共计 9701 个字符,预计需要花费 25 分钟才能阅读完成。
这并非简单的损失,而是 Claude 在谋划更大的战略布局。
最初,Cursor 仅仅是一个胶水工具,而如今 Cursor2.0 已拥有了自己的编程框架。
然而,这仍无法有效解决当下的问题,因为在编程 AI 领域,最具实力的依旧是 GPT 和 Claude 这对竞争对手。
尽管 TRAE 不及 Cursor,但借助 Claude 与 GPT 的支持,它也能分得一杯羹。
这一切发生在 Claude Code 与 GPT5-Codex 尚未问世的时期。
而现阶段,随着 Claude Code 和 GPT5-Codex 的推出,AI 编程的格局已开始发生变化,原生大模型正逐步取代那些依赖外部工具的编程方式。
目前,GPT 由于财务问题尚未停止供应,只要它继续独占市场并赚取更多利润,GPT 和 Gemini 也可能会选择断供。
不仅 Claude 在积极布局,GPT 也渴望实现市场主导地位。
Claude 由于不受地域限制,更重要的是其自信心增强,已不再依赖其他编程产品进行市场推广。
依靠自身实力,Claude 可以独立发展。
AI 编程所面临的主要挑战之一便是 Tokens 成本过高。
任何形式的 AI 编程都无法逃避这个高昂的 Token 消耗。
我从 Claude 的角度进行分析,Claude 在 11 月取得了显著的进展,其 Claude Code 的 Token 成本已从 150K 直降至 2K,
这意味着成本降低了 98%!!!
前几天我看到 Anthropic 发布的新技术指南,坦白说,看完第一遍我感到无比震惊。
从 150,000 个 tokens 直接降到 2,000,这真不只是优化,而是一次彻底的颠覆!
这一下子比 Deepseek 的 3.2 降价还要夸张……
既然自己能够做到,何必再为他人奉献呢?
毫不夸张地说,这可能是我在 2025 年看到的最卓越的 AI 代理优化方案。
诚实地告诉大家,我之前参与的多工具代理项目,API 账单让我心惊胆战——一个月花费高达 $360,000,谁能承受得了?
如今,Anthropic 直接将成本降至 $4,800,节省达 98.7%。
这还不是全部,响应时间也从 20 秒缩短至 5.5 秒。
传统的方法将 AI 模型视为数据中转站,所有中间数据都需要经过上下文传递,这难免是自寻死路。
Anthropic 这次彻底将数据处理移至执行环境,模型只需专注于生成代码和获取结果,决策层与执行层完全分离。
通过分析,我总结出三个最重要的亮点:
参与过多工具代理项目的人都知道,当前的问题根本不是优化可以解决的,而是 架构性缺陷。
若想功能全面,就必须接入众多工具;若想节省 Token,就只能削减功能。
这并不是简单的两难选择,而是一种死循环。
实话实说,企业级代理若没有 50 到 200 个工具根本无法运转。
数据库查询、邮件发送、Salesforce 对接、Slack 协作、GitHub 集成,这些都是基本配置。
在我之前的项目中,光是工具接入就耗费了两个月时间。
更棘手的是调用频率。
在一个复杂的工作流程中,工具调用频率动辄在 10 到 30 次之间,链式依赖 的那种麻烦——工具 A 的输出作为工具 B 的输入,B 的输出又传递给 C,每次都要在上下文中转一圈。
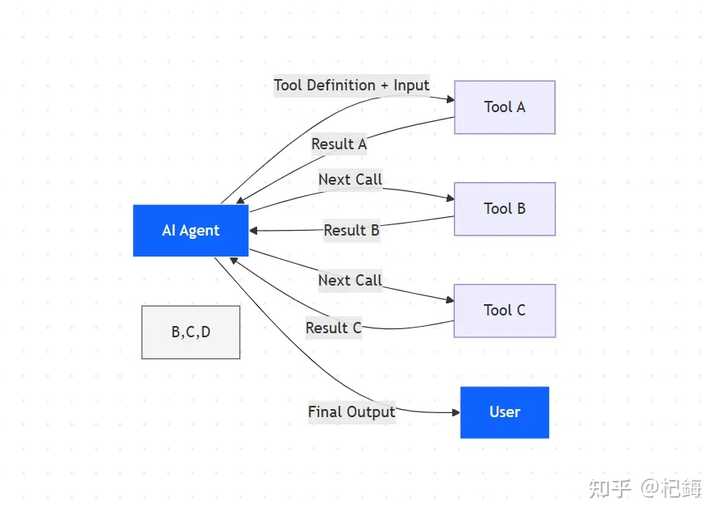
传统架构无法并行运行,只能串行执行,眼睁睁看着延迟不断增加。
调用次数与成本的关系如下:
MCP(模型上下文协议)的出现确实是一个好消息,它统一了工具接入的标准。
过去,每个服务都需要独立的 SDK、认证和数据格式,而现在可以通过 JSON Schema 来定义工具签名,使用 list_tools() API 自动发现工具,节省了不少精力。
但是!
尽管 MCP 解决了接口碎片化的问题,理论上可以接入任意数量的工具,但实际上仍然受到上下文窗口的限制。
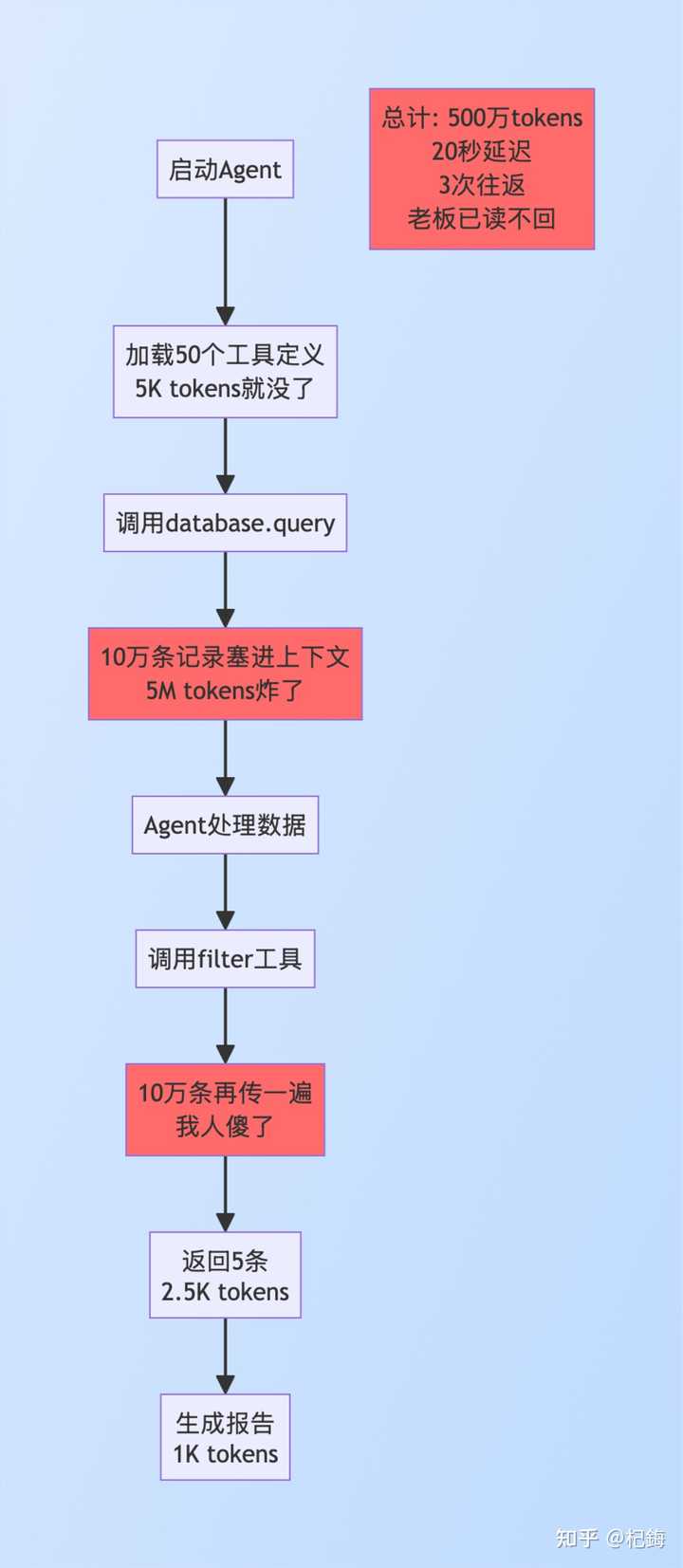
例如,要从 10 万条记录中筛选出 5 条生成报告。
传统方式的低效流程:
阶段 1 – 工具定义预加载:
阶段 2 – 数据检索(这里是重灾区):
- 代理调用 database.query()
- 100,000 条记录 → 全部进上下文
- Token 消耗:100,000 条 × 50 tokens = 5,000,000 tokens
- 延迟:序列化、传输、解析,至少需要 15 秒
- 问题:10 万条记录中 99,995 条都是无效数据,全都进了上下文
阶段 3 – 数据过滤:
- 调用 filter()工具
- 10 万条记录再次传输(没错,又传了一遍)
- 最终返回 5 条结果
阶段 4 – 生成报告:
- 最终仅传输 5 条记录
- 但前面的步骤已经耗尽资源
总账单:
- Token:5,006,000(约 500 万)
- 往返:3 次
- 延迟:20 秒
- 最搞笑的是:10 万条数据走了一圈,真正有用的只有 5 条
流程如下:
这说明了什么呢?
传统架构将 AI 模型视为数据传输的中转站,所有数据都必须经过模型这一关。
模型不仅要进行决策,还要担任数据搬运工,Token 消耗与数据量成正比,这样怎么可能不出问题呢?
工具定义的预加载是第一个大坑。代理一启动就需要将所有工具定义加载:功能描述、参数说明(类型、必填项、默认值、验证规则)、返回格式和 2 - 3 个使用示例。
若有 50 个工具,计算下来:50 × 100 tokens = 5,000 tokens 的基础开销。但规模效应带来的问题更加复杂:

如果有 200 个工具,Token 的消耗直接从 20,000 tokens 起步。
更为可笑的是工具的利用率。
统计显示,单次任务平均只用到 3 - 5 个工具,利用率仅为 2.5%。
换句话说,97.5% 的工具定义 tokens 都是多余的浪费。
为何不能按需加载呢?
因为传统架构要求预先声明所有工具,模型必须“看到”所有选项才能做出选择。
中间结果的传递:数据重复传输的潜在风险。
Salesforce 真实案例:
颠覆传统:高效工具调用新模式的全景解析
每次往返 500 毫秒,三次加起来就耗费了 1.5 秒的网络时间。
数据序列化还带来了隐性成本。
原始 1KB 数据转为 JSON 后会膨胀到 1.5-2KB,膨胀系数达到 1.5- 2 倍。
模型还需要时间去理解 JSON 的结构。
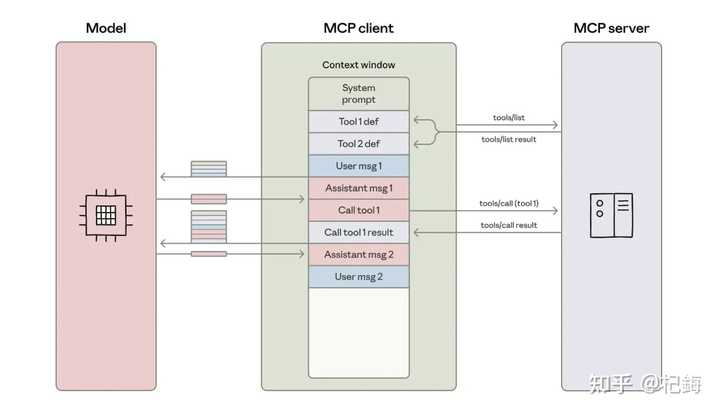
Anthropic 提出的解决方案可谓简单直接:不进行优化,直接更换架构。在这个新架构中,Agent 不再是工具的调用者,而是代码的创建者。MCP 服务器也不再是函数调用接口,而转变为代码模块。
这一核心理念虽然听上去简单,但实践起来非常复杂:模型的作用不是执行工具,而是生成执行工具的代码。
代码在独立的环境中运行,数据处理全部在该环境内部完成,模型仅需接收最终结果。
MCP 服务器重构为代码 API,完成了 从函数调用到模块导入 的关键转变。
// 传统方式(每次调用都是灾难)agent.call_tool("search", {query: "..."})
// 代码执行方式(简洁清爽)import {search} from 'mcp-server'技术实现(支持 TypeScript 和 Python 双语言)!
TypeScript 版本:
// mcp-servers/salesforce/index.ts
export class SalesforceClient {async search(params: SearchParams): Promise {
// 这里的实现全在执行环境,模型根本不知道
const results = await this.api.query(params);
return results;
}
async update(id: string, data: object): Promise {
// 所有操作都在环境内,秒啊
return await this.api.update(id, data);
}
}Python 版本:
# mcp_servers/salesforce/__init__.py
from typing import List, Dict
class SalesforceClient:
def search(self, query: str) -> List[Dict]:
"""环境内执行,不走模型上下文"""
results = self._api_call(query)
return results
def filter_high_value(self, records: List[Dict], threshold: float) -> List[Dict]:
"""原生 Python 过滤,又快又省"""
return [r for r in records if r['revenue'] > threshold]类型提示真的是好东西:IDE 能够自动补全、进行类型检查、悬停显示文档,开发体验得到了极大提升。async/await 的原生支持也使得并发性能显著提高。
懒加载机制按需加载(这一机制极大节省 Token)!
传统方式:预加载 50 个工具 = 5K tokens
代码执行:只导入 2 个工具 = 0 tokens
为何是 0?
因为导入语句并不占用模型上下文!
动态导入的实现方式:
// 运行时按需导入,想用啥导啥
const toolName = determineRequiredTool(task);
const module = await import(`mcp-servers/${toolName}`);
const tool = new module.Client();search_tools 工具发现 API(这一设计实在太聪明了)
async function search_tools(query: string): Promise {
// 轻量级元数据,每个工具
tool.tags.includes(query) ||
tool.description.includes(query)
);
// 按相关性和流行度排序
return matches.sort(byRelevance).map(t => ({
name: t.name,
summary: t.summary
}));
}元数据索引在启动时构建一次,后续查询的响应时间仅为 10 毫秒。结合倒排索引与内存缓存,性能得到了大幅提升。
实际应用场景示例:
- Agent 要 ” 发邮件 ”
- 调用
search_tools("email")→ 返回 3 个邮件工具(150 tokens) - Agent 选择 ”Gmail Sender”
import {GmailSender} from 'mcp-servers/gmail'- 只加载这个工具,其余 197 个工具完全不受影响
工具选择逻辑包括:描述匹配度、历史使用频率和上下文相关性。
Agent 的角色转变为编码者,模型的职能由 ” 执行者 ” 变为 ” 编排者 ”。它生成代码,但不执行工具调用。这就需要确保代码的质量:
- ESLint、Pylint 进行自动语法检查
- TypeScript/Python 的类型系统用于类型验证
- 代码模板库能够复用最佳实践
模板库减少了生成错误的几率。例如,数据库查询的标准模板、API 调用的重试模板,都是经过验证的。
依旧在环境内处理:数据不流出环境。
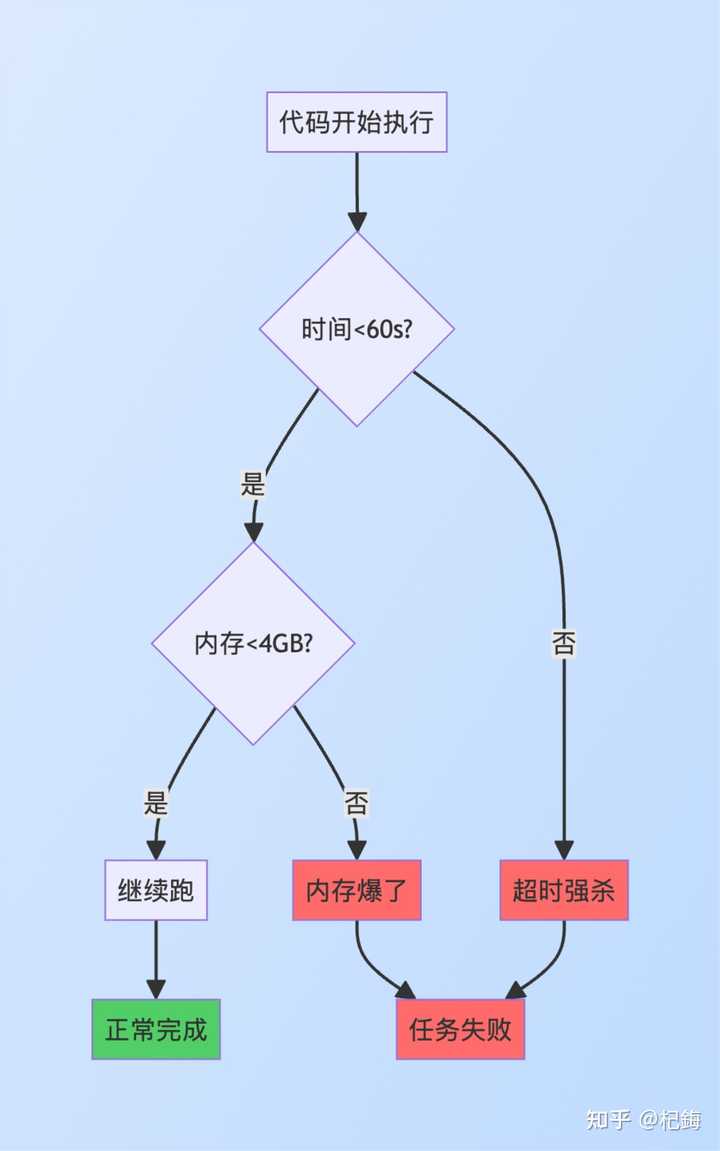
执行环境的安全隔离至关重要!
安全第一,其架构是:沙箱 + 资源限制 + 实时监控。
沙箱技术(Docker + seccomp 多层防护)
- 网络隔离:仅能访问 MCP 服务器,其他外部连接全部禁止
- 文件系统隔离 :代码库为只读,仅有
/tmp可写,防止破坏 - 进程隔离:独立容器,进程间完全隔离
资源配额(固定规则)
- CPU:2 核
- 内存:4GB
- 执行
超时会使用 SIGALRM 信号强制终止。内存泄漏则通过 cgroup 限制,使用 OOM killer 来保护宿主机。
核心技术在于数据流的重定向!
Salesforce 案例的改写版(对比太强烈了)
高效数据处理与性能优化的全新视角
数据流向示意图:
数据库 → 执行环境内存(1000 条,模型无法访问)
↓ 筛选操作
执行环境内存(50 条,模型无法访问)
↓ 聚合计算
执行环境内存(summary 对象)
↓ 返回
模型上下文(仅 summary,约 100 tokens)执行时间统计:
- 数据库查询:2 秒
- 环境内过滤:0.05 秒
- 环境内聚合:0.05 秒
- 总计:2.1 秒
Token 节省:1000 条记录未序列化,50 条未传输,只有 summary 返回。51K → 100 = 节省 99.8%。
中间数据的内存管理,100K 条记录存于环境内存,模型对此无感知。选择合适的数据结构至关重要:JavaScript 数组、Python 列表,原生性能表现最佳。
对于超大数据集,可使用 Generator 逐条处理,以避免全面加载:
function* processLargeDataset(data) {for (let item of data) {yield transformItem(item); // 逐条处理,节省内存
}
}实时监控内存使用情况:
const memUsage = process.memoryUsage();
if (memUsage.heapUsed > threshold) {// 内存即将耗尽,切换为流式处理}将 50 次调用合并为一次(这个优化效果显著)
// 传统方式:50 次工具调用 = 50 次往返 = 25 秒等待
// 使用循环一次性完成
const results = [];
for (let i = 0; i 进阶的并发版本:
// 50 个并发请求,0.5 秒完成
const results = await Promise.all(items.map(item => processItem(item))
);并发控制以防止服务器过载:
import pLimit from 'p-limit';
const limit = pLimit(10); // 最多 10 个并发请求
const results = await Promise.all(items.map(item => limit(() => processItem(item)))
);错误重试机制以增强容错能力:
async function retry(fn, times = 3) {for (let i = 0; i 效果对比:真实数据的价值
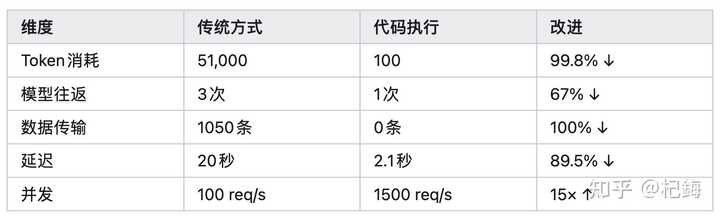
Token 节省率计算公式:
延迟改善的计算:
Claude 在这方面展现出了诸多优势!
现在自己能够解决问题,无需再依赖他人的帮助……
1. Token 效率:成本显著降低
不同规模的真实成本对比,这个表格让多少老板感到心痛!
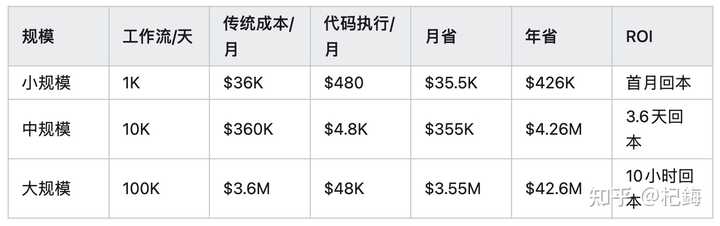
实施成本如下:
- 环境搭建:$50K(一次性费用)
- 月维护费用:$5K
中等规模的回本时间为:$50K ÷ $355K = 0.14 月 ≈ 3.6 天
三年总拥有成本对比(传统与代码执行):
传统方式:$360K × 36 = $12.96M
代码执行:$50K + ($4.8K + $5K) × 36 = $402.8K
三年总节省:$12.96M – $403K = $12.56M(节省率 96.9%)
2. 渐进式工具发掘:再也不需要预加载
search_tools 的完整实现,这个 API 设计实在巧妙!
全面提升数据处理效率的创新策略
启动时构建倒排索引,查询响应时间仅需 10 毫秒:
// 启动时构建倒排索引
const invertedIndex = new Map>();
for (const tool of allTools) {const words = [...tool.tags, ...tool.description.split(' ')];
for (const word of words) {if (!invertedIndex.has(word)) {invertedIndex.set(word, new Set());
}
invertedIndex.get(word).add(tool.name);
}
}
// 查询复杂度为 O(1),速度极快
function fastSearch(query: string): string[] {const words = query.split(' ');
let results = invertedIndex.get(words[0]) || new Set();
for (let i = 1; i wordResults.has(x)));
}
return Array.from(results);
}Token 对比(节省效果显著):
- 传统方式:预加载 200 个工具 = 20K tokens
- search_tools:返回 3 个匹配 = 150 tokens
- 动态导入:import 语句 = 0 tokens
- 总计节省:99.25%
3. 大数据处理:不再担心数据量问题
性能曲线对比显示,随着数据量增加,优势愈加明显!
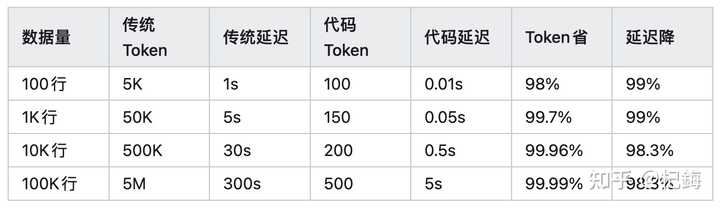
性能临界点在100 行。
对于少于 50 行的代码,使用传统方式会更简便,而在超过 100 行时,动态策略的优势显现无疑。
动态策略选择示例:
数据管道构建示例:
// 链式操作,内存峰值低
const pipeline = data
.filter(cleanData) // 数据清洗
.map(transformFormat) // 数据格式转换
.reduce(aggregateByGroup) // 数据聚合
.map(calculateMetrics); // 计算指标
// 流式处理超大数据
async function* streamProcess(dataSource) {for await (const batch of dataSource.batches(1000)) {
const processed = batch
.filter(validate)
.map(transform);
yield processed; // 逐批处理,控制内存使用
}
}处理 100K 行数据,内存峰值仅需500MB,而非全量加载的5GB。
此外,还有编程控制流的优化,循环、条件和错误处理均为原生支持,50 次调用可合并为 1 次执行,延迟降低了 25 倍;在隐私安全方面,敏感数据不会进入模型,确保符合 GDPR 和 HIPAA 标准;状态持久化和检查点机制使得长任务可以跨会话执行,3 小时的任务可分为 3 次完成;技能生态 SKILL.MD 文档化,能力可复用,团队效率提升 3 - 5 倍等诸多优势……