
共计 3403 个字符,预计需要花费 9 分钟才能阅读完成。
近期,Anthropic 推出的 Agent Skills 在社交媒体上引发了广泛讨论,各种评论和比喻层出不穷,诸如“改变游戏规则者”、“范式转变”、“私人军火库”等形象说法让人眼花缭乱。坦白说,这些都让我感到一头雾水。
那么,究竟什么是 Skills 呢?实际上,Anthropic 的工程博客对此进行了详细说明:https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skill
今天,我想分享一下对 Skills 的看法,但我不会探讨其具体应用(相关文档可自行查阅),也不会幻想 Skills 的未来(实际上,未来无人能知),我仅仅想客观地分析 Skills 出现的原因。
看完这篇文章后,你会明白:Skills 的出现是工程进化的必然结果,而非某位天才的突发奇想。
这篇文章适合那些想要了解 Skills 概念的人阅读。如果你对 Skills 一无所知,建议先阅读上面提供的官方文章链接。
回到正题,要想全面理解 Skills,首先得从 MCP 谈起(如果不清楚 MCP 的含义,可以先参考我的文章《MCP 到底是个什么鬼?》,否则后续内容可能难以理解)。
自 MCP 问世以来,短短一年时间里,它确实扩展了大语言模型(LLM)的能力边界,但同时也暴露出几个潜在的缺陷:
- 工具选择不准确
- 工具参数设置不当
- 占用过多上下文空间(不仅增加成本,还影响模型的注意力)
我们逐一分析这些问题。
首先,关于工具选择不准确的问题。这个比较容易理解,在少量工具的情况下,LLM 通常能较为准确地选用合适的工具(前提是函数名和描述足够清晰)。但在生产环境中,工具数量会显著增加,一旦工具数量增多,LLM 容易产生混淆,导致选择错误。有人可能会问,这不简单吗?在传递工具时进行过滤就能解决了吧?确实,这是一种常用的工程手段,但接下来我们再看。
其次,关于工具参数设置不当。你是否注意到,大多数稳定可靠的 MCP 工具,其参数都相对简单?无论是数据结构、类型,还是参数数量,通常都不复杂。然而,生产环境中的 API 往往并非如此简单。比如,支付 API 不仅参数众多,而且参数动态变化(例如,签名需要实时计算,LLM 该如何处理?)。在这样的情况下,LLM 能否每次都准确调用,实在令人怀疑,我对此深有体会。
第三,关于占用过多上下文空间的问题。你可能会问,MCP 怎么会占用上下文呢?不就是工具名称、描述和参数吗?
简单来说,MCP 的调用过程如下:
用户提问 + 工具列表 → LLM 返回工具调用指令 #1 → 应用根据 LLM 的指令实际调用工具 #1 → #1 的结果再传回 LLM → LLM 返回工具调用指令 #2 → 应用根据 LLM 的指令实际调用工具 #2 → #1 和 #2 的结果再传给 LLM… → LLM 返回工具调用指令 #N → 应用根据 LLM 的指令实际调用工具 #N → #1+#2+…#N 的结果再传给 LLM → LLM 返回最终答案 → 用户看到结果
如你所见,从用户提出问题到结果呈现的整个过程,都是一个标准的 LLM 处理工具调用的流程。在这个过程中,工具调用的结果是逐渐累加的,如何保证上下文空间不会被撑爆?几乎无法控制。因此,如果你开发过工具调用较多的 agent,便会发现,agent 就像个无底洞,既耗费 token,效果却日益下降。
这就是 MCP 的三大缺陷,这些问题的根源何在?只有明确了“病灶”,才能进行优化和迭代。
本质上,LLM 在训练时,API 调用的训练数据可能不够丰富。也就是说,由于 LLM 未能接触到足够多复杂的 API,遇到复杂 API 时便容易出错,结果是选择不准确、设置不当,令人苦恼。那么,如何解决呢?微调显然是一个选项,但为了调整少数 API,是否划算?
至于上下文空间的占用,似乎也没有良策,因为不传递数据给 LLM,它又如何做出决策呢?
在 MCP 光辉的外表下,实际上隐藏着许多问题…
转机很快出现,大家发现:
- 虽然 LLM 调用工具的能力有限,但其编写代码的能力却非常出色,只需提供文档,便能生成令人满意的代码,并且能够理清复杂的业务逻辑。这是因为 LLM 在训练时接触了大量的代码。
- 基于第一点,为什么要让数据在 MCP 和 LLM 之间反复传递?为何要让 LLM 面对多个工具?可以让 LLM 根据多个工具的文档编写一段脚本,将其串联起来执行复杂逻辑,只返回最终结果给 LLM,这样的方式会更为高效和精确。
因此,一些新观念开始浮现,比如 OpenAI 的代码解释器模式或 Cloudflare 的 AI Workers 等,其核心思想在于:让 LLM 专注于其擅长的领域,同时让代码处理其专业的任务。下面的图清晰地展示了这一点:
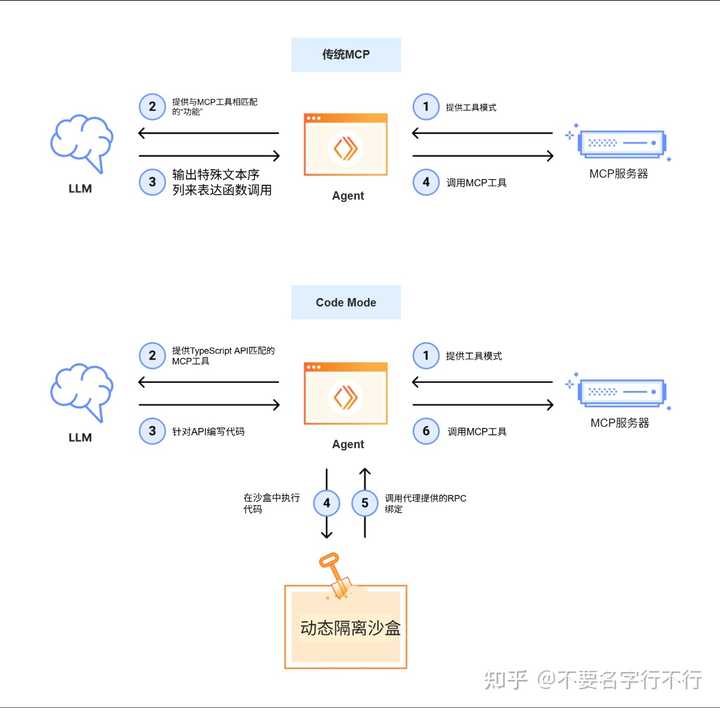
也许你看到这个图会不以为然:这有什么意义?将多个 MCP 合并成一个 MCP 就能解决问题吗?这无非是更贴近业务的封装。但此图的核心在于:这一封装过程不应由人来完成,而应由 LLM 自己实现。
此时,许多人误解了 MCP,认为它已经过时、无用,甚至要走向灭亡。其实客观地说,所有事情都要看具体场景。如果你的 agent 只是处理一些相对简单的业务逻辑,使用复杂的流程有什么意义?这不是杀鸡用牛刀吗?直接用 MCP 更为方便;但当场景日益复杂,无法承受时,确实需要重新审视 agent 和 MCP 的关系。
一切都已如愿?问题真的解决了吗?显然,这种方式也存在问题。例如,如何确保 LLM 每次编写的代码都是正确的?如果不对,反复调整是否也在浪费 token?如果一直无法正确编写呢?
该如何应对?可以考虑以下两种方案:
- 让 LLM 在有约束的条件下编写代码,所谓约束就是提供足够的信息,例如文档。
- 干脆让 LLM 直接调用现成的代码,现成的代码可以是人提供的,也可以是 agent 在历史过程中积累的(只有有效的才保留)。
如果你已经读到这里,应该已经理解了 Skills 的形成过程。Skills 的诞生本质上是为了应对工具调用过程中的各种挑战。如果没有 MCP 的缺陷,谁又会去开发新的“技能”呢?
总结一下,梳理 AI 工程化从“工具调用”到“能力封装”的思维转变路线:
- 问题暴露(MCP 的瓶颈):直接工具调用导致 上下文窗口被工具定义和中间结果填满,效率低下,成本高昂,且 LLM 在处理复杂参数和流程时容易出错。
- 新的发现(代码模式的兴起):发现 LLM更擅长编写代码 而非直接调用工具。因此,思路转变为:让 LLM 生成一段代码(脚本),在安全的环境中一次性执行所有必要操作,避免中间数据在 LLM 上下文中的频繁传递,仅返回最终结果,从而实现效率的提升和 token 的节约。
- 最佳实践(技能的封装):意识到许多任务可以复用。与其每次让 LLM“临场发挥”编写相似代码,不如 将验证过的、高效的代码和对应的操作指南预先封装成包含清晰自然语言说明、输入输出规范以及可执行代码的标准化“技能包”(Skill),LLM 只需根据任务选择合适的“技能”进行调用,从而提高可靠性和效率。
因此,演进路径为:MCP 工具调用 -> 代码执行模式 -> 可复用技能。
其核心思想是将“让 LLM 直接操作工具”转变为“让 LLM 编写程序来操作工具”,再进化为“让 LLM 调用预先设定的高级知识(Skill)以编写程序 / 调用程序,最终操作工具”。每一步的演化都是为了更高效地利用 LLM 的优势,同时规避其弱点。
在我看来,Skills 本质上就是“用自然语言编写的代码”,既然是代码,就会衍生出版本管理、测试、调试、沙箱管理等一系列新问题,Skills 也不会是终点,将继续演进。
新技术层出不穷,令人眼花缭乱,但其本质都是因“LLM 上下文的各种问题”而逐渐发展而来的,都是上下文工程下的产物。
这就是 Anthropic 的 Agent Skills 形成的全过程,理解这一演变过程后,你可能才能更好地运用 Skills,清楚哪些场景适合使用,哪些不适合。至于具体如何使用,查阅文档并进行大量实践即可。
此时,心中不禁涌现出好奇,如何让我们自己的 agent 也实现 Skills 呢…
以上,全文完。









