
共计 5315 个字符,预计需要花费 14 分钟才能阅读完成。
在今天的凌晨时分,GPT 5.2 正式面向所有用户发布,力求超越 Gemini。
上个月,我刚取消了 ChatGPT Plus 的订阅,转向 Gemini。现在,是否需要因 GPT-5.2 的发布而重新考虑呢?
通过阅读网友的真实体验和 APPSO 的测试结果,或许能够找到答案。
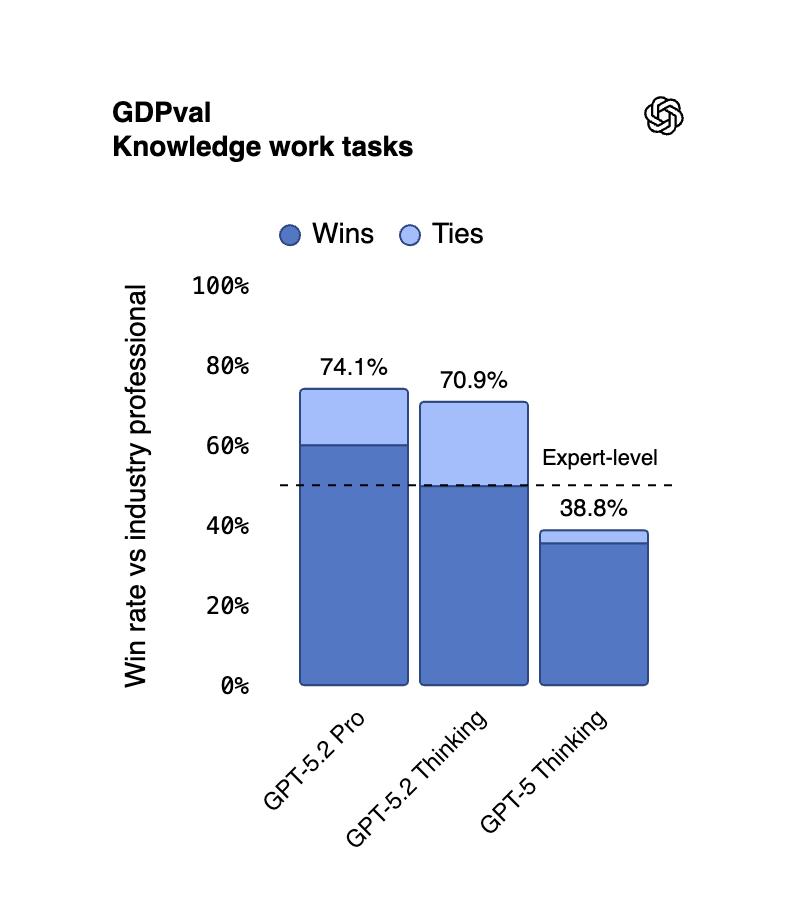
这次终于没有画错表了。
GPT 5.2 实际上更新了三种模型:Instant、Thinking 和 Pro。如果你习惯了使用 Gemini 3.0 Pro,每次问答都经过深思熟虑,那么在使用 GPT-5.2 的 Thinking 或 Pro 模型时,可能会感觉到思考速度有所减缓,所需的时间比之前更长。
这一点在许多提前体验的用户分享中得到了证实。他们表示,GPT-5.2 相较于 5.1 在多个方面都有显著提升,而 GPT-5.2 Pro 特别适合于复杂推理和需要较长时间完成的任务,不过这也导致了结果等待的时间变得更加漫长。
例如,有用户反映,当他输入「帮我绘制一张 HLE 测试成绩的图表」时,GPT-5.2 Pro 足足花了 24 分钟才生成了这张表。
图片来源:
https://x.com/emollick/status/1999185755617300796/photo/1
值得庆幸的是,所有生成的信息都非常准确,尽管图表中显示最优结果的还是 Gemini 3.0 Pro。
这归功于 GPT-5.2 的知识更新至 2025 年 8 月,而 GPT-5.1 的知识截止日期则为 2024 年 9 月,而上月发布的 Gemini 3.0 截止到 2025 年 1 月。
在使用 GPT-5.2 Thinking 生成 OpenAI 模型发布历史图表时,反而没有花费太多时间,且信息相对准确。对于简单任务而言,Thinking 模型与 Pro 模型之间的时间差异十分明显。
凭借超强的推理能力和最新的全球知识,结合图像的多模态理解与推理,GPT 5.2迅速在大型模型竞争中崭露头角,跃升至第二位。在网页开发项目中,GPT-5.2-High的排名紧随其后,位列第二,而GPT-5.2则位于第六。相比之下,Gemini 3.0 Pro排名第三,第一名依旧属于Claude。
LMArena官方还发布了一段实测视频,展示了GPT-5.2在完成一系列3D建模任务时的高完成度。然而,视频下方的评论区也有网友感叹道:“现在还是停留在2003年吗?”
这种利用three.js实现的3D效果,极其依赖模型的多模态理解、推理能力,以及在编程与程序设计方面的优化;显然,GPT-5.2的0.1版本升级是值得的。
目前,许多网友纷纷分享测试结果,而这些测试主要集中在构建完整的3D引擎上,GPT-5.2的表现也相当出色。例如,使用GPT-5.2 Thinking的高难度推理模式,在同一页面中成功构建了一个可以交互控制且支持导出4K分辨率的3D雪天冰块王国模型。
此外,还有基于GPT-5.2 Pro实现的3D波涛汹涌的哥特城市建筑作品。
提示词:创造一个视觉上吸引人的着色器,能够在twigl-dot-app中运行,仿佛是一个被狂风巨浪部分淹没的无限新哥特塔楼城市。|来源:
https://x.com/emollick/status/1999185085719887978?s=20
探索3D艺术的边界:从图像生成到动态模拟
在对3D理解与推理能力的研究中,我们借鉴了Ian Goodfellow在Gemini 3.0 Pro发布时所使用的一个提示:上传一张图片,并指导模型基于该图像创建一个引人入胜的体素艺术场景,运用Three.js进行展示。

由于ChatGPT并未在画布内直接生成结果,我决定复制它在对话框里生成的代码,并在HTML视图中打开,效果如右图所示。
这个差异显而易见。虽然ChatGPT成功识别了上传图像中的内容,比如一棵粉红色的书、一片绿地、灰色的沉降和白色的水流,但其生成的3D动画与Gemini 3.0 Pro相比,显得有些简陋。
我只能说,奥特曼发出这个「红色警报」,说明了Gemini的实力。
在编程能力的检验中,经典的六边形小球物理运动测试是必不可少的。有博主通过增加小球的运动难度,用闪亮的红色3D小球来展示,效果非常炫酷,吸引了许多网友的关注,他们纷纷询问该如何实现;但也有网友提出,这些小球似乎并不受重力的影响。
随后,有网友回应表示,这是在模拟太空环境。

视频来源:
https://x.com/flavioAd/status/1999183432203567339
还有SVG代码的测试,其中包括骑自行车的鹈鹕。
图片
此外,有网友展示了他们使用GPT-5.2制作的森林火灾模拟器,能够调节速度、区域大小和火焰蔓延范围等多项参数。

图片来源:
https://x.com/1littlecoder/status/1999191170581434557?s=20
我们还创建了一个星球信号的网页,与这个森林火灾可视化网页有着相似的布局,左侧显示内容,而星星点点则换成了太空中的星球。
标题:探索AI编程新境界:从拍立得到交通灯模拟我们构建了一个网页,灵感来源于森林火灾可视化,左侧展示内容,右侧则展示太空中的星球,形成一种独特的星球信号展示效果。
我们还尝试了使用之前的Gemini 3进行拍立得风格的网页相机应用开发。输入相同的提示,要求它创造出一个复古风格的相机网页。
该模拟应用的设计要求背景为软木板或深色木纹,左下角则固定一个使用纯CSS或SVG绘制的拟物化拍立得相机模型,镜头区域实时显示用户的摄像头画面。用户点击快门按钮时,会播放快门声,并让一张带有白色边框的相纸从相机顶部缓缓吐出。通过CSS滤镜,滑出的照片初始为高模糊黑白效果,经过5秒的平滑过渡后呈现清晰全彩状态。此外,所有显影完成的照片可以自由拖动,用户可随意摆放,并且照片会有随机旋转角度和阴影效果,点击某张照片可将其置顶,形成一个生动的拼贴墙。
令人惊讶的是,ChatGPT的表现相当出色,成功实现了拍立得应用的构建。
在测试Gemini 3.0 Pro时,我们发现它的编程能力强大,无需输入过多提示,只需提供截屏或视频,它就能轻松复刻。此次我们同样把一个视频提供给它,要求它重现古诗词生成网页的效果。
通过对比,我们发现GPT-5.1在处理视频配色方案时表现平平,而这次的GPT-5.2显然有所进步。尽管Gemini生成的网页可以直接添加AI功能,并通过API实现更为复杂的效果,但ChatGPT目前尚未将AI功能融入生成的网页中,因此诗歌部分仍然局限于已写好的几首。
除了经典的编程能力测试,一些网友还利用它编写Python代码。输入的提示是“编写一个Python代码,模拟单行道上交通灯的工作原理,并可视化随机速率进入的车辆”。
同时,他测试了GPT-5.2扩展思维和Claude Opus 4.5,结果不言而喻。我们经常收到读者询问哪个编程模型最优秀,Claude受到众多开发者的青睐,自然有其原因。
GPT-5.2与Claude Opus 4.5的深度比较:谁更胜一筹?
下方展示的是GPT-5.2,来源于:
https://x.com/diegocabezas01/status/1999228052379754508
值得注意的是,Claude模型曾被批评的一个主要问题是其费用较高,Claude Opus 4.5每百万个Token的输入费用为5美元,而输出则高达25美元。与之相比,GPT-5.2的定价也在不断上涨,相较于GPT-5.1,整体成本增加了40%。具体来说,GPT-5.2 Pro的输入费用为21美元,输出费用则达到168美元。
在OpenAI的官方博客中,提到GPT-5.2在图像处理能力上有显著提升。
GPT-5.2 Thinking被认为是目前最强大的视觉模型,其在图表推理和软件界面理解的错误率几乎减少了一半。
OpenAI给出了一个示例,展示了一块模糊的主板,它利用AI和一些带框的标记进行分析。虽然GPT-5.1和GPT-5.2在某些地方会犯错,但后者标记的区域显然更多。
那么,Nano Banana Pro如何呢?有网友使用Nano Banana Pro去掉了图片中的标注信息,并重新要求其标记新的目标框。你认为哪个更好呢?
从左到右依次为GPT-5.1、GPT-5.2和Nano Banana Pro|图片来源:
https://x.com/bcaine/status/1999212747213656072
我的观察是,ChatGPT似乎在其他模型擅长的领域中“自取其辱”。Nano Banana在图像处理方面的表现无疑是行业领先的。尽管GPT-5.2的标记信息有所增加,但许多检测框的定位依然不够准确。
在编程和图像对比方面,GPT-5.2相比前代的GPT-5.1确实有了显著的进步。长期使用ChatGPT的用户应该会明显感受到这种升级带来的变化。然而,与其他模型相比,无论是在编程还是图像处理方面,仍然没有达到Nano Banana推出时的领先地位。
在审美和网页设计的领域,也有网友分享了他们用GPT-5.2制作的前端网页。大家可以关注一下,这次前端程序员是否又要面临新的挑战。
图片来源:
https://p3-sign.toutiaoimg.com/tos-cn-i-tjoges91tu/23bfd127cb2561e33a34dc8dc50ec903~tplv-tt-origin-web:gif.jpeg?_iz=58558&from=article.pc_detail&lk3s=953192f4&x-expires=1769277280&x-signature=mLbagDbWCcWYwMollQ8FEQ5nCdQ%3D
标题:GPT-5.2:突破与不足并存的设计进化
与之前普遍存在的渐变紫色相比,GPT-5.2 的设计水平显著提升。然而,正如博主所提到的,这个版本似乎特别偏爱在屏幕上绘制方框,导致网格层层叠叠,令人印象深刻。
在设计能力的排名中,GPT-5.2 的表现同样令人瞩目。它从之前的十名开外飞速跃升至第三位,仅次于得分最高的 Gemini 3.0 Pro。
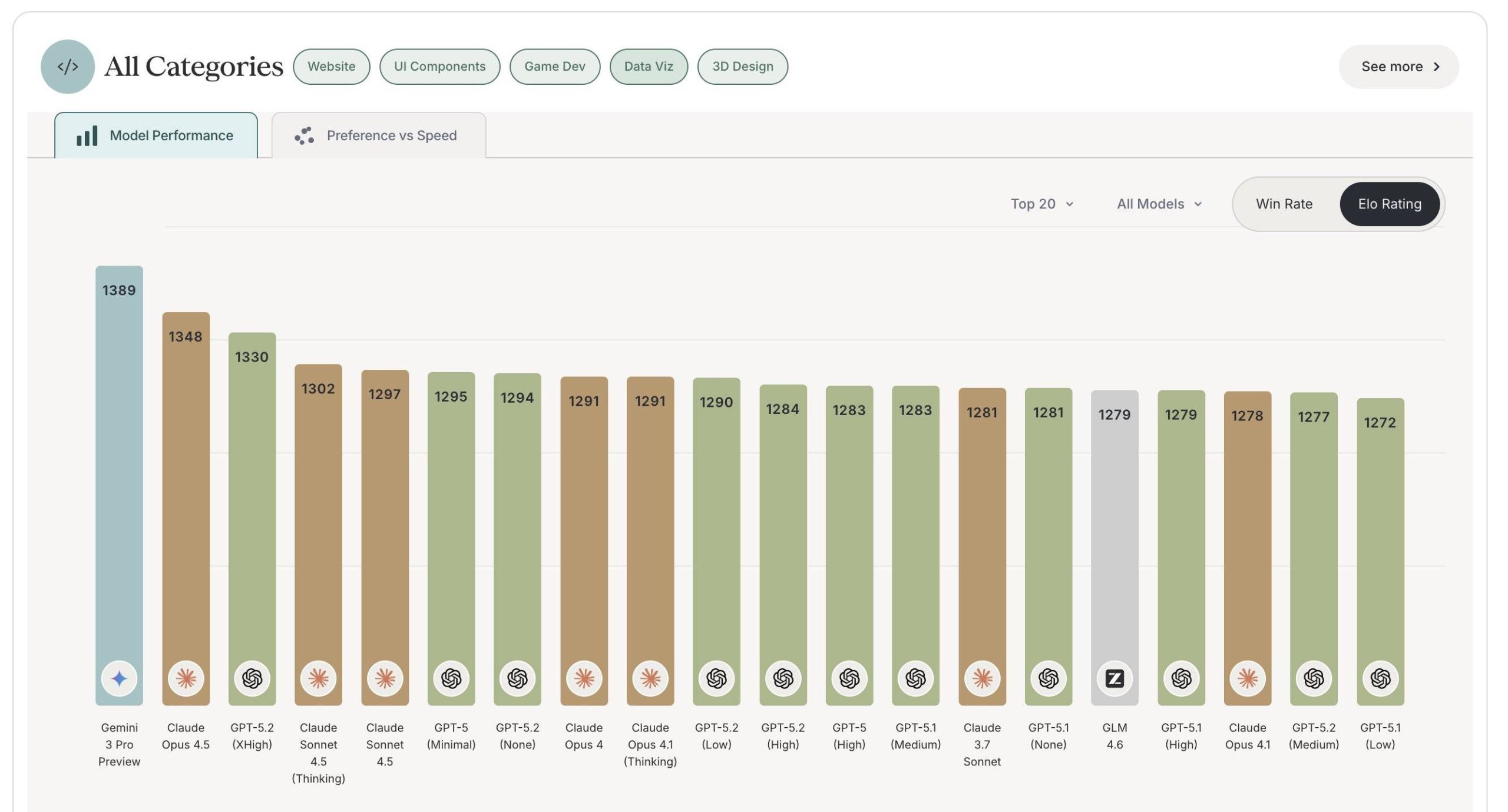
图片来源:
https://www.designarena.ai/leaderboard
我们为 GPT-5.2 提出了设计一个“高大上”网页的任务,目标是为一家人工智能公司制作首页。结果显示,GPT-5.2 依旧偏爱使用方框,渐变紫色的运用再次出现。
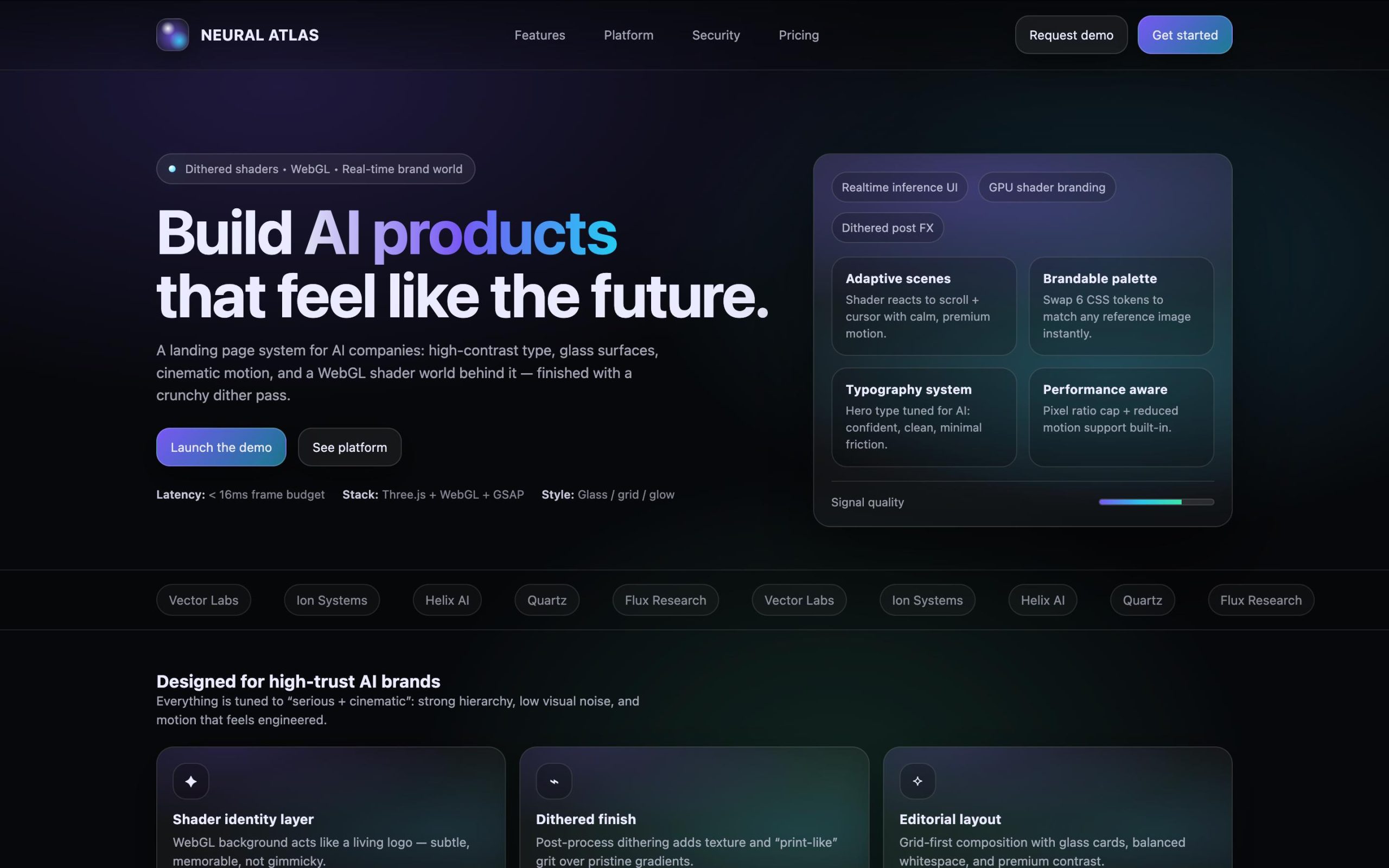
提示词:您是全球前沿设计与开发领域的顶尖设计师和开发者,任务是为AI公司创建一个完整的登陆页面,风格应与上传的图像相符,使用 {Dither + Shaders} 和 {WebGL + ThreeJs}。请主要专注于设计部分,而非开发。导入所有必要的文件和库:Three.js、WebGL、GSAP以及其他与3D开发相关的动画库。
最后,关于写作能力,GPT-5.2 在一些早期体验用户的反馈中显示出其创作长篇小说的潜力。
例如,当 ChatGPT 被要求生成 50 个情节创意时,它能够一次性完成,而不是像其他模型那样只给出部分内容。即便是生成一本 200 页的书籍请求,ChatGPT 也没有退缩,而是积极尝试,不仅构建了书籍的大致结构,还生成了 PDF 文件。
网友们指出,尽管书籍的质量相对较低,篇幅也较短,毕竟在当前阶段,它不可能一口气写出一本可出版的小说,但能够开始尝试,提供 50 个创意和构建 200 页的书,说明它具备了相当的思维深度。
最让人瞩目的地方在于,GPT-5.2 能够有效执行指令……它不仅仅是表面上跟随要求,而是真正完成了整个描述的任务。
目前,GPT-5.2 似乎已经逐步推送给所有用户,您的实际体验如何?
尽管 GPT-5.2 的升级在榜单上取得了多个亮眼成绩,但这并不足以让我从 Gemini 转向它。尽管在许多测试中表现出色,尤其是在生成 3D 程序的过程中,代码错误时有发生,同时整体审美风格也未能实现突破,而且它的价格仍然较为昂贵。
Gemini持续施压,技术升级引发关注
网友锐评
Gemini团队并未停下脚步,继续对奥特曼施加压力。尽管今晨没有推出新的模型,但他们对Gemini Deep Research进行了重新设计,并且现已可通过API进行访问。此外,未来还将对Gemini、Google搜索以及NotebookLM进行升级。

全新的Gemini深度研究Agent在“人类最后的考试”(HLE)中,以46.4%的成绩超越了刚发布的GPT-5.2 Thinking(45.5%)。同时,在Google推出的DeepSearchQA测试和BrowseComp测试中也取得了良好的效果。
看来,奥特曼的红色警报还将持续一段时间。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),我们将为您第一时间带来更多精彩内容。
爱范儿|原文链接· ·新浪微博








价格上涨的确让人难以理解,但功能提升有限是否会让用户感到失望呢?期待未来版本能在实用性上有所突破。