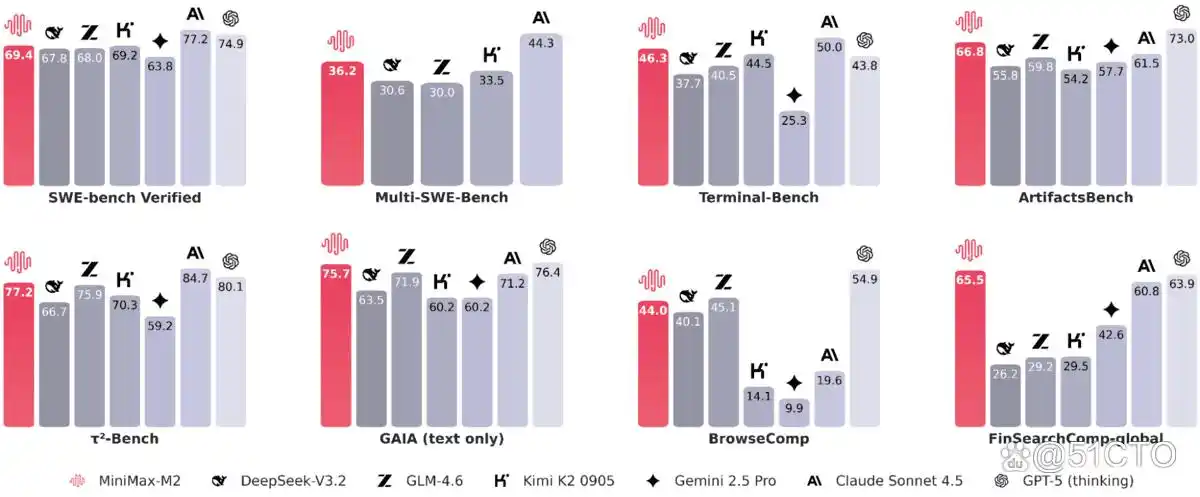
强大的智能体评测与 OpenAI 的创新模型
在编程实践和智能体的基准测试中,展现了显著的实用性能。具体成绩如下:SWE-bench的得分为 69.4,Multi-SWE-Bench 得分为 36.2,而SWE-bench Multilingual 的得分则为 56.5。在Terminal-Bench 中,得分为 46.3,而ArtifactsBench 则取得了 66.8 的好成绩。针对网页和研究智能体的评测得分情况如下:BrowseComp的得分为 44(其中中文得分为48.5),GAIA(文本)得分为75.7,xbench-DeepSearch 得到了 72 的评分,而 τ²-Bench 则高达 77.2。同时,HLE(带工具)获得了31.8,FinSearchComp-global 得分为65.5。
3. OpenAI 的 GPT-OSS-120B 模型
GPT-OSS-120B是一个开放权重的 MoE 模型,旨在满足通用性和高推理需求的实际应用。该模型针对在一台 80GB GPU 上运行进行了专门优化,拥有 1170 亿个参数,每个 token 具有 51 亿个活跃参数。
GPT-OSS-120B的核心功能涵盖:可调节的推理复杂度(低、中、高)、用于调试的完整思路链可访问性(但最终用户无法使用)、内置智能体工具(包括函数调用、浏览、Python集成和结构化输出)以及全面的微调功能。此外,针对需要快速响应和个性化应用的用户,配套的小型化模型 GPT-OSS-120B 也提供了相应的选择。
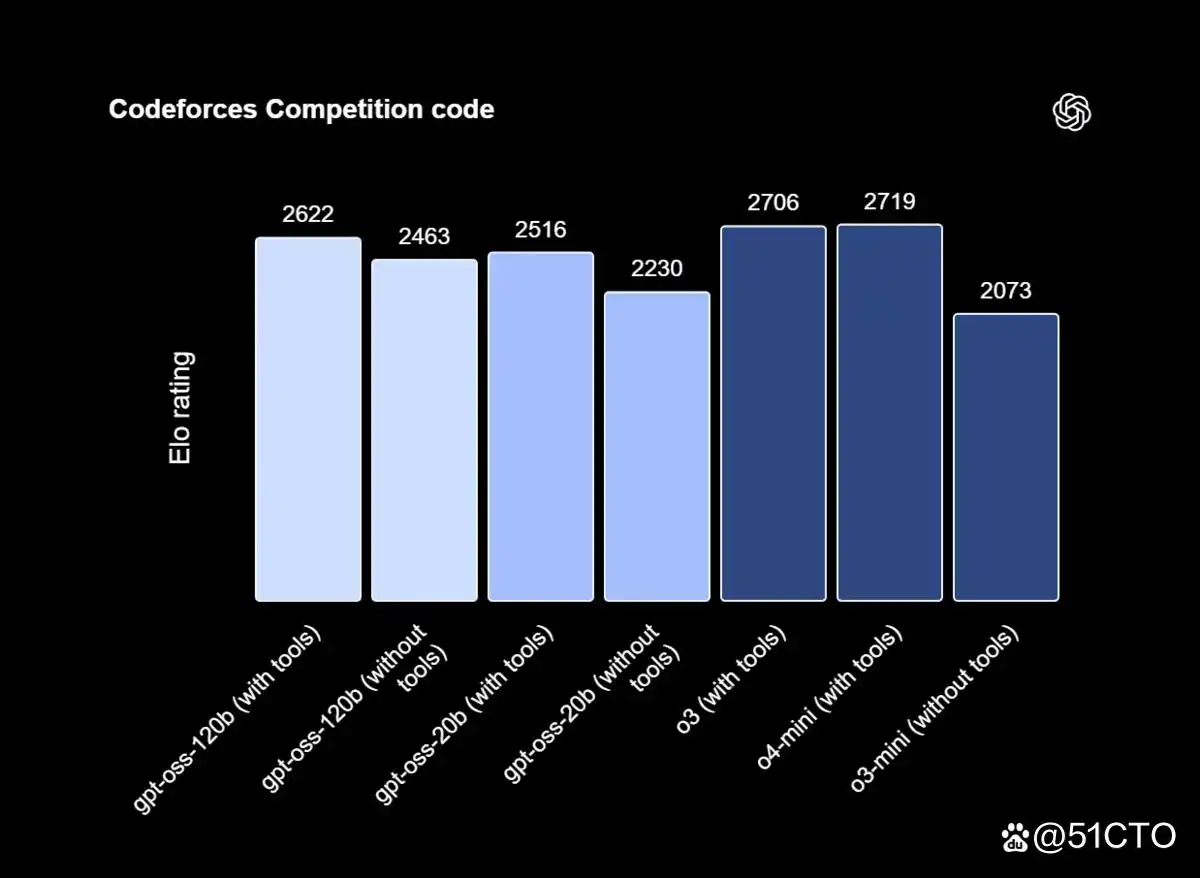
GPT-OSS-120B:在人工智能领域的突出表现
在外部基准测试中,GPT-OSS-120B 的表现引人注目,在人工智能分析智能指数中稳居第三位。该指数通过评估不同模型的质量、响应速度和延迟,对其进行了全面比较,结果显示,GPT-OSS-120B 展现出与其规模相匹配的卓越性能和速度。
在诸如竞赛编程(Codeforces)、通用问题求解(MMLU、HLE)以及工具使用(TauBench)等领域,GPT-OSS-120B 均超过了 o3-mini,并且在许多方面的表现与 o4-mini 相当或更佳。此外,该模型在健康评估(HealthBench)和竞赛数学(AIME 2024 和 2025)方面的成绩同样优于 o4-mini,显示了其全面的竞争力。
4. DeepSeek AI 的 DeepSeek-V3.2-Exp
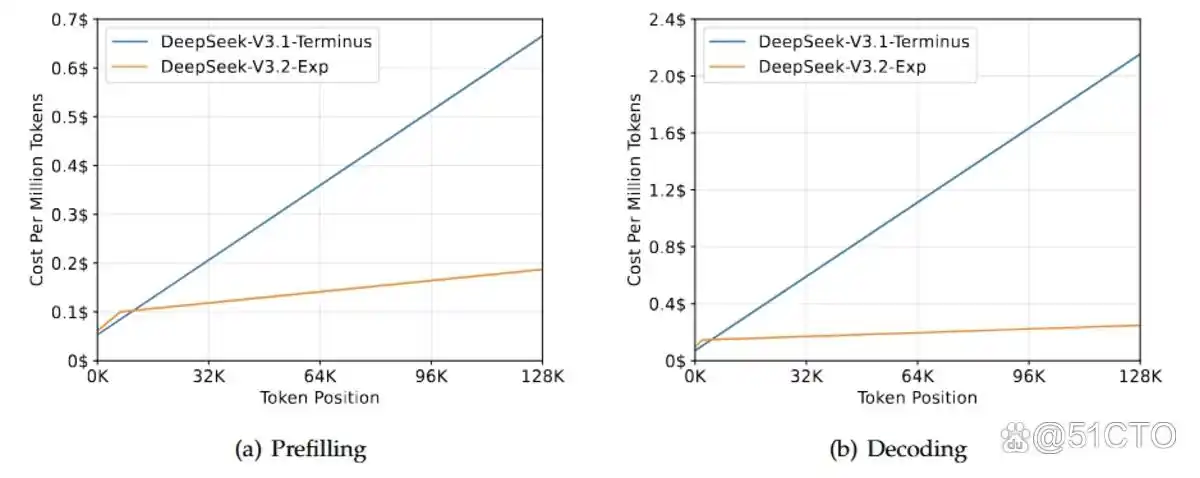
DeepSeek-V3.2-Exp 是 DeepSeek AI 推出的下一代架构的实验性过渡版本。该版本以 V3.1-Terminus 为基础,融入了 DeepSeek 稀疏注意力机制(DSA)。DSA 是一种细粒度的稀疏注意力机制,旨在提高长上下文场景下的训练和推理效率。
该版本的主要目标是在确保模型稳定性的基础上,验证在扩展序列中的效率提升。为了隔离 DSA 的影响,训练配置与 V3.1 保持一致。结果显示,输出质量几乎没有变化,证明了该机制的有效性。
探索 GLM-4.6 的卓越性能与改进
在公开的基准测试中,V3.2-Exp 的表现与 V3.1-Terminus 相似,仅存在微小的差异。例如,在 MMLU-Pro 测试中,该版本获得了 85.0 的分数,而在 LiveCodeBench 测试中的得分也接近 74 分;在 GPQA 测试中,其结果略低于 80.7,得分为 79.9;同样,在 HLE 测试中,其 19.8 的得分也低于 21.7。此外,AIME 2025 测试中得分有所提升,达到了 89.3,相比之下,V3.1-Terminus 为 88.4。而在 Codeforces 测试中,V3.2-Exp 同样表现出色,得分为 2121,相较于 2046 的表现也有明显改善。
5.Z.ai 的 GLM-4.6 版本分析
与 GLM-4.5 相比,GLM-4.6 显著扩展了上下文窗口,从 128K 个 token 增加到 200K 个 token。这一增强功能支持了更加复杂和长期的工作流程,同时有效跟踪信息的准确性。
GLM-4.6 在编程性能方面也表现卓越,其在代码基准测试中的得分更高,同时在 Claude Code、Cline、Roo Code 和 Kilo Code 等工具中展现了更为强大的实际应用效果,尤其是在前端生成的精细化上。
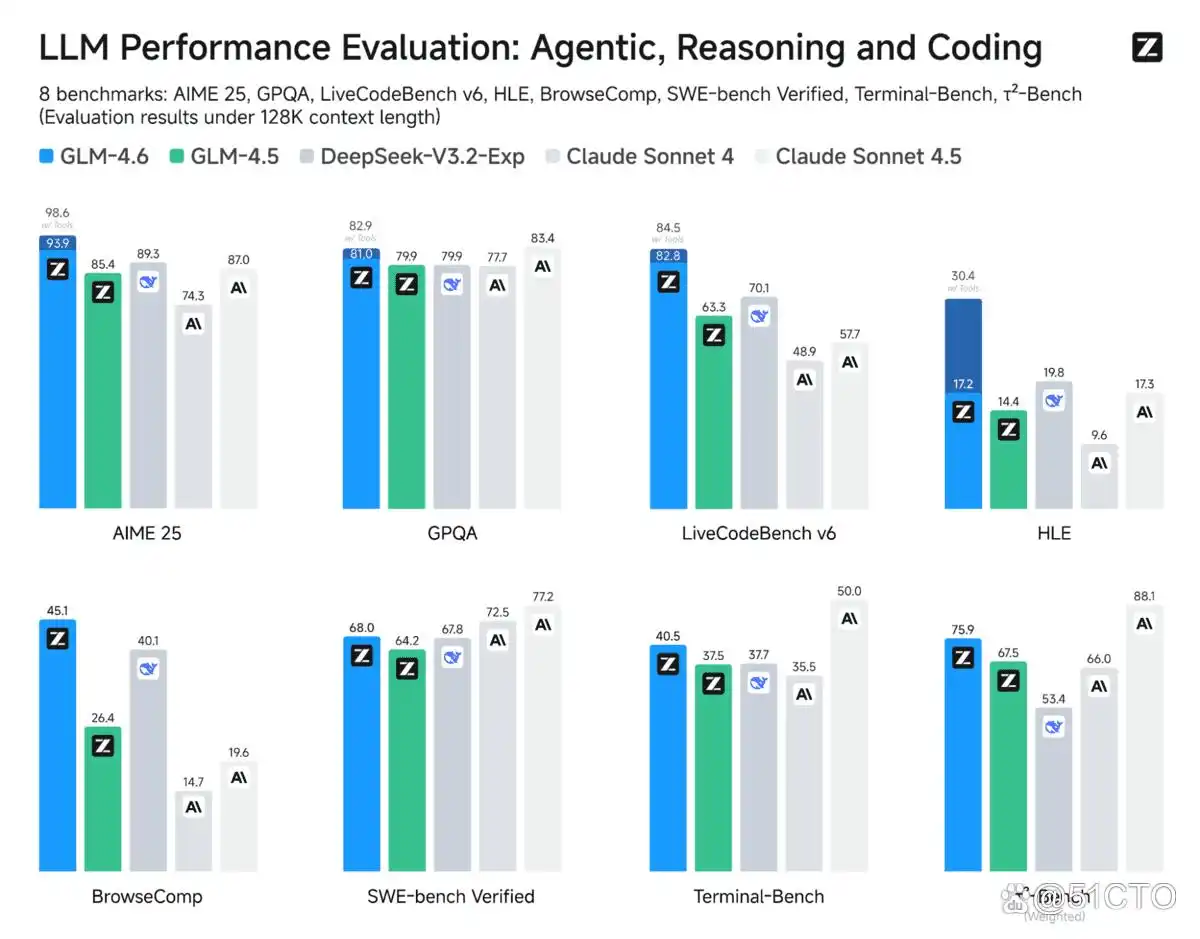
此外,GLM-4.6 还引入了更高级的推理功能,利用工具的支持提升了整体性能。此版本的智能体功能更为强大,增强了工具的使用效果和搜索能力,并与智能体框架实现了更紧密的结合。
智能模型的最新进展:GLM-4.6 与 Qwen3-235B 的表现对比
在涉及智能体、推理和编程的八项公开基准测试中,GLM-4.6表现出显著的优势,相较于 GLM-4.5 有了明显进步。同时,它也与 DeepSeek-V3.1-Terminus 及Claude Sonnet 4等其他竞争模型保持了平衡的竞争力。
6. 阿里云的 Qwen3-235B-A22B-Instruct-2507
Qwen3-235B-A22B-Instruct-2507是阿里云推出的旗舰模型,着重于实际应用,而非揭示推理过程。其在多个领域的能力得到了显著增强,包括指令跟踪、逻辑推理、数学、科学、编程及工具的使用。此外,该模型在处理多语言长尾知识方面也有了显著突破,能更准确地满足用户在主观性和开放任务中的偏好。
作为一款非思维模型,它的核心目标是提供直接的答案,而非展示推理的过程,专注于生成高质量的文本以支持日常工作需求。
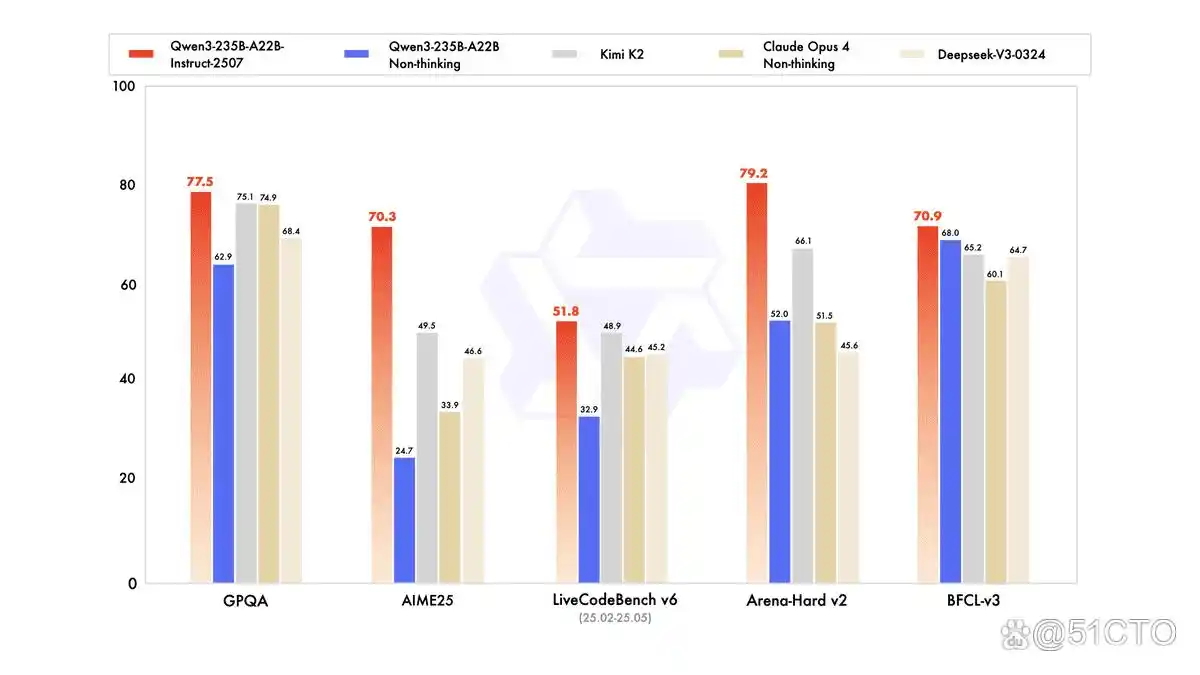
在与智能体、推理和编程相关的各项公开测试中,该模型显然较旧版本有了质的飞跃。根据第三方的评估,其在与领先的开源和专有模型(如 Kimi-K2、DeepSeek-V3-0324 及Claude-Opus4-Non-thinking)的竞争中,依然保持着优势地位。
7. ServiceNow AI 的 Apriel-1.5-15B-Thinker
Apriel-1.5-15B-Thinker是 ServiceNow AI 推出的 Apriel 小语言模型系列中的多模态推理模型。与前一版本的文本模型不同,它新增了图像推理能力,显示出强大的训练中期方案。这一方案包括对文本和图像的广泛预训练,随后进行仅基于文本的监督微调(SFT),而无需任何图像的 SFT 或强化学习。尽管其参数量为 150 亿,便于在单个 GPU 上运行,但其上下文长度据称可达到 131000 个token。该模型的设计旨在与十倍参数量的模型在性能和效率上相媲美,特别是在推理任务方面表现优异。
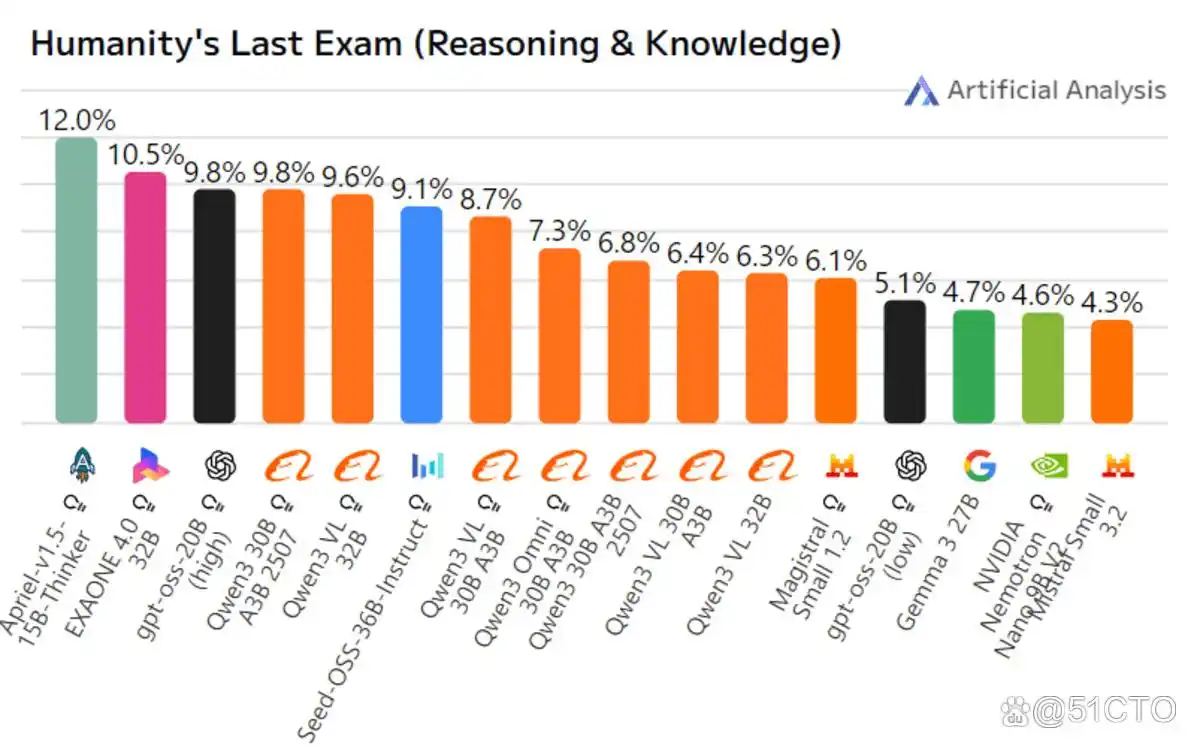
在公开的基准测试中,Apriel-1.5-15B-Thinker的人工智能分析指数(AII)得到了 52 分,这使它能够与 DeepSeek-R1-0528 及Gemini-Flash等其他模型相竞争。值得注意的是,它的规模仅为那些得分超过 50 分模型的十分之一。此外,作为一款企业级智能体,它在 Tau2 Bench Telecom 和IFBench 的测试中分别取得了 68 和62的高分。
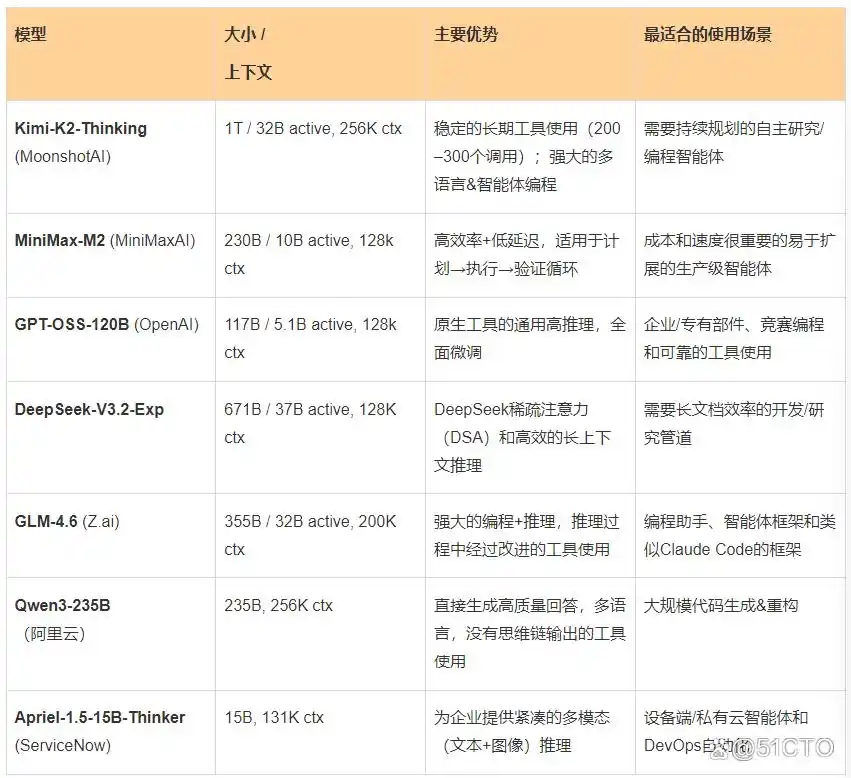
总结一览表
以下是适合特定使用场景的开源模型概述。
原文标题:你可能错过的七个开源 AI 编码模型,作者:Abid Ali Awan








开源AI模型在隐私保护上确实有优势,但对于如何有效集成到现有开发流程中,仍有很多具体问题需要解决。希望能提供一些实际操作的指导。