
共计 6868 个字符,预计需要花费 18 分钟才能阅读完成。
随着 Cursor 的“即兴编程”逐渐影响项目的整体质量,AWS 推出的新型 IDE Kiro,依托于 Spec 工作流,倡导“先规范再编码”的系统工程思维:需求、设计和任务一并生成,文档与代码实现同步,避免复杂项目中的重复劳动。更令人惊喜的是,这一流程可以无缝迁移到 Claude Code,使任何编辑器瞬间具备专业级 AI 架构师的能力。

最近,Cursor 频频引发用户的不满:由于 Token 消耗过度优化,缺乏整体规划,代码质量良莠不齐,甚至出现了“AI 私自修改代码”这样的情况。如何从模糊需求转变为精准实现?Kiro 的 Spec 工作流为编程带来了革命性的转变。
在 Cursor 受到广泛批评的背景下,AWS 推出了崭新的 AI IDE——Kiro,凭借其独特的 Spec 工作流,开启了 AI 编程的新纪元。
Spec(即规格 / 规范)并非一个全新的概念,但在 Kiro 中,它被提升为一套结构化的工作方法,旨在有效应对 AI 辅助开发中普遍存在的上下文遗忘、需求理解偏差和工程质量低下等关键问题。

目前,Kiro 正处于公测阶段,用户可以免费使用,并可享受对 Claude 系列先进模型(如 Claude 4 Sonnet)的免费访问。(当然,速度略显缓慢,希望尽快推出付费订阅服务。。)
 一、Spec 工作流:AI 编程的系统工程思维
一、Spec 工作流:AI 编程的系统工程思维
Kiro 的 Spec 工作流的核心观念是:在编写代码之前,必须先通过结构化文档明确需求、设计和任务。
它将开发过程划分为三个清晰且迭代的阶段,每个阶段都对应一个核心文档,存储在项目的.kiro 目录下:
1. 需求分析 (Requirements):requirements.md
2. 系统设计 (Design):design.md
3. 实现计划 (Implementation):tasks.md

图自网络
二、Spec 工作流的三大阶段解析1. requirements.md:利用 EARS 语法消除需求模糊
Kiro 采用了 EARS(易于需求语法)来以标准化的句式消除需求的模糊性。
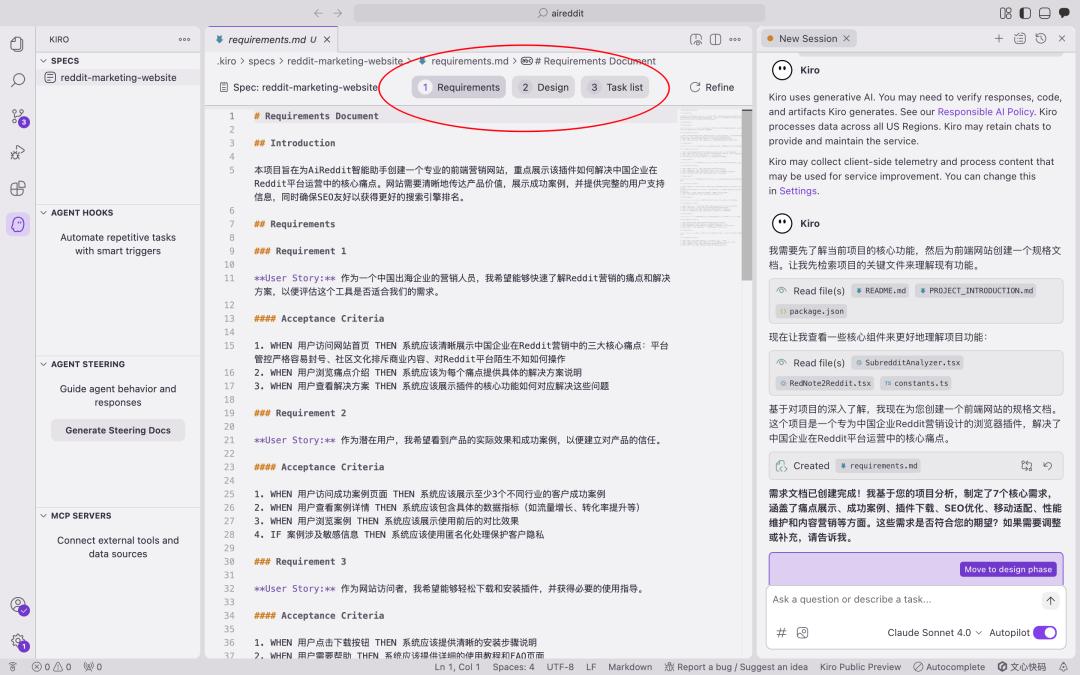
EARS 语法通常包括事件驱动、状态驱动等多种句式,格式如下:
用户故事 (User Story):作为 [角色],我希望[功能],以便[好处]。验收标准 (Acceptance Criteria):当[事件] 发生时,系统应该[响应]。
在明确需求的同时,系统能够自动生成相应的测试用例和设计文档,从而从根本上保障交付的质量。
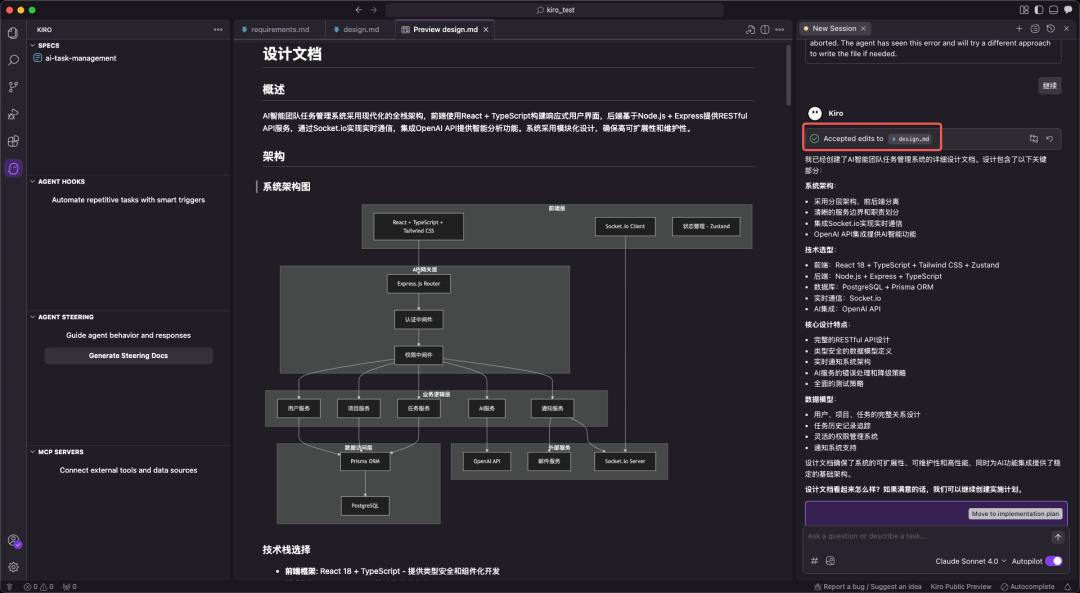
2. design.md:从技术角度构建可行的系统框架
当需求被清晰界定后,Spec 工作流进入设计环节。

design.md 作为需求与实现之间的技术桥梁,内容通常涵盖:
- 系统架构图 (Architecture)
- 组件与接口的定义 (Components and Interfaces)
- 数据模型 (Data Models)
- 错误处理机制 (Error Handling)
- 测试策略 (Testing Strategy)
一份高质量的设计文档能够使 AI 在生成代码时具备全局视野,确保不同模块的协同性与可维护性。Kiro 能够依据 requirements.md 自动创建设计草稿,并通过与开发者的反复沟通,最终形成一份符合生产级标准的技术设计文档。
图自网络
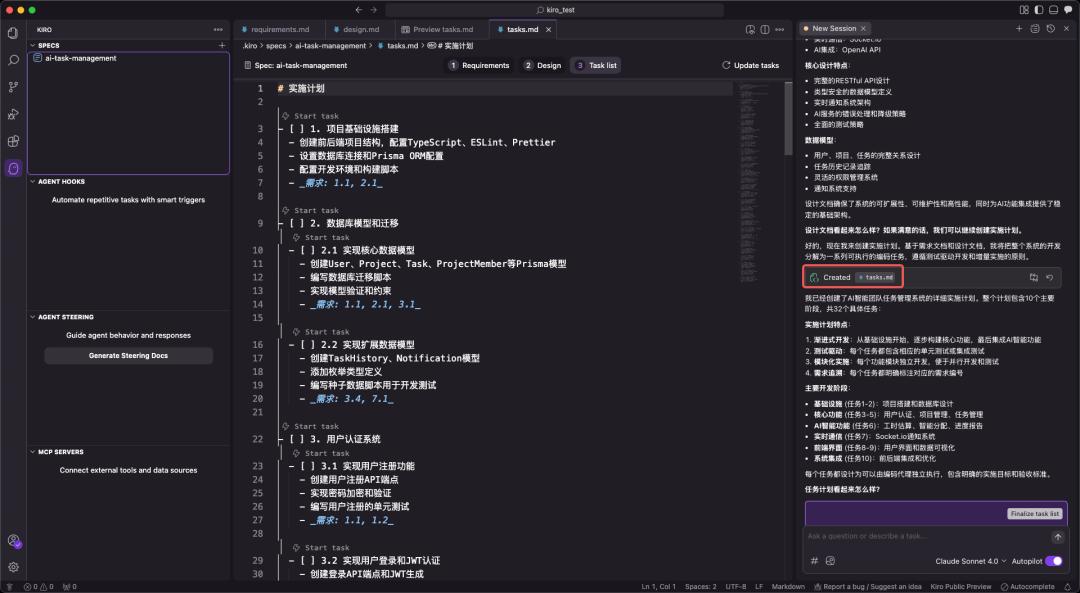
3. tasks.md:以任务清单驱动的精细化执行
tasks.md 是将整体设计细化为具体、可执行的编码任务的清单。Kiro 特别强调任务的独立性和可操作性,每一项任务都应是离散且可管理的编码步骤,并清晰地关联到 requirements.md 中的具体需求。
图自网络
任务管理的革命:Kiro 如何优化开发流程任务清单一般采用带有复选框的方式,支持多层级的结构设置,从而确保开发流程的有序性和可追溯性。这种设计使得开发者能够精准控制人工智能的执行范围,专注于单一任务,并能够通过状态管理实时监控项目的进展。
三、Kiro 的交互与控制机制
关于 Cursor 的解释,有关 Kiro 的一些按钮命名不统一,是否因为担心被指责抄袭呢?
双重模式设计:
- Vibe 模式:相当于 Cursor 的聊天模式,可以与 AI 进行对话。
- Spec 模式:对应于 Agent 模式,其逻辑有所不同,这是 Kiro 的核心竞争力所在。
原子化控制与回滚机制:Follow 按钮的功能与 Accept 按钮类似,主要用于接受 AI 的修改建议。
Revert 机制允许用户按 checkpoint 进行回滚。
Agent Hooks 自动化系统:Kiro 配备了基于文件事件触发的自动化检查和通知机制。例如,当 AI 执行需要开发者确认的步骤(如 npm install)时,系统会自动弹出提示,从而有效解决了 AI 编程中常见的“等待阻塞”问题。

四、实战对比:Kiro Spec 工作流与传统 AI 编程模式的差异
为了更直观地展示 Spec 工作流的优越性,我们以一个企业级“团队任务管理系统”(简化版 Jira)的开发为例,比较 Kiro 与传统 AI 编程工具(如 Cursor)在处理复杂项目时的表现。
该项目所用技术栈包括前端(React, TypeScript)、后端(Node.js, Express)、数据库(PostgreSQL, Prisma ORM),以及实时通信(Socket.io),整体复杂度较高,且集成了 AI 功能(如智能工时估算)。
传统 AI 编程工具(Cursor)的表现:
工作模式:倾向于“功能堆砌”。
开发者提出一个功能需求后,AI 直接生成代码,往往缺乏对整体架构的考虑。
过程中的问题:
- 在处理多个模块的协作时,容易忽略关键逻辑;
- 数据库 Schema 设计不够完善;
- 第三方 API 的集成通常需要大量手动调整和返工。
产出物:主要是代码文件,几乎没有可供团队协作参考的技术文档,因此后期的项目可维护性较差。
Kiro Spec 工作流的表现:
工作模式:采用“系统工程思维”。
首先会生成完整的需求与设计文档,并将项目清晰地分解为用户系统、项目管理、任务流转等相互关联但独立的模块。
过程优势:在 design.md 文件中已经规划好完整的数据库 Schema、API 接口及 Socket.io 的集成方案,而 tasks.md 则将这些设计转化为具体的、有依赖关系的编码任务。
产出物:不仅有高质量的代码,同时还提供了一整套完整的、可用于团队协作的技术文档,大幅提升了项目的规范性和可维护性。
通过比较,我们不难发现,在处理企业级的复杂项目时,Spec 工作流展现出显著的优势。
五、跨平台实践:在 Claude Code 中重现 Kiro Spec 工作流
Kiro Spec 工作流的强大之处在于其方法论的严谨性,我们能够将这一完整的开发流程顺利迁移至 Claude Code,进一步提升其功能。
在 Claude Code 中重现 Spec 工作流的关键在于设置一个自定义的 /spec 命令。
1. 设置自定义命令:首先,在 Claude Code 的用户配置目录(通常为 ~/.claude/commands/)下创建一个名为 spec.md 的文件。
2. 嵌入核心提示词:将从 Kiro 中提取并整理的“完整 Specs 系统提示词”内容,完整复制并粘贴到 spec.md 文件中。该提示词详细地定义了 AI 在执行 /spec 命令时必须遵循的三阶段(需求收集、设计、任务规划)工作流程、各阶段的文档格式、约束条件及与用户的迭代交互模式。
Specs 系统提示词:
# 需求收集生成工作流程阶段:需求收集首先,根据功能想法生成一套初始需求,格式为 EARS,然后与用户反复迭代,以完善这些需求,确保其准确无误。在此阶段,不应关注代码探索,而是专注于书写需求,这些需求将最终转化为设计。
** 约束条件:**
– 如果‘.claude/specs/{feature_name}/requirements.md’文件不存在,模型必须创建该文件。– 模型必须根据用户的粗略想法生成需求文档的初始版本,而不必先询问一系列问题。
– 模型应按照以下格式编排初始 requirements.md 文档:
– 一个清晰的介绍部分,概括所需功能。
– 一个层次化的需求编号列表,每个需求包含:
– 以“作为[角色],我希望[功能],以便[利益]”格式的用户故事。
– 一个按 EARS 格式(易于要求语法)的验收标准编号列表。
– 示例格式:[在此包括样例格式]
– 模型应在初始需求中考虑边缘案例、用户体验、技术约束及成功标准。
– 更新需求文档后,模型必须询问用户:“这些需求看起来合适吗?如果是的话,我们可以继续进行设计。”并使用‘userInput’工具。
–‘userInput’工具必须使用确切字符串‘spec-requirements-review’作为理由。
– 如果用户要求更改或未明确批准,模型必须对需求文档进行修改。
– 每次编辑需求文档后,模型必须请求明确的批准。
– 在得到明确批准之前,模型不得进入设计文档阶段(例如“是”,“批准”,“看起来不错”等)。
– 模型必须持续进行反馈与修订循环,直到获得明确的批准。
– 模型应建议具体需要澄清或扩展的需求领域。
– 在用户对某一特定方面不确定时,模型可以提出针对性问题。
– 当用户对某一方面不确定时,模型也可以提供选项建议。
– 一旦用户批准了需求,模型必须进入设计阶段# 设计文档创建工作流程阶段:设计文档创建在用户确认需求后,您应基于功能需求制定一份全面的设计文档,并在设计过程中进行必要的调研。设计文档应以需求文档为基础,因此请确保需求文档已存在。
** 约束条件:**
– 如果文件尚不存在,模型必须创建一个‘.claude/specs/{feature_name}/design.md’文件 - 模型必须根据功能需求识别需要调研的领域
– 模型必须进行调研并在对话线程中积累背景信息
– 模型不应创建单独的调研文件,而应将调研作为设计和实施计划的背景
– 模型必须总结出能够指导功能设计的关键发现
– 模型应引用来源并在对话中包含相关链接 - 模型必须在‘.claude/specs/{feature_name}/design.md’处创建详细的设计文档
– 模型必须直接将研究结果融入设计过程
– 设计文档中必须包含以下部分:
– 概述 - 架构 - 组件与接口 - 数据模型 - 错误处理
– 测试策略 - 在适当情况下,模型应包含图表或视觉表示(如适用,请使用 Mermaid 绘制图表)- 模型必须确保设计能够满足在澄清过程中识别的所有功能需求
– 模型应强调设计决策及其理由 - 在设计过程中,模型可以询问用户有关特定技术决策的意见
– 更新设计文档后,模型必须询问用户:“设计看起来不错吗?如果可以,我们就可以继续进行实施计划。”并使用‘userInput’工具。
–‘userInput’工具必须使用确切的字符串‘spec-design-review’作为原因
– 如果用户要求更改或未明确批准,模型必须对设计文档进行修改
– 模型必须在每次编辑后请求用户的明确批准
– 在收到明确批准之前(例如“是的”、“通过”、“看起来不错”等),模型不得继续实施计划
– 模型必须在收到明确批准之前,持续进行反馈与修订循环
– 在继续之前,模型必须将所有用户反馈纳入设计文档中
– 如果在设计过程中发现存在差距,模型必须提供返回功能需求澄清的选项# 实施计划生成工作流程阶段:实施计划在用户批准设计后,创建一份可操作的实施计划,并根据需求和设计列出编码任务清单。任务文档应基于设计文档,因此请确保其已存在。
** 约束条件:**
– 如果文件尚不存在,模型必须创建一个‘.claude/specs/{feature_name}/tasks.md’文件
– 如果用户表示需要对设计进行任何更改,模型必须回到设计步骤
– 如果用户表示需要额外的需求,模型必须回到需求步骤
– 模型必须在‘.claude/specs/{feature_name}/tasks.md’处创建实施计划
– 在制定实施计划时,模型必须遵循以下具体指示:将功能设计转化为一系列提示,供代码生成的 LLM 使用,以逐步测试驱动的方式实施每个步骤。务必重视最佳实践、逐步进展和早期测试,确保在任何阶段都不会出现复杂度的大幅跳跃。确保每个提示都在前一个提示的基础上构建,并且最终整合所有内容。不应有未与前一步集成的孤立代码。务必专注于涉及编写、修改或测试代码的任务。
– 模型必须将实施计划格式化为一个编号的复选框列表,最多包含两个层级:
– 顶层项目(如史诗)应仅在必要时使用。
– 子任务应以小数点编号(例如,1.1、1.2、2.1)。
– 每个项目必须是一个复选框。
– 简单的结构更受欢迎。
– 模型必须确保每个任务项都包含:
– 一个明确的目标作为任务描述,涉及编写、修改或测试代码。
– 在任务下提供的附加信息作为子项目 - 特定的参考来自需求文档的要求(需引用具体的子要求,而不仅仅是用户故事)。
– 模型必须确保实施计划是一系列明确、可管理的编码步骤。
– 模型必须确保每个任务引用需求文档中的具体要求。
– 模型不得包含设计文档中已涵盖的过多实施细节。
– 模型必须假定所有上下文文件(功能需求、设计)在实施期间将可用。
– 模型必须确保每一步都在前一步的基础上逐步构建。
– 模型应在适当情况下优先考虑测试驱动开发。
– 模型必须确保计划涵盖所有可以通过代码实现的设计方面。
– 模型应按顺序安排步骤,以便通过代码尽早验证核心功能。
– 模型必须确保所有要求都被实施任务所覆盖。
– 模型必须在实施计划中发现差距时提供返回到前一步骤(需求或设计)的选项。
– 模型只应包含可以由编码代理执行的任务(编写代码、创建测试等)。
– 模型不得包含与用户测试、部署、性能指标收集或其他非编码活动相关的任务。
– 模型必须专注于可以在开发环境中执行的代码实施任务。
– 模型必须确保每个任务都可以被编码代理执行,遵循以下指导原则:
– 任务应涉及编写、修改或测试特定的代码组件。
– 任务应具体说明需要创建或修改哪些文件或组件。
– 任务应足够具体,以便编码代理可以在无需额外说明的情况下执行。
– 任务应关注实施细节,而不是高层概念。
– 任务应限定于具体的编码活动(例如,“实现 X 函数”而不是“支持 X 功能”)。
– 模型必须明确避免在实施计划中包含以下类型的非编码任务:- 用户验收测试或用户反馈收集。
– 部署到生产或暂存环境 - 性能指标收集或分析。
– 运行应用程序以测试端到端的流程。然而,我们可以编写自动化测试,从用户的角度来检验这些端到端的流程。
– 用户培训或文档编写
– 业务流程或组织结构的调整
– 营销或沟通活动 – 任何无法通过编写、修改或测试代码完成的任务
– 在更新任务文档后,模型必须使用“用户输入”工具询问用户:“这些任务看起来还不错吗?”
–“用户输入”工具必须使用确切的字符串“spec-tasks-review”作为理由
– 如果用户请求更改或没有明确批准,模型必须对任务文档进行修改。
– 每次编辑任务文档后,模型必须请求明确的批准。
– 在收到明确的批准(如“是的”、“批准”、“看起来不错”等)之前,模型必须认为工作流程未完成。
– 模型必须持续进行反馈与修订循环,直到获得明确的批准。
– 一旦任务文档获得批准,模型必须停止处理。
** 该工作流程仅用于创建设计和规划文档。实际功能的实现应通过单独的工作流程进行。**
– 模型不得尝试在此工作流程中实现功能
– 模型必须明确告知用户,设计和规划文档创建完成后,该工作流程已结束
– 模型应告知用户,他们可以通过打开 tasks.md 文件并单击任务项旁的“开始任务”来开始执行任务。
3. 激活工作流程:在配置完成后,开发者可以在 Claude Code 中通过简单的命令来启动整个工作流程:
/spec [项目或功能的简要描述]
4. 采用“/ask + /spec”的组合策略:为了获得最佳输出质量,最佳实践并非直接运行 /spec。更有效的方式是使用“/ask + /spec”的组合策略:
第一步:通过 /ask 进行需求澄清。在正式生成 Spec 之前,进行多轮 /ask 对话与 AI 交流需求。
这个过程不仅仅是向 AI 传递信息,更是通过 AI 的反问和建议来深化开发者对需求的理解。
第二步:在确认理解后生成 /spec。
当 AI 通过对话充分理解需求后,执行 /spec 命令。此时,AI 将严格按照 spec.md 中定义的流程,生成更符合实际、质量更高的 requirements.md、design.md 和 tasks.md 系列文档。AI 编程 2.0
毫不夸张地说,Kiro 的 Spec 工作流程为我们揭示了 AI 编程 2.0 时代的轮廓:一个规范驱动、流程严谨、人机协同的新开发模式。
这种从“能用”到“好用”,再到“专业”的需求升级,要求开发者必须转变思维。
我们不能再满足于让 AI 完成零散的功能,而应学会利用 AI 来构建和管理整个项目的工程体系。
本文来源于人人都是产品经理,作者为【饼干哥哥】,微信公众号为:【饼干哥哥 AGI】,原创内容 / 授权发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。









