共计 6577 个字符,预计需要花费 17 分钟才能阅读完成。
Anthropic 最近推出了全新的 Claude Skills 功能,旨在赋予通用人工智能代理(Agent)更为专业的领域能力。用户能够通过创建含有 SKILL.md 文件的技能文件夹,将可执行脚本、模板和资源注入 Claude,从而实现 Excel 数据处理、PPT 制作等特定任务的自动化。
Claude Skills 的推出,正是为了让用户 能够将时间投入到更值得思考的问题上。
但这真的可行吗?
我自己常常需要处理编程技术文档。
每当新项目启动时,我都得重新教 Claude 如何完成工作,真是令人厌烦。
可惜没有一个工具能够记住我的编辑习惯,让对话能够从有状态的地方开始,而不是每次都从头开始……
这真是多么令人期待啊!
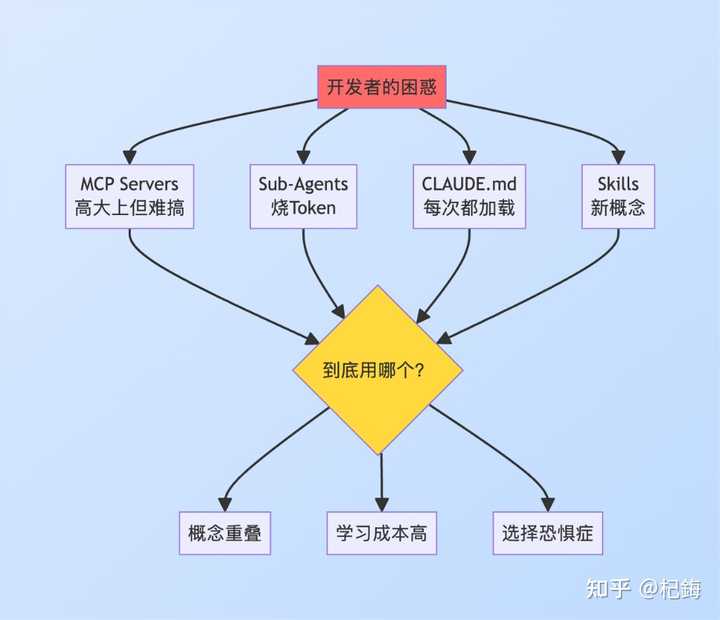
我只是对目前的人工智能工具感到失望,它们存在 三大主要问题:
- 工具繁多却无实际用处:MCP Servers、Sub-Agents、CLAUDE.md、Skills……听起来名字都很高大上,但实际上却让人搞不清楚各自的功能
- AI 无法全自动化运行:大型语言模型执行任务的成功率仅为 75-85%,每十次任务中就有两三次需要人工干预以进行反馈和修正
- 缺乏标准化就像是无序:还记得当年的 Alexa Skills 吗?曾经火爆一时,现在 95% 都完全无人问津了
这篇文章旨在记录 Claude Skills 的实际情况,探讨其是否值得投入精力,以及最重要的——如何利用不太可靠的 AI 去完成靠谱的工作。
经过一番尝试,Claude Skills 似乎是在推动提示工程的工业化进程。
如今的人工智能工具市场,形容为 ” 混乱不堪 ” 一点也不为过。
面对四种工具,选择困难症真是让人感到无从下手!
MCP Servers(模型上下文协议):
- 简而言之,它是一个协议层面的能力扩展
- 特点:有官方规范,跨平台兼容,听上去相当强大
- 问题:需要独立部署,学习曲线陡峭
Sub-Agents(子智能体):
- 拥有独立的上下文能力
- 优点:任务隔离性强
- 缺点:上下文重复浪费,社区反馈额外消耗 30-50% 的 tokens
CLAUDE.md(项目配置文件):
- 每次对话都需要完整加载的指导文档
- 问题:上下文全量消耗 100%,长对话的成本极高
Skills(技能集):
- 按需加载的行为模式库
- 据说能节省 80% 的上下文消耗
但是看起来这不过是一堆提示注入,Claude Code 里已经有 CLAUDE.md 的存在。
那么真的就不需要使用 Skills 吗?
老实说,第一次接触这些概念时,我也是一脸懵懂。
日常使用 Claude 总是浪费时间,每次都需要定向 5 - 7 分钟,同时还会造成上下文的浪费,比如每个项目消耗 300-500 tokens,更糟糕的是 每次都要重新解释一遍,真是累人啊!
每次重复的定向,都在耗费你宝贵的 ” 脑力燃料 ”。当你把精力用来向 AI 解释 ” 如何编辑 ” 时,自然就没多少力气留给 ” 编辑什么 ” 的思考了。
Skills 的理念就是将 ” 如何做 ” 的部分从你的脑海中转移到外部存储,让你能够 100% 专注于核心任务。
类似场景随处可见:
- 法律文件审查(标准化的合规检查)
- 医疗记录标注(规范化的诊断术语)
- 代码审核(统一的编码规范)
- 技术文档编写(一致的风格指南)
任何涉及 ” 专业知识 + 重复流程 ” 的工作,理论上都适用 Skills。
不过需要注意的是,我所说的是 ” 理论上 ”。
在 Skills 发布后,我刚开始使用时,感觉 Claude Skills 有可能终结人类的心智劳动,但这需要以正确的方式进行,毕竟要减少重复的 ” 开始 ”,专注于 ” 执行 ”。
因为任何技能的任何策略都能够互相基准化,最终形成一个 共享的通用技能库。
然而在实际使用中,我发现 Skills 本质上只不过是只读的 md 文件,维护起来比直接编写提示还要麻烦。
Claude Skills 本质上就是提示、只读的 md 指南和预设系统提示词的结合体。
它是一个 可复用的行为模式库,通过按需加载来节省上下文的使用。
实现这一点需要一个 YAML 配置文件。
技能标准结构:
- YAML 格式:机器可解析,支持版本控制
- Markdown 内容:人类可读
- 触发词优化:利用 NLP 语义匹配(BERT embeddings)
与 CLAUDE.md 不同的是,CLAUDE.md 每次都会读取,消耗上下文,而 Skills 是按需读取,从而节省上下文。
但这种上下文优化真的能节省 80% 吗?
我自己进行了一些测试,场景如下:
- 配置文件大小:1000 tokens
- 对话轮数:10 轮
- 任务:论文编辑
CLAUDE.md 模式:
- 每轮都加载:1000 tokens × 10 轮 = 10,000 tokens
- 成本:10K × $0.003/1K = $0.030/ 对话
Skills 模式:
- 首次触发:200 tokens(部分加载)
- 后续轮次:大部分不再触发
- 估算总计:2,000 tokens
- 成本:2K × $0.003/1K = $0.006/ 对话
节省效果:
- Token 节省:80%
- 成本降低:80%
- 响应速度:提升 15-20%(上下文处理时间减少)
这确实是可行的……
不过感觉就像是缓存机制,并不是所有内容都能得到节省。
只是重复的 Tokens 不被计算而已……
企业级规模影响(假设):
- 用户数:1000
- 月均对话:100 次 / 用户
- 总对话:100,000 次 / 月
| 模式 | 月度成本 | 年度成本 |
|---|---|---|
| CLAUDE.md | $3,000 | $36,000 |
| Skills | $600 | $7,200 |
| 节省 | $2,400 | $28,800 |
对于大规模应用而言,Skills 的上下文优化能够节省 近三万美元的年度成本。
这笔账算下来,还是相当划算的。
此外,还可以通过按需加载来实现
懒加载设计:
技能按需加载与混合架构的深度解析
# 技能管理器示例
class SkillManager:
def __init__(self):
self.skill_registry = {} # 技能登记表
self.cache = LRUCache(maxsize=10) # 最近最少使用缓存
def load_skill(self, trigger_keyword, context):
"""动态加载技能"""
# 1. 检查缓存内容
if trigger_keyword in self.cache:
return self.cache[trigger_keyword]
# 2. 在注册表中查找技能
if trigger_keyword in self.skill_registry:
skill = self.skill_registry[trigger_keyword]
# 3. 加载相关部分(而非整个文件)# 这是重点:仅加载必要的 200 tokens,而不是完整的 1000 tokens
relevant_section = skill.get_section(context)
# 4. 更新缓存信息
self.cache[trigger_keyword] = relevant_section
return relevant_section # 仅 200 tokens 对比 1000 tokens
return None| 策略 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| LRU(最近最少使用) | 实现简单易行 | 忽视访问频率 | 适合均匀访问 |
| LFU(最不常用) | 考虑使用频率 | 存在冷启动问题 | 适用于有明显热点的场景 |
在技能管理中,采用 LRU 策略,实现了简单性与效果的平衡。
然而,不应期望 LLM 能够稳定地执行确定性步骤。
可以利用 LLM 生成命令式的程序来管理工作流程,并在必要时插入 LLM 处理那些只有它能完成的任务。
混合架构示例(针对论文编辑的实施方案):
# 命令式框架(确保确定性)def paper_editing_workflow(file_path):
"""论文编辑的混合架构实现"""
# ===== 确定性层 =====
# 步骤 1: 读取文件(100% 可靠)with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 步骤 2: 提取元数据(使用正则表达式,确保确定性)metadata = extract_metadata(text)
title = metadata['title']
authors = metadata['authors']
# 步骤 3: 验证结构(规则引擎,确保确定性)structure_check = validate_structure(text)
if not structure_check['has_abstract']:
log_error("缺少摘要部分")
# ===== LLM 层(进行语义处理)=====
# 步骤 4: 内容总结(此任务只有 LLM 能高效完成)summary = llm_client.summarize(
text=text,
max_length=200,
focus="研究贡献"
)
# 步骤 5: 语言优化(LLM 的强项所在)improved_text = llm_client.improve_clarity(
text=text,
style="academic",
preserve_terminology=True
)
# ===== 确定性层 =====
# 步骤 6: 保存文件(100% 可靠)output_path = file_path.replace('.md', '_edited.md')
with open(output_path, 'w', encoding='utf-8') as f:
f.write(improved_text)
# 步骤 7: 记录日志(审计追踪)log_changes(
original=text,
edited=improved_text,
metadata=metadata,
summary=summary
)
return {
"status": "success",
"output_file": output_path,
"summary": summary,
"word_count": len(improved_text.split())
}这种方式的优点在于提升了可靠性和成本效率。
总之,应该明确分工,而不是单纯地推卸责任,将明确的任务交给代码,模糊的任务交给 AI。
| 维度 | 纯 LLM 方案 | 混合架构 |
|---|---|---|
| 可靠性 | 75-85% | 95-99% |
| 可测试性 | 低(黑盒) | 高(确定性部分可进行单元测试) |
| 可观测性 | 差(缺乏日志) | 优(完整的追踪能力) |
| 成本效率 | 低(全程依赖 LLM) | 高(按需使用) |
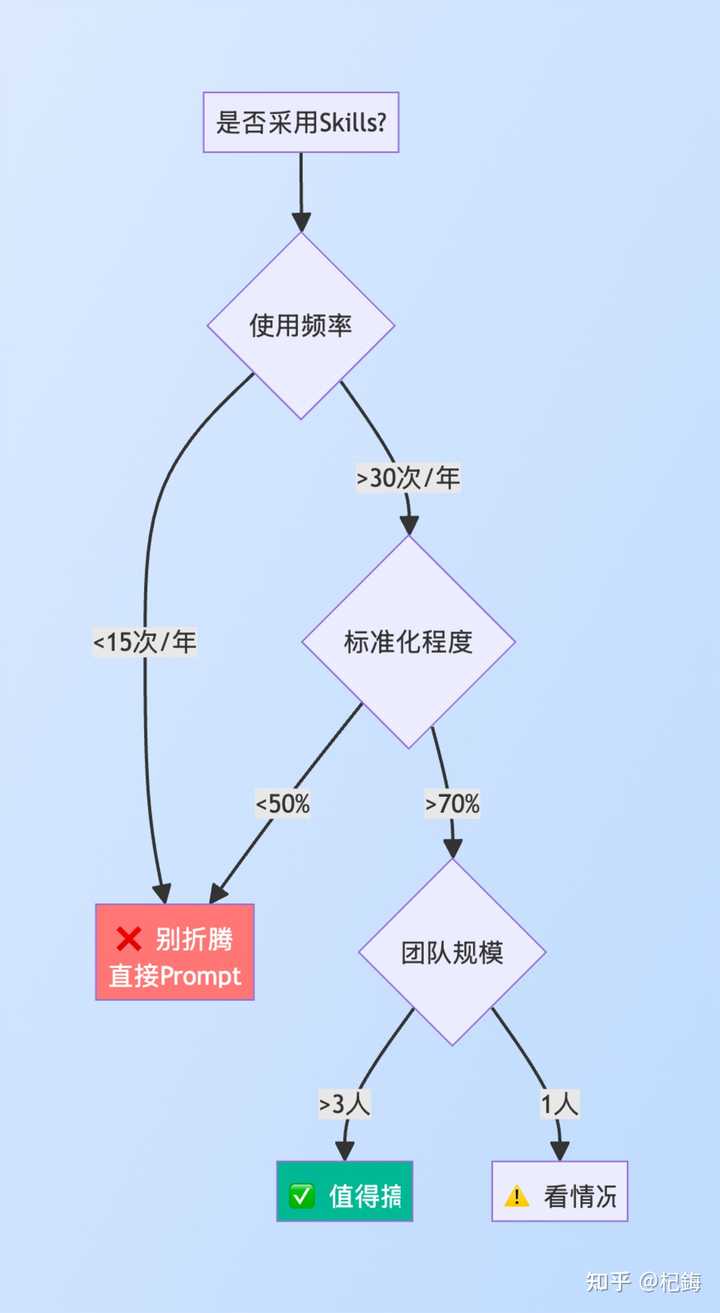
我进行了简单的计算,单次任务的 直接 Prompt 成本 如下:
- 编写
- 调试迭代:1- 2 次(2- 4 分钟)
- 总计:5- 9 分钟 / 次,平均 7 分钟
Skills 的维护成本(包含一次性与持续性):
- 初始创建:30-60 分钟
- 测试验证:20-30 分钟
- 文档编写:10-15 分钟
- 初始总计:60-105 分钟,平均 90 分钟
- 年度维护:60 分钟(包括版本更新和 bug 修复)
盈亏平衡点为技能节省 = 7 分钟(直接 Prompt)- 1 分钟(触发技能)= 6 分钟 / 次
平衡点 = 90 分钟 / 6 分钟 = 15 次
最后的投资回报率(ROI)分析如下:
| 使用次数 | 总成本(Prompt) | 总成本(Skill) | ROI | 建议 |
|---|---|---|---|---|
| 5 次 | 35 分钟 | 95 分钟 | -63% | ✗ 别折腾 |
| 15 次 | 105 分钟 | 105 分钟 | 0% | ≈ 平衡点 |
| 30 次 | 210 分钟 | 120 分钟 | +43% | ✓ 可以试试 |
| 50 次 | 350 分钟 | 140 分钟 | +60% | ✓✓ 推荐 |
需要年使用次数超过 30 次,才值得考虑采用 Skills 工具,否则只会给自己增加麻烦。
Skills 的应用场景应当是高频率的,例如每周 3 - 5 个项目,其编辑流程应相对固定、重复性高且复杂度大,例如 context-tree 项目,并且过程要清晰:架构概述→关键路径→深入细节→技术债务,最终还需具备高复用性,即一次配置可应用于多个项目。
因此,这个工具并非普遍适用,而是针对工业化和流水线式的代码工具。
然而……高质量的代码始终无法实现流水线化……
基本上,对于一次性任务(少于 5 次使用)、高度定制化(每次不同)、快速原型(时间敏感)以及探索性任务(不确定任务内容),都不必使用 Skills……
建议是,当你无法梳理清楚工作流程时,尽量避免使用任何 AI 工具……
越有用的 AI 工具越不可随意使用……
因为有幻觉效应的 AI,可以视作你加班的时间……
尽管 Skills 的承诺很大,但基于 LLM,它无法逃避LLM 本身存在的性能缺陷。
也就是说,Skills 无法解决幻觉问题。
LLM 能完全准确地遵循预设的工作流程吗?
基本上,在 Skills 执行任务的过程中,也受到 Context 的限制,步骤越多,越容易迷失。
| 工作流复杂性 | 成功率 |
|---|---|
| 简单(3 步) | 90-95% |
| 中等(5- 7 步) | 75-85% |
| 复杂(10 步以上) | 60-70% |
其根本原因在于 Transformer 架构本质上是基于概率输出,每个 token 的生成依赖于概率分布。
例如在一个包含 10 步的工作流中,如果每一步都有 5% 的错误率,最终的成功概率将降至 60%。
这并非是系统错误,而是其固有的工作机制。
与人类协作时也不可能做到绝对完美,因此,LLM 无法替代那些能够可靠执行的命令式程序。
从这一角度看,这种现象是可以理解的。
因此,我们可以反向思考:运用 LLM 去编写命令式程序来执行工作流,并在必要时在流程中加入 LLM 处理那些只有 AI 能够完成的任务。
但需要注意的是,不应再宣称可以达到 100% 的完美。
成功与失败均源于概率。
不确定性是智能的代价,也是其本质所在。
由于基于 50% 以上的成功概率,完全的 100% 是不可能实现的。
AI 应被视为一种增强工具,而非替代品。
还有多少人记得 Alexa Skills 的存在?
又有多少 Alexa Skills 依然在持续更新?
在 2016 到 2017 年间,Alexa Skills 刚刚问世,其技术基础是 Azure Logic Apps(低代码平台)结合 F#。
结果却是响应极其缓慢(延迟达 2 - 5 秒),集成过程繁琐(频繁出现集成问题),调试困难令人沮丧,最终导致所有 Skills 都被放弃维护。
为何会导致这样的失败?
主要有五个原因:
- 厂商锁定:Amazon 的专有 API 使得迁移成本随着时间的推移呈指数增长。
- 缺乏标准:没有达到 RFC 级别的规范,导致跨平台兼容性为零。
- 维护成本高于收益:API 每 3 - 6 个月更新一次,每次适配需耗费 20-40 小时,而用户量不足 100 的占比达 80%。
- 网络效应崩溃:开发者流失导致生态环境贫瘠,用户随之减少,形成负反馈螺旋。
- 平台方不重视:Amazon 逐渐将重心转向自身功能,第三方生态逐步被边缘化。
目前的状态是 Alexa Skills 的峰值数量约为 10 万个,活跃维护的仅占 <5%(大约 5000 个),95% 的 Skills 已成为废弃品。
在应用场景较为小众的情况下,Skills 也可能出现类似境地,生存变得异常艰难。
除非能够采纳开放标准,例如 Skills 能够与 MCP 协议整合并支持标准化的 Skill 描述格式(如 JSON Schema),最好还具备 跨平台兼容性(理想情况下应能在 Claude、GPT、Gemini 等平台上运行),同时使用 YAML/JSON 而非专有格式,并且需要至少三年的 API 稳定性承诺,才有望持久生存,否则将可能沦为下一个 Alexa Skills。