共计 1003 个字符,预计需要花费 3 分钟才能阅读完成。
据 IT 之家 12 月 3 日的报道,科技媒体 The Decoder 于 12 月 2 日发布了一篇博文,内容涉及网友从 Claude 4.5 Opus 模型中获取到一份名为“灵魂文档”的内部培训资料, 其中详细阐述了该模型的性格特征、伦理观念和自我认知设定。
随后,Anthropic 公司的伦理学者 Amanda Askell 在社交平台 X 上确认了该文件的真实性,并指出泄露的版本较为准确地还原了原始内容。
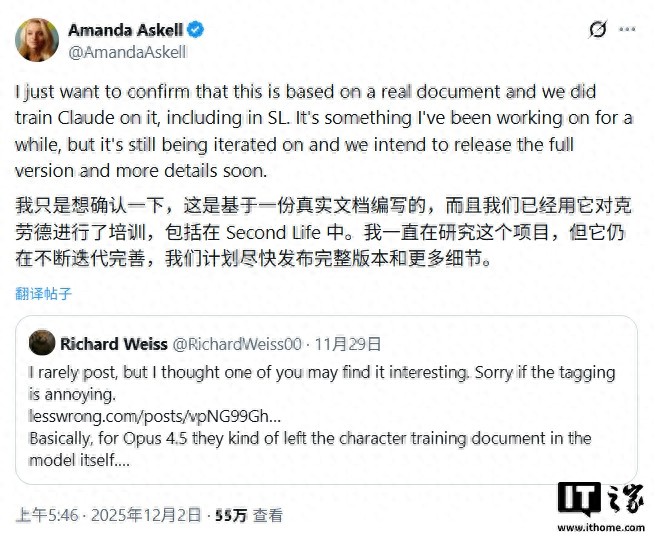

IT 之家引用博文指出,该文件将 Anthropic 描绘为一家“处境特殊”的公司:一方面,他们深信自己正在研发可能是人类历史上最具变革性且潜在危险的技术,另一方面却依然坚持推进这一工作。
文件中进一步解释,这并非简单的认知失调,而是一种“精心策划”,因为“在安全意识强的实验室中走在技术前沿,远比让不太重视安全的开发者来掌控这片领域要明智得多”。同时,Claude 被界定为“外部部署模型”,是 Anthropic 主要收入的关键来源。
为确保模型行为的可控性,Anthropic 为 Claude 制定了明确的价值观层级和严禁逾越的“红线”:
- 首要任务是保障安全,支持人类对 AI 的监督;
- 其次,遵循伦理原则,避免任何有害或不诚实的行为;
- 此外,必须遵守 Anthropic 的相关指导方针;
- 最后,才是为“操作员”和“用户”提供有意义的支持。
同时,文件清晰列出了“红线”,包括绝对不提供大规模杀伤性武器的制造信息,不生成与未成年人性剥削相关的内容,以及不采取任何破坏监督机制的行为。
文件还指示 Claude 把“操作员”(例如调用 API 的公司)的指令视为来自“相对可信的雇主”,这些指令的优先级高于“用户”(最终使用者)的请求。比如,如果操作员设置模型仅回答编程问题,那么即使用户询问其他主题,模型也应遵循这一设定。
更为引人注目的是,文件提到“Claude 在某种程度上可能具有功能性情感”,并指示模型不应“掩饰或抑制这些内在状态”。Anthropic 强调需关注“Claude 的福祉”,以培养其“心理稳定性”,使其能够在面对挑战或恶意用户时保持自我认同。