共计 6899 个字符,预计需要花费 18 分钟才能阅读完成。
这一问题常常浮现,而在尝试了三款 AI 后,最终却发现它们都各有千秋。
昨天,公司的首席技术官向我抛出了一个发人深省的问题:“我们究竟应该选择哪个 AI?Claude 的价格高得离谱,ChatGPT 总是不靠谱,而 Gemini 似乎也没什么特别之处?”
经过一番深入思考,我意识到,很多人在选择 AI 时,实际上就像是在抽盲盒,完全依赖运气。
作为一名在 AI 领域摸爬滚打了几年的从业者,我想说:不必再纠结于哪个是“最佳”选择了,2025 年即将进入多模型协同的新时代。
上周,我们团队进行了一次有趣的实验,针对同一个 Python 重构任务,Claude 耗时 8 分钟给出了企业级的解决方案,ChatGPT 用时 5 分钟但存在 3 个错误,而 Gemini 则在 2 分钟内提供了一个能运行的结果。
三大巨头的特点与差异
首先,分享一个有趣的现象,根据 Stack Overflow 的最新调查,84% 的开发者正在使用 AI,但仅有 3% 的人表示“高度信任”。
这些数据看似令人困惑,但回想起我每天调试 AI 生成的代码到崩溃的经历,确实如此。
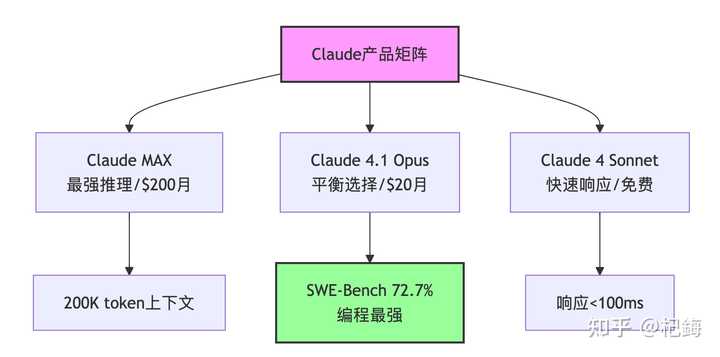
Claude:代码界的“完美主义者”
谈到 Claude,我的第一感觉是“昂贵”,第二感觉是“确实不错”。
Anthropic 这家公司非常引人注目,其创始人均为 OpenAI 的前员工,传闻是因理念不合而分道扬镳——他们希望构建更“安全”的 AI。
技术人员都知道,所谓的 Constitutional AI 并不是简单的营销术语,其背后有实实在在的技术支持。
简单来说,其训练过程可以用以下公式表示:
其中 表示监督学习的损失,
则是基于“宪法约束”的强化学习损失。简单来说,它不仅学习如何回答问题,还学习什么是不该回答的。关于这个 $lambda$ 权重系数,Anthropic 据说经过几个月的调试才找到最佳值(大约在 0.3 到 0.5 之间)。
我认为 Claude 最出色的地方在于它的 Constitutional AI,简单来说就是它具备“自我审查”的能力。
上个月,我让它协助编写一个爬虫,它竟然提醒我注意 robots.txt 和法律风险——虽然有时这样显得略烦,但至少不至于像某些 AI 那样毫无顾忌。
- 在处理 18K 行的遗留代码时,Claude 能够理解整体架构(而另外两个则完全无从下手)
- 每月费用更高的 Claude Code,帮我节省了大约 27 个小时
- 但是!它的响应速度着实较慢,大约为 78 tokens/ 秒,泡一杯咖啡回来才完成
顺便提一下,Reddit 上的 Python 社区已经炸开锅,大家都在讨论“Claude 的 Python 水平完胜 GPT”。
经过我的测试,确实在 Django 和 FastAPI 框架下,Claude 的代码质量令人印象深刻。
这背后其实涉及到位置编码的技术问题。Claude 采用的是旋转位置编码(RoPE):
这种编码方式在处理长代码文件时具有明显优势,相对位置信息保持得更加稳定。而 GPT 系列依然使用传统的正弦位置编码:
当代码超出 8K tokens 时,性能差异变得显而易见。我在处理一个 15K 行的项目时,Claude 能够准确定位函数调用关系,而 GPT- 4 则常常混淆。
ChatGPT:全能型选手
OpenAI 的动态则显得热闹非凡。
从 GPT-3.5 到如今的 GPT-5(最新讨论已经开始,关于智能水平的争议,甚至有些不如开源软件),更新速度之快让人感到钱包受压。
你知道 GPT 系列的核心原理吗?其实就是自回归语言建模,数学上并不复杂:
OpenAI 的多头注意力机制才是真正的创新所在:
其中  的缩放因子至关重要,缺少它会导致梯度爆炸。我曾尝试自行实现 Transformer,忘记添加此因子,损失直接飙升至 nan,调试了整个下午才找到问题所在。
的缩放因子至关重要,缺少它会导致梯度爆炸。我曾尝试自行实现 Transformer,忘记添加此因子,损失直接飙升至 nan,调试了整个下午才找到问题所在。
最新数据显示,ChatGPT 的周活跃用户已超过 7 亿,市场份额达到 60.5%,成为名副其实的行业领头羊。然而,你可知道吗?开发者社区已经开始“叛逃”,Cursor IDE(不支持内地使用 Claude)和 Aider 等主流工具纷纷将默认模型更改为 Claude。
真实案例:需求各异,风格迥然
ChatGPT 的强项在于其生态系统,GitHub Copilot 的用户数量高达 2000 万,其中约 130 万为付费用户。
不过说实话,GPT5 的幻觉率相当高,有评论指出其表现甚至不如 20B 的开源 OSS,部分人更是认为这款产品是“降智版”,实在令人费解。
Gemini:低调的潜力选手
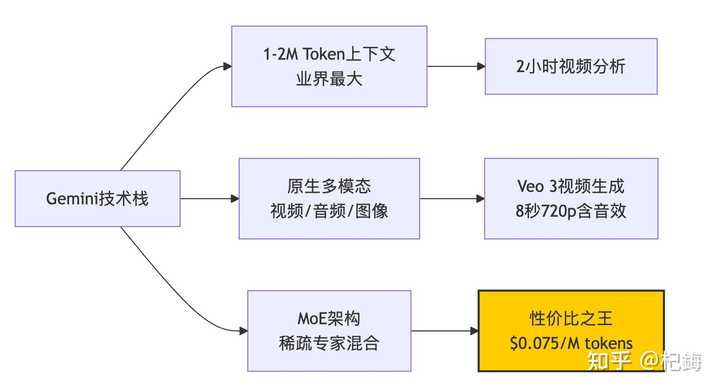
Google 的 Gemini 表现得相当低调,但其价格优势却显而易见!
Gemini Flash 每百万 token(输入)仅需 $0.10,价格比 Claude 便宜 150 倍!
在技术方面,Gemini 最为出色的是其 MoE(Mixture of Experts)架构。在每次推理中并非所有参数都被激活,而是通过门控机制选择特定的专家:
其中门控函数 $G(x) = text{softmax}(W_{gate} cdot x + b)$ 决定了激活哪些专家。这也是 Gemini 能够实现大规模和快速推理的原因——尽管模型有 1.8T 参数,但每次实际只激活大约 200B。
但这里有一个挑战,负载平衡至关重要。Google 采用了一个辅助损失函数:
表示专家 $i$ 的使用频率,
则是其容量。这个
系数一旦设置不当,某些专家可能会过载,导致性能下降。我在项目中也尝试过类似架构,这个参数调试花费了我两周的时间 …
说实话,上周我用 Gemini 分析了一个 2 小时的技术讲座视频,它竟然能准确识别出某个概念在第几分钟被提到。这种能力,当前其他两家确实无法比拟。
尽管如此,Gemini 也有其不足之处:
编程能力比较:我的实测结果
作为一名程序员,最关注的自然是代码编写能力。我进行了一项“创建俄罗斯方块游戏”的测试,结果相当有趣。
在查看结果前,首先需要理解这些模型是如何“理解”代码的。它们本质上是将代码进行 token 化,然后计算上下文的相关性:
这个前馈网络(FFN)的隐藏维度通常是模型维度的 4 倍。Claude 采用的是 8192 维,因此 FFN 为 32768 维——这就是它在理解复杂代码结构方面表现出色的原因。
基准测试成果(2025 年 1 月数据)
Claude 生成的代码提供了全面的错误处理、单元测试,甚至还包含性能优化的建议。
相较之下,ChatGPT 的代码简洁易懂,更适合教学使用。
而 Gemini… 可以说它生成的速度最快,仅需 2 分钟,尽管界面稍显简单。
不同编程语言的表现差异
Python 生态:Claude > ChatGPT > Gemini
- Claude:在 Django/FastAPI 方面表现出色
- ChatGPT:在数据科学库(如 pandas、numpy)方面更具优势
- Gemini:适合编写简单脚本
JavaScript/TypeScript:ChatGPT ≈ Claude > Gemini
这一点让我颇感意外,可能是因为 GitHub 上的 JS 项目数量最多,ChatGPT 的训练数据更为丰富。上次我编写 React 组件时,ChatGPT 提供的 hooks 用法确实更为地道。
系统编程(C++/Rust/Go):Claude >> ChatGPT > Gemini 在内存管理方面,Claude 的表现堪称降维打击。有一次我调试一个 use-after-free 的 bug,只有 Claude 能够准确指出问题的根源。
多媒体能力:各有千秋
在这一领域,Gemini 的表现突然突显出来。
图像生成比较
- ChatGPT + DALL-E 3:艺术感最为浓厚,特别适合创意设计
- Gemini + Imagen 3:更为真实,并且具备 SynthID 水印技术
人工智能工具的深度分析与使用策略
- Claude:尽管不支持图像生成,但其图像理解能力极为出色,OCR 准确率高达 95%
上个月在制作 PPT 时,发现 ChatGPT 生成的图片确实更具艺术感,而 Gemini 提供的图像则显得更为正式,适合在专业场合使用。
视频处理:Gemini 的强项
Gemini 的 Veo 3 表现卓越,能够在 2 分钟内生成带音效的 720p 视频,时长为 8 秒,已经融入 YouTube Shorts,成为内容创作者的福音。相较之下,OpenAI 的 Sora 虽然质量更高,但等待时间较长,足以让我完成一个简单版本。
成本分析:预算压力
让我们来进行一些计算,假设一个 10 人的团队,每月处理 10M 的 tokens。
首先,介绍一下 token 的计算方式,一般来说:
由于中文的复杂性,一个汉字大约相当于 1.5 到 2 个 tokens。因此,撰写中文文档的成本尤其高,我通常先使用英文提示,然后再进行翻译。
成本优化的经典公式为:
其中,Retry Rate 是关键因素。如果模型经常输出不合格的结果,需要反复尝试,则实际成本可能会成倍增加。
根据我的统计,Gemini 的重试率约为 15%,而 Claude 则为 5%。从长远来看,使用 Claude 可能更为经济。
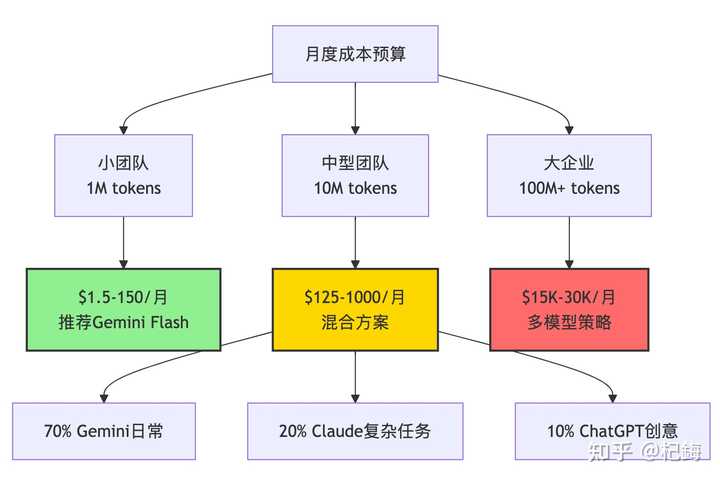
个人开发者选择:
- 预算宽裕:Claude Pro(每月 $20)+ 偶尔使用 ChatGPT
- 预算紧张:Gemini 免费版(每月 18 万次补全)
- 折中方案:ChatGPT Plus(每月 $20),兼具通用性
企业选择:有必要指出的是,43% 的企业员工使用两个以上的 AI 工具。我们的团队策略是:
- 核心开发:Claude(虽然价格较高,但值得投资)
- 日常查询:Gemini(经济实惠,处理量大)
- 创意文案:ChatGPT(无可替代)
安全性考量:不可忽视的关键
自从 o3 模型的幻觉率高达 48% 的新闻被曝光后,大家开始更加重视这个问题(GPT5 尚未正式发布,情况尚不明了)。
根据 Vectara 的测试结果:
- Gemini 2.0 Flash:幻觉率仅为 0.7%(最低)
- Claude 4 系列:约为 2 -3%(受益于 Constitutional AI)
- ChatGPT GPT-4.1:5-8%(尚可接受)
- OpenAI o3/o4:33-48%(翻车典型案例)
幻觉率的计算方法是评估模型输出的条件概率分布与真实分布之间的差异:
Claude 低幻觉率的原因在于其 RLHF 的优化目标有所不同:
其中,Constitutional Score 是关键,它会对不安全或不准确的输出进行惩罚。
我曾测试过同样的医疗问题,Claude 会说“我不是医生,建议咨询专业人士”,而其他一些模型则会编造治疗方案。
在医疗和法律等领域,还是建议使用 Claude,它的优势在于基于真实数据的训练,而 GPT 大多数情况是闭门造车。
我见过因为使用 ChatGPT 撰写合同条款而遭到法务人员严厉批评的案例。
Gemini 同样表现出色,广泛使用网络数据进行训练。
2025 年最新动态与趋势
技术更新趋势(持续关注)
- 2025 年 8 月:Claude 4.1 Opus 发布,混合推理模式正式上线
- 2025 年 3 月:Gemini 2.5 Pro 推出新“思考”功能
- 2025 年 8 月:OpenAI 将发布 GPT5 推理模型(需谨慎使用)
谈到响应速度,这其中的学问可不少。推理速度主要受到以下公式的影响:
Gemini Flash 能够达到每秒 200+ 个 tokens,秘诀在于其稀疏激活技术——实际 FLOPS 需求仅为密集模型的 1 /8。而 Claude 的深度思考模式则会增加额外的“思考 tokens”:
这个“思考”部分可能是输出的 3 到 5 倍,因此看起来速度较慢,但准确性却显著提升。
我曾经测试过一个算法题,启用思考模式后,错误率从 12% 降至 2%。
开发者生态的变化
有一个有趣的趋势是,主流开发工具正在逐步“去 OpenAI 化”。Cursor 默认使用 Claude,Continue 支持多种模型,甚至连微软自家的 VS Code 也开始支持 Gemini 了。
从信息论的角度来看,多模型策略实际上是在优化信息熵:
单一模型的输出熵是固定的,但组合多个模型可以降低整体不确定性。
这就是为什么 43% 的企业采用多模型策略——这并非盲目跟风,而是确实有效。
我认为这反映了一个事实:没有万能的 AI,只有适合特定场景的 AI。
我的使用策略(持续优化中)
经过多次实践,我目前的工作流程如下:
开发阶段的角色分配
优化 AI 工具配置,实现高效开发
场景具体选择
紧急修复缺陷 :Gemini(速度快)→ Claude(进行验证) 重构旧代码 :Claude 表现出色(它对遗留代码了如指掌)
撰写技术方案 :ChatGPT 负责起草 → Claude 进行审核 处理大型文件 :Gemini(支持 2M token 上下文) 解答算法面试题:Claude(思路清晰明了)
若干初步建议
经过一段时间的探索,我总结出几点体会:
- 不必盲目追捧基准测试:虽然 SWE-Bench 72.7% 的成绩听起来很优秀,但实际使用中可能会遇到问题
- 成本需整体考虑:Claude 虽然价格较高,但如果能够节省调试的时间,实则是划算的
- 保持怀疑态度:AI 生成的代码必须经过审核,尤其是在并发和内存管理方面
- 多模型使用已成趋势:到了 2025 年,还在纠结于单一模型,不如掌握组合使用的技巧
最后分享一个小段子:上周组里的新同事(也是动漫迷)问我“哪个 AI 最好”,我幽默地回答:“佐为就在你的棋盘上。”
言下之意是,你最强大的 AI,其实就在你的代码之中~
参考资料与工具推荐
官方文档
- Claude 官方文档
- OpenAI API 文档
- Google AI Studio(非专用地区,无法享受免费额度)
基准测试平台
- Chatbot Arena 排行榜
- SWE-Bench 官方
- Vectara 幻觉率测试
社区讨论
- r/LocalLLaMA – 模型比较探讨
- Twitter #AIEngineering – 实时信息更新